https://docs.microsoft.com/es-mx/learn/modules/explore-core-data-concepts/
Unidad 1: Introducción
Durante las últimas décadas, la cantidad de datos que generan los sistemas, las aplicaciones y los dispositivos ha aumentado considerablemente. Los datos están en todas partes, en una gran variedad de estructuras y formatos.
Ahora los datos pueden recopilarse de manera más fácil y almacenarse de forma más barata, lo que permite que casi todas las empresas puedan tener acceso a ellos. Las soluciones de datos incluyen tecnologías de software y plataformas que pueden facilitar la recopilación, el análisis y el almacenamiento de información valiosa. Todas las empresas buscan aumentar sus ingresos y obtener mayores ganancias. En este mercado competitivo, los datos son un recurso valioso. Cuando se analizan correctamente, los datos se pueden convertir en una gran cantidad de información útil que ayuda a tomar decisiones empresariales críticas.
La capacidad de capturar, almacenar y analizar datos es un requisito básico para todas las organizaciones del mundo. En este módulo, obtendrá información sobre las opciones para representar y almacenar datos, así como sobre las cargas de trabajo de datos típicas. Al completar este módulo, establecerá las bases para conocer mejor las técnicas y los servicios que se usan para trabajar con datos.
Unidad 2: Identificación de los formatos de datos
Los datos son una colección de elementos, como números, descripciones y observaciones, que se usan para registrar información. Las estructuras de datos en las que se organizan estos datos suelen representar entidades que son importantes para una organización (como clientes, productos, pedidos de ventas, etc.). Normalmente, cada entidad tiene uno o varios atributos o características (por ejemplo, un cliente podría tener un nombre, una dirección, un número de teléfono, etc.).
Los datos se pueden clasificar en estructurados, semiestructurados o no estructurados.
Datos estructurados
Los datos estructurados son aquellos que se ajustan a un esquema fijo, por lo que todos los datos tienen los mismos campos o propiedades. Normalmente, el esquema de las entidades de datos estructurados es tabular; es decir, los datos se representan en una o varias tablas que constan de filas para representar cada instancia de una entidad de datos y columnas para representar los atributos de la entidad. Por ejemplo, en la imagen siguiente se muestran las representaciones de datos tabulares para las entidades Customer y Product.
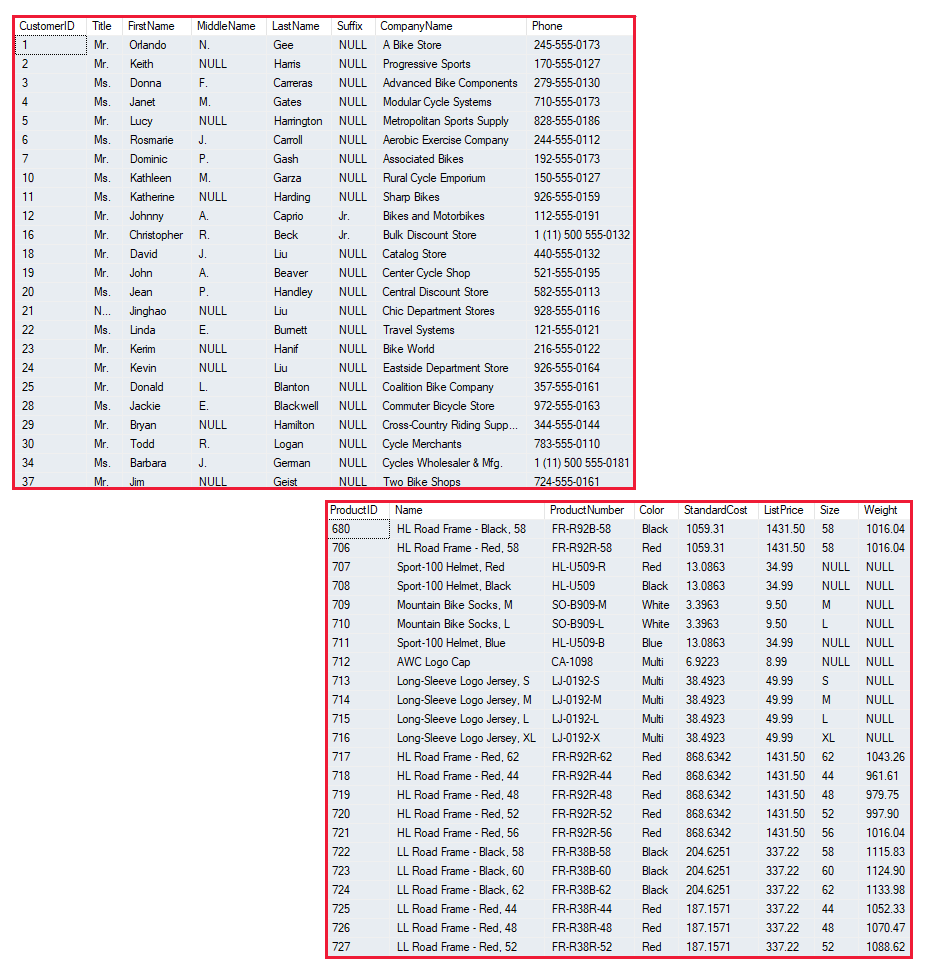
Los datos estructurados suelen almacenarse en una base de datos en la que varias tablas pueden hacer referencia entre sí mediante el uso de valores de clave en un modelo relacional, que exploraremos con más detalle más adelante.
Datos semiestructurados
Los datos semiestructurados son información que tiene cierta estructura, pero que permite alguna variación entre las instancias de entidad. Por ejemplo, aunque la mayoría de los clientes pueden tener una dirección de correo electrónico, algunos podrían tener varias y otros, ninguna.
Un formato común para los datos semiestructurados es la notación de objetos JavaScript (JSON). En el ejemplo siguiente se muestran un par de documentos JSON que representan información de clientes. Cada documento de cliente incluye la dirección y la información de contacto, pero los campos específicos varían entre los clientes.
// Customer 1
{
"firstName": "Joe",
"lastName": "Jones",
"address":
{
"streetAddress": "1 Main St.",
"city": "New York",
"state": "NY",
"postalCode": "10099"
},
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
}
// Customer 2
{
"firstName": "Samir",
"lastName": "Nadoy",
"address":
{
"streetAddress": "123 Elm Pl.",
"unit": "500",
"city": "Seattle",
"state": "WA",
"postalCode": "98999"
},
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}Nota: JSON es solo una de las muchas maneras en las que se pueden representar los datos semiestructurados. Lo importante aquí no es proporcionar un examen detallado de la sintaxis de JSON, sino ilustrar la naturaleza flexible de las representaciones de datos semiestructurados.
Datos no estructurados
No todos los datos están estructurados o semiestructurados. Por ejemplo, los documentos, imágenes, datos de audio y de vídeo y archivos binarios podrían no tener una estructura específica. Este tipo de datos se conoce como datos no estructurados.

Almacenes de datos
Las organizaciones suelen almacenar los datos en formato estructurado, semiestructurado o no estructurado para registrar los detalles de entidades (por ejemplo, clientes y productos), eventos específicos (como transacciones de ventas) u otra información en documentos, imágenes y otros formatos. Los datos almacenados se pueden recuperar para su análisis y la generación de informes más adelante.
Habitualmente se usan dos categorías generales de almacén de datos:
- Almacenes de archivos
- Bases de datos
MCT: Video 1.1.1: Introducción a las bases de datos
Datos e Información
- Datos e información no son lo mismo
- Los datos son símbolos como números, letras o signos que son empleados para representar a través de un lenguaje un hecho, una condición, un valor, una cantidad,etc
- La información es el resultado ejecutar un procesamiento a un conjunto de datos dándole u significado o interpretación
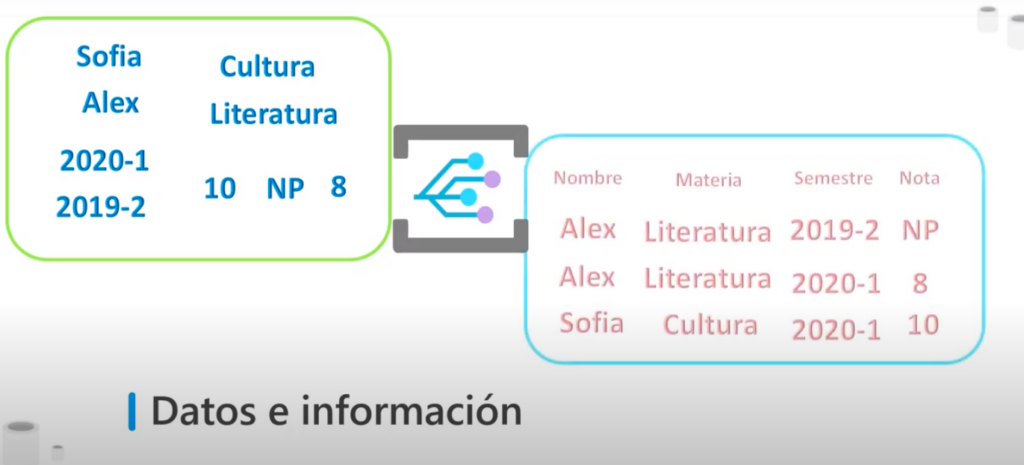
- Por ejemplo en los datos podemos tener los siguientes números y caracteres sin una organización específica aunque para nosotros pueden tener una lógica carecen de contexto
- Una vez que les damos contexto podemos determinar que los datos pertenecen a información alumnos y asignaturas
Tipos de datos
- Los datos se pueden clasificar según su tipo:
- Estructurados
- Semiestructurados
- No Estructurados

Estructurados
- Suelen ser datos tabulares que se representan mediante filas y columnas en una base de datos, es usual encontrar este tipo de datos en hojas de cálculo y cuentan con cierta organización, aunque utilizar este software como medio de almacenamiento reduce el potencial de los datos ya que no se pueden automatizar o realizar consultas complejas
- Las bases de datos que contienen tablas de este tipo se denominan BD relacionales
- Un servicio de Azure de este tipo es Azure SQL Database
Semiestructurados
- Son información que no que no residen en una BD relacional pero que contienen cierta estructura
- Por ejemplo un documento JSON

- Este tipo de documento permite almacenar datos de una manera más flexible ya que se pueden guardar datos distintos para cada registro
- Por ejemplo puede que un alumno tenga o no teléfono
- La estructura de un documento JSON se establece de la siguiente manera
- «EstudianteID»: se le conoce como objeto raíz y contiene toda la información de este documento JSON
- «Datos Personales»: es un objeto anidado
- «Asignaturas»: es una matriz anidada
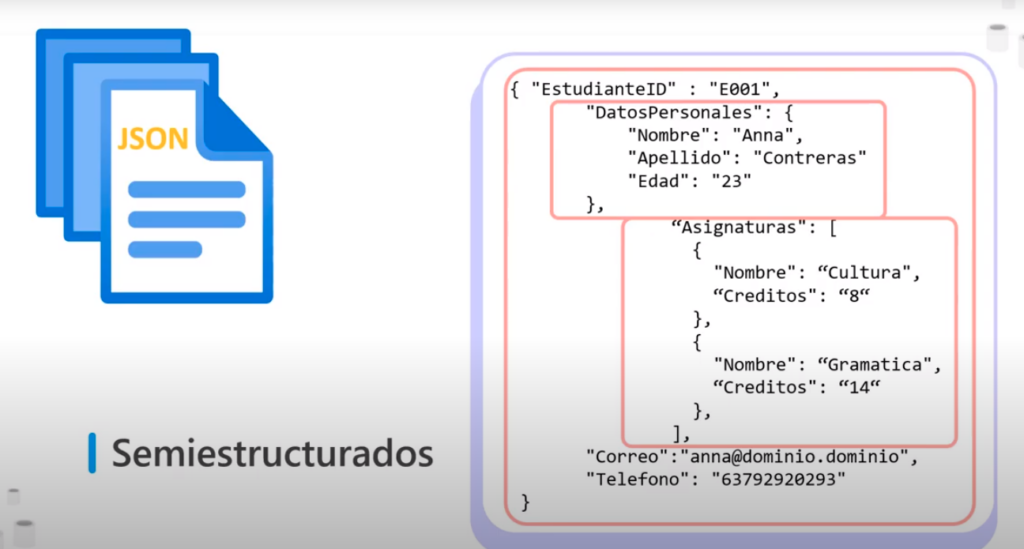
- Existen cierto servicios que nos permiten almacenar Azure Cosmos DB permite almacenar este tipo de documentos
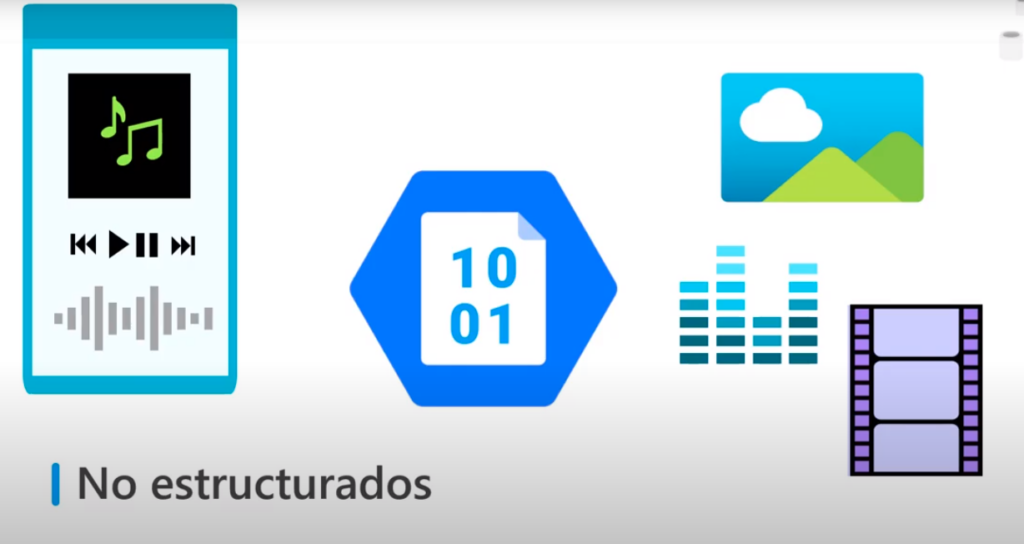
No estructurados
- Son datos que no cuentan con ningún tipo de estructura. Por ejemplo: archivos multimedia (audio, imágenes y vídeo)
- Se encuentran normalmente en plataformas de streamming
- Por ejemplo en una aplicación que reproduce música las canciones no son un datos estructural y se pueden representar en un formato JSON , sin embargo se deben poder almacenar en algún lugar pero no se modifican solo se consultan
- Azure Blob Storage es un servicio que permite almacenar este tipo de datos
Diseño de Bases de Datos
- Para crear una base de datos debemos utilizar algunas herramientas que nos ayudarán a modelar la estructura y funcionamiento de nuestra base
- Para crear una BD se debe seguir el siguiente procedimiento secuencial
Diseño Conceptual:
- Es construir un modelo llamado Entidad-Relación
- Por ejemplo tenemos la entidad «Producto» con los atributos: Identificador / Cantidad / Descripción
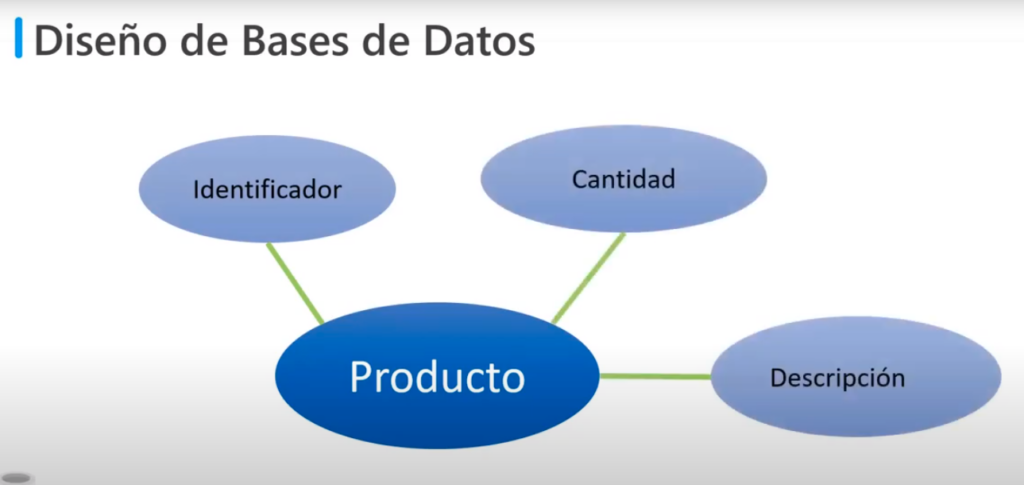
- Y normalmente una BD esta constituida por más de una entidad que se relacionan entre sí por un contexto
- Este modelo es independiente del sistema de administración de BD (DBMS) donde se va a implementar y no requiere conocimientos técnicos para ser interpretado
Diseño Lógico
- Es la transformación del diseño conceptual y la base del modelo relacional
- Es una forma estándar de representar las entidades, sus relaciones y los detalles técnicos de estas
- Por ejemplos características de los atributos, relaciones de los datos y los tipos de relaciones entre las entidades
- Este también es independiente al (DBMS) en que se va a implementar la BD
Diseño físico
- Se crea a partir del diseño lógico y la información del uso esperado de la BD, que se refiere al:
- Volumen de datos
- Transformaciones que el sistema deberá procesar
- Frecuencia de uso
- Calidad del servicio esperada
- Con esta información se definen las características y configuraciones físicas y lógicas que la BD deberá tener

Clasificación de BD
- Las BD de pueden clasificar de distintas formas, una es de acuerdo a su uso
Por uso
OLTP
- OLTP: Online Transsaccion Processing
- Utilizada para realizar transacciones (cambios constantes en los datos)
- Un ejemplo es un sistema bancario ya que constantemente se realizan como aumento y disminución de saldos
- Azure SQL Database es de tipo OLTP

OLAP
- OLAP: Online Analytical Processing
- Normalmente utilizada para el análisis ya que por lo general los datos almacenados permanecen estáticos y sin cambios

- Por ejemplo: sistema de respaldos que guarda datos históricos, los cuales pueden ser consultados para generar gráficas o informes
- Azure table Storage nos permite utilizar este servicio

Tipos de Análisis
- Realizar una mejor toma de decisiones ayuda a alcanzar una mayor grado de eficiencia y reducir costos, esto se puede lograr por medio del análisis que se divide de la siguiente manera

Análisis Descriptivo
- Responde a: ¿Qué esta pasando?
- Toma los datos in procesar y proporciona información valiosa sobre el pasado
- Estos solo indican si algo esta bien o mal
- Por ejemplo: con base en los datos del último vez se puede ver que los ciberataques aumentaron 47% con respecto al mes anterior
Análisis Diagnóstico
- Responde a: ¿Por qué está pasando?
- Es decir explica algún suceso
- Los datos históricos pueden comenzar a medirse con otros datos para responder a la pregunta por que sucedió algo en el pasado
- Es el proceso de recopilar e interpretar diferentes conjuntos de datos para identificar anomalías, detectar patrones y determinar relaciones
- Por ejemplo: con ayuda de los datos históricos se puede determinar que hubo un periodo de actualizaciones en los equipos de computo que no se realizó

Análisis Predictivo
- Responde a: ¿Qué pasará?
- Es una categoría de inteligencia empresarial (Business Intelligence)
- Que utiliza variables descriptivas y predictivas del pasado para analizar e identificar la probabilidad de un resultado futuro
- Por ejemplo: si no se actualizan los equipos los ciberataques continuarán aumentando
Análisis Prescriptivo
- Responde a: ¿Qué se debe realizar?
- Es una combinación de datos, modelos matemáticos y reglas comerciales para determinar las acciones que influyan en los resultados futuros deseados
- Por ejemplo: es necesario realizar la actualización y crear un mecanismo de alertas que evite que este suceso vuelva a ocurrir
Análisis Cognitivo
- Puede ayudarnos a automatizar o mejorar procesos, ya que reúne tecnologías inteligentes
- Aplicando semántica, algoritmos de Inteligencia artificial y técnicas de aprendizaje como el aprendizaje profundo y automático
- Por ejemplo: con este análisis se podrían detectar amenazas en la red casi de manera inmediata al registrar algún comportamiento inusual incluso se podría ejecutar acciones correctivas evitando perder tiempo que es crucial en temas de seguridad
Unidad 3: Exploración del almacenamiento de archivos
La capacidad de almacenar datos en archivos es un elemento básico de cualquier sistema informático. Los archivos se pueden almacenar en sistemas de archivos locales en el disco duro del equipo personal y en medios extraíbles, como unidades USB, pero en la mayoría de las organizaciones los archivos de datos importantes se almacenan centralmente en algún tipo de sistema de almacenamiento de archivos compartido. Cada vez más, esa ubicación de almacenamiento central se hospeda en la nube, lo que permite un almacenamiento rentable, seguro y de confianza para grandes volúmenes de datos.
El formato de archivo específico que se usa para almacenar datos depende de una serie de factores, entre los que se incluyen los siguientes:
- El tipo de datos que se almacenan (estructurados, semiestructurados o no estructurados).
- Las aplicaciones y los servicios que tendrán que leer, escribir y procesar los datos.
- La necesidad de que los archivos de datos sean legibles para los usuarios o estén optimizados para un almacenamiento y procesamiento eficientes.
A continuación se describen algunos formatos de archivo comunes.
Archivos de texto delimitado
A menudo, los datos se almacenan como texto sin formato con delimitadores de campo y terminadores de fila específicos. El formato más común para los datos delimitados son los valores separados por comas (CSV), en los que los campos están separados por comas y las filas finalizan con un retorno de carro o una nueva línea. Opcionalmente, la primera línea puede incluir los nombres de campo. Otros formatos comunes incluyen valores separados por tabulaciones (TSV) y delimitados por espacios (en los que se usan tabulaciones o espacios para separar los campos), así como datos de ancho fijo en los que a cada campo se le asigna un número fijo de caracteres. El texto delimitado es una buena opción para los datos estructurados a los que necesita tener acceso una amplia gama de aplicaciones y servicios en un formato legible.
En el ejemplo siguiente se muestran los datos de clientes en formato delimitado por comas:
FirstName,LastName,Email
Joe,Jones,joe@litware.com
Samir,Nadoy,samir@northwind.comNotación de objetos JavaScript (JSON)
JSON es un formato omnipresente en el que se usa un esquema de documento jerárquico para definir entidades de datos (objetos) que tienen varios atributos. Cada atributo puede ser un objeto (o una colección de objetos ), lo que hace de JSON un formato flexible adecuado tanto para datos estructurados como semiestructurados.
En el ejemplo siguiente se muestra un documento JSON que contiene una colección de clientes. Cada cliente tiene tres atributos (firstName, lastName y contact) y el atributo contact contiene una colección de objetos que representan uno o varios métodos de contacto (correo electrónico o teléfono). Tenga en cuenta que los objetos se incluyen entre llaves ({..}) y las colecciones se incluyen entre corchetes ([..]). Los atributos se representan mediante pares nombre:valor y se separan por comas (,).
{
"customers":
[
{
"firstName": "Joe",
"lastName": "Jones",
"contact":
[
{
"type": "home",
"number": "555 123-1234"
},
{
"type": "email",
"address": "joe@litware.com"
}
]
},
{
"firstName": "Samir",
"lastName": "Nadoy",
"contact":
[
{
"type": "email",
"address": "samir@northwind.com"
}
]
}
]
}Lenguaje de marcado extensible (XML)
XML es un formato de datos legible popular en la década de 1990 y 2000. En gran medida lo ha reemplazado el formato JSON, menos detallado, pero todavía hay algunos sistemas que usan XML para representar datos. XML usa etiquetas entre corchetes angulares (../) para definir elementos y atributos, como se muestra en este ejemplo:
<Customers>
<Customer name="Joe" lastName="Jones">
<ContactDetails>
<Contact type="home" number="555 123-1234"/>
<Contact type="email" address="joe@litware.com"/>
</ContactDetails>
</Customer>
<Customer name="Samir" lastName="Nadoy">
<ContactDetails>
<Contact type="email" address="samir@northwind.com"/>
</ContactDetails>
</Customer>
</Customers>Objeto binario grande (BLOB)
En última instancia, todos los archivos se almacenan como datos binarios (1 y 0), pero en los formatos legibles que se describen anteriormente, los bytes de datos binarios se asignan a caracteres imprimibles (normalmente a través de un esquema de codificación de caracteres como ASCII o Unicode). Aun así, algunos formatos de archivo, especialmente para los datos no estructurados, almacenan los datos como datos binarios sin formato que las aplicaciones deben interpretar y representar. Los tipos comunes de datos almacenados como datos binarios incluyen imágenes, vídeo, audio y documentos específicos de aplicaciones.
Cuando trabajan con datos de este tipo, los profesionales de datos suelen hacer referencia a estos archivos de datos como BLOB (objetos binarios grandes).
Formatos de archivo optimizados
Aunque los formatos legibles para datos estructurados y semiestructurados pueden ser útiles, normalmente no están optimizados para el procesamiento o el espacio de almacenamiento. Con el paso del tiempo, se han desarrollado algunos formatos de archivo especializados que permiten la compresión, la indexación y un almacenamiento y procesamiento eficientes.
Entre los formatos de archivo optimizados más habituales que puede ver se incluyen Avro, ORC y Parquet:
- Avro es un formato basado en filas creado por Apache. Cada registro contiene un encabezado que describe la estructura de los datos en ese registro. Este encabezado se almacena como JSON. Los datos, por su parte, se almacenan como información binaria. Una aplicación usa la información del encabezado para analizar los datos binarios y extraer los campos que contienen. Avro es un formato adecuado para comprimir datos y reducir los requisitos de almacenamiento y ancho de banda de red.
- ORC (formato de columnas de filas optimizadas) organiza los datos en columnas en lugar de en filas. Lo desarrolló HortonWorks para optimizar las operaciones de lectura y escritura en Apache Hive (Hive es un sistema de almacenamiento de datos que admite resúmenes de datos rápidos y consultas en grandes conjuntos de datos). Un archivo ORC contiene franjas de datos. Cada franja contiene los datos de una columna o de un conjunto de columnas. Una franja contiene un índice de las filas de dicha franja, los datos de cada fila y un pie de página que contiene información estadística (count, sum, max, min, etc.) de cada columna.
- Parquet es otro formato de datos en columnas creado por Cloudera y Twitter. Un archivo Parquet contiene grupos de filas. Los datos de cada columna se almacenan juntos en el mismo grupo de filas. Cada grupo de filas contiene uno o varios fragmentos de datos. Un archivo Parquet incluye metadatos que describen el conjunto de filas que hay en cada fragmento. Una aplicación puede usar estos metadatos para localizar rápidamente el fragmento correcto para un conjunto determinado de filas y, a continuación, para recuperar los datos de las columnas especificadas relativos a esas filas. Parquet destaca por almacenar y procesar tipos de datos anidados de forma eficaz. Admite esquemas de compresión y codificación muy eficaces.
Unidad 4: Exploración de bases de datos
Las bases de datos se usan para definir un sistema central en el que los datos se pueden almacenar y consultar. En un sentido simplista, el sistema de archivos en el que se almacenan los archivos es un tipo de base de datos; pero cuando usamos el término en un contexto de datos profesional, normalmente nos referimos a un sistema dedicado para administrar registros de datos en lugar de archivos.
Bases de datos relacionales
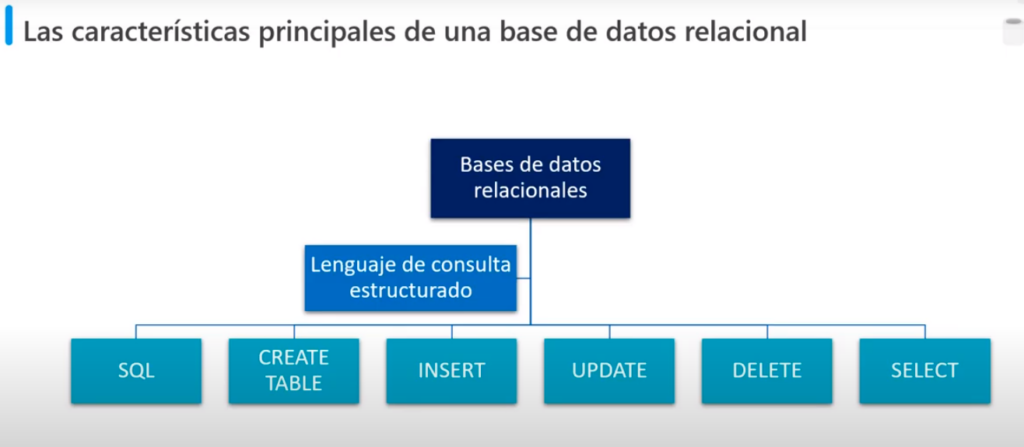
Las bases de datos relacionales suelen usarse para almacenar y consultar datos estructurados. Los datos se almacenan en tablas que representan entidades, por ejemplo, clientes, productos o pedidos de ventas. A cada instancia de una entidad se le asigna una clave principal que la identifica de forma única; estas claves se usan para hacer referencia a la instancia de entidad en otras tablas. Por ejemplo, se puede hacer referencia a la clave principal de un cliente en un registro de pedidos de ventas para indicar qué cliente ha realizado el pedido. Este uso de claves para hacer referencia a entidades de datos permite normalizar una base de datos relacional. En parte, esto conlleva la eliminación de valores de datos duplicados para que, por ejemplo, los detalles de un cliente individual se almacenen una sola vez, no para cada pedido de ventas que realiza el cliente. Las tablas se administran y consultan mediante el Lenguaje de consulta estructurado (SQL), que se basa en un estándar ANSII, por lo que es similar en varios sistemas de base de datos.
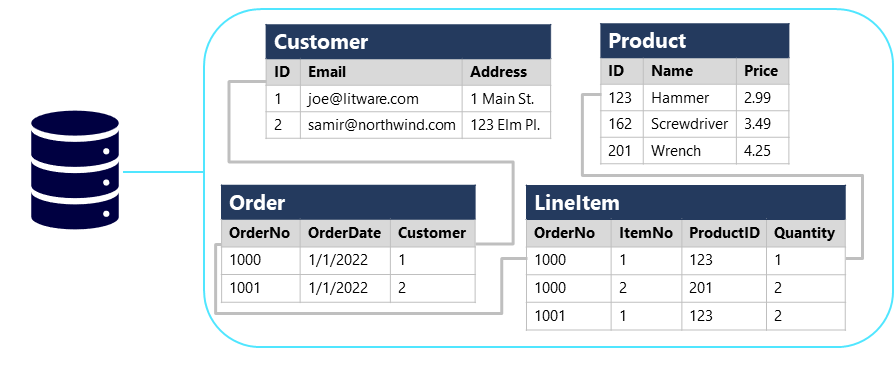
Bases de datos no relacionales
Las bases de datos no relacionales son sistemas de administración de datos que no aplican un esquema relacional a los datos. Las bases de datos no relacionales suelen conocerse como bases de datos NoSQL, aunque algunas admiten una variante del lenguaje SQL.
Hay cuatro tipos comunes de bases de datos no relacionales que se usan habitualmente.
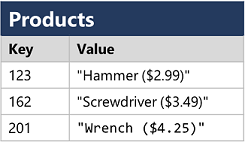
- Bases de datos de clave-valor, en las que cada registro consta de una clave única y un valor asociado, que puede estar en cualquier formato.
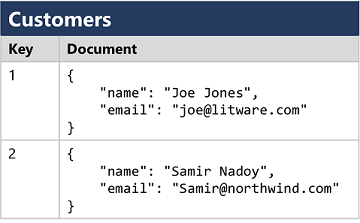
- Bases de datos de documentos, que son una forma específica de base de datos de clave-valor, en la que el valor es un documento JSON (que el sistema está optimizado para analizar y consultar).
- Bases de datos de familia de columnas, que almacenan datos tabulares con filas y columnas, pero con la posibilidad de dividir esas columnas en grupos, conocidos como familias de columnas. Cada familia de columnas contiene un conjunto de columnas que tienen una relación lógica entre sí.

- Bases de datos de grafos, que almacenan entidades como nodos con vínculos para definir relaciones entre ellas.
Unidad 5: Exploración del procesamiento de datos transaccionales
Un sistema de procesamiento de datos transaccional es lo que la mayoría de los usuarios considera la función principal de la informática empresarial. Un sistema transaccional registra las transacciones que encapsulan eventos específicos de los que la organización quiere realizar un seguimiento. Una transacción podría ser financiera, como el movimiento de dinero entre cuentas de un sistema bancario, o bien podría formar parte de un sistema de venta al por menor y llevar un seguimiento de los pagos de bienes y servicios de los clientes. Piense en una transacción como una unidad de trabajo pequeña y discreta.
Los sistemas transaccionales suelen ser de gran volumen; a veces, controlan muchos millones de transacciones en un solo día. Se debe poder acceder a los datos que se procesan con mucha rapidez. El trabajo que realizan los sistemas transaccionales a menudo se conoce como procesamiento de transacciones en línea (OLTP).
Las soluciones OLTP se basan en un sistema de base de datos en el que el almacenamiento de datos está optimizado tanto para las operaciones de lectura como para las de escritura, con el fin de admitir cargas de trabajo transaccionales en las que se crean, recuperan, actualizan y eliminan registros de datos (a menudo denominadas operaciones CRUD). Estas operaciones se aplican transaccionalmente, de una forma que garantiza la integridad de los datos almacenados en la base de datos. Para ello, los sistemas OLTP aplican transacciones que admiten la denominada semántica ACID:
- Atomicidad: cada transacción se trata como una unidad única, la cual se completa correctamente o produce un error general. Por ejemplo, una transacción que conlleve el adeudo de fondos de una cuenta y el abono de la misma cantidad en otra debe completar ambas acciones. Si alguna de las acciones no se puede completar, se debe producir un error en la otra.
- Coherencia: las transacciones solo pueden pasar los datos de la base de datos de un estado válido a otro. Para continuar con el ejemplo anterior del adeudo y el abono, el estado completado de la transacción debe reflejar la transferencia de fondos de una cuenta a la otra.
- Aislamiento: las transacciones simultáneas no pueden interferir entre sí y deben dar lugar a un estado coherente de la base de datos. Por ejemplo, mientras la transacción para transferir fondos de una cuenta a otra está en proceso, otra transacción que comprueba el saldo de las cuentas debe devolver resultados coherentes. Es decir, la transacción de comprobación del saldo no puede recuperar un valor para una cuenta que refleje el saldo antes de la transferencia y un valor para la otra cuenta que refleje el saldo después de la transferencia.
- Durabilidad: cuando se ha confirmado una transacción, permanece confirmada. Una vez que la transacción de transferencia de la cuenta se ha completado, los saldos revisados de las cuentas se conservan, de modo que, incluso si el sistema de base de datos se desactiva, la transacción confirmada se refleje cuando se vuelva a activar.
Los sistemas OLTP suelen usarse para admitir aplicaciones activas que procesan datos empresariales, a menudo denominadas aplicaciones de línea de negocio (LOB).
Unidad 6: Exploración del procesamiento de datos analíticos
Normalmente, el procesamiento de datos analíticos usa sistemas de solo lectura (o principalmente de lectura) que almacenan grandes volúmenes de datos históricos o métricas empresariales. Los análisis pueden basarse en una instantánea de los datos en un momento concreto o en una serie de instantáneas.
Los detalles específicos de un sistema de procesamiento analítico pueden variar según la solución, pero una arquitectura común para el análisis a escala empresarial tiene el siguiente aspecto:
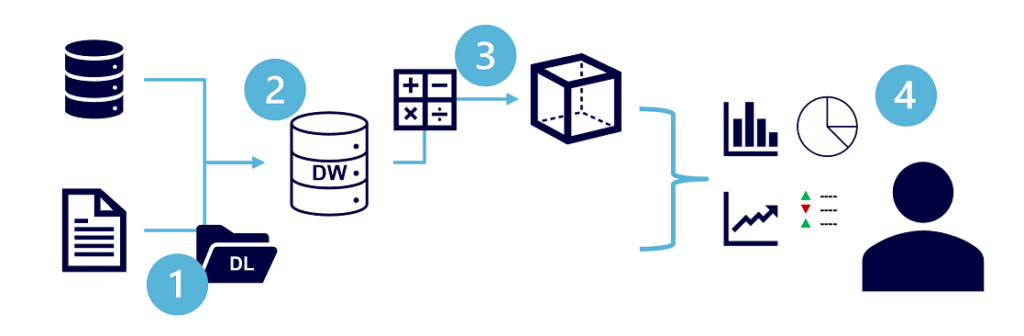
- Los archivos de datos se pueden almacenar en un lago de datos central para analizarlos.
- Un proceso de extracción, transformación y carga (ETL) permite copiar datos de archivos y bases de datos OLTP en un almacenamiento de datos optimizado para la actividad de lectura. Normalmente, un esquema de almacenamiento de datos se basa en tablas de hechos que contienen valores numéricos que quiere analizar (por ejemplo, importes de ventas), con tablas de dimensiones relacionadas que representan las entidades por las que quiere medirlas (por ejemplo, cliente o producto).
- Los datos del almacenamiento de datos se pueden agregar y cargar en un modelo de procesamiento analítico en línea (OLAP) o un cubo. Los valores numéricos agregados (medidas) de las tablas de hechos se calculan para intersecciones de dimensiones a partir de tablas de dimensiones. Por ejemplo, los ingresos de ventas podrían sumarse por fecha, cliente y producto.
- Los datos del lago de datos, el almacenamiento de datos y el modelo analítico se pueden consultar para generar informes, visualizaciones y paneles.
Los lagos de datos son comunes en escenarios de procesamiento analítico de datos modernos, en los que se debe recopilar y analizar un gran volumen de datos basados en archivos.
Los almacenamientos de datos son un recurso establecido para almacenar datos en un esquema relacional optimizado para operaciones de lectura, principalmente consultas para admitir informes y visualización de datos. El esquema de almacenamiento de datos puede requerir alguna desnormalización de los datos en un origen de datos OLTP (que introduce cierta duplicación para que las consultas se lleven a cabo con mayor rapidez).
Un modelo OLAP es un tipo agregado de almacenamiento de datos optimizado para cargas de trabajo analíticas. Las agregaciones de datos se encuentran en diferentes dimensiones y distintos niveles, lo que permite rastrear agrupando datos y explorar en profundidad las agregaciones en varios niveles jerárquicos; por ejemplo, para buscar el total de ventas por región, por ciudad o por una dirección individual. Dado que los datos de OLAP se agregan previamente, las consultas para devolver los resúmenes que contiene se pueden ejecutar rápidamente.
Los diferentes tipos de usuario pueden llevar a cabo el trabajo analítico de datos en distintas fases de la arquitectura general. Por ejemplo:
- Los científicos de datos pueden trabajar directamente con archivos de datos en un lago de datos para explorar los datos y crear modelos a partir de estos.
- Los analistas de datos pueden consultar tablas directamente en el almacenamiento de datos para generar informes y visualizaciones complejos.
- Los usuarios profesionales pueden consumir datos agregados previamente en un modelo analítico como informes o paneles.
MCT: Video 1.1.2: Descripción de los datos por lotes (Batch Data)
Datos por lotes (Batch Data)
- Es un método de ejecución de tareas repetitivas, de gran volumen que permite a los usuarios procesar datos cuando se disponga de recursos informáticos con poco o nula interacción del usuario
- Use Azure Batch para ejecutar aplicaciones de informática de alto rendimiento (HPC) en paralelo y a gran escala, de manera eficaz en Azure.
- Azure Batch permite crear y administrar un conjunto de nodos de proceso (máquinas virtuales), instalar las aplicaciones que desea ejecutar y programar trabajos para que se ejecuten en los nodos.
- Los desarrolladores pueden usar Batch como un servicio de plataforma para compilar aplicaciones SaaS o aplicaciones cliente en las que se requiere una ejecución a gran escala.
- Por ejemplo, puede compilar un servicio con Batch para que ejecute una simulación de riesgo Monte Carlo para una empresa de servicios financieros o un servicio que procese muchas imágenes.
- Batch funciona bien con cargas de trabajo intrínsecamente paralelas (a veces llamadas «embarazosamente paralelas»).
- Estas cargas de trabajo tienen aplicaciones que se pueden ejecutar de manera independiente y donde cada instancia completa una parte del trabajo.
A continuación puede ver algunos ejemplos de cargas de trabajo intrínsecamente paralelas con las que puede trabajar en Batch:
- Modelado de riesgos financieros mediante simulaciones Monte Carlo
- Representación de imágenes VFX y 3D
- Análisis y procesamiento de imágenes
- Transcodificación de elementos multimedia
- Análisis de secuencia genética
- Reconocimiento óptico de caracteres (OCR)
- Ingesta, procesamiento, extracción, transformación y carga de datos
- Ejecución de pruebas de software
También puede usar Batch para ejecutar cargas de trabajo estrechamente acopladas donde las aplicaciones que se ejecutan necesitan comunicarse entre sí, en lugar de hacerlo de forma independiente. Las aplicaciones estrechamente acopladas normalmente utilizan Message Passing Interface (MPI) API. Puede ejecutar cargas de trabajo estrechamente acopladas con Batch mediante Microsoft MPI o Intel MPI. Mejore el rendimiento de la aplicación con informática de alto rendimiento especializada y tamaños de máquina virtual optimizados para GPU.
Estos son algunos ejemplos de cargas de trabajo estrechamente acopladas:
- Análisis de elementos finitos
- Dinámica de fluidos
- Aprendizaje de inteligencia artificial multinodo
Batch admite cargas de trabajo de representación a gran escala con herramientas de representación que incluyen Autodesk Maya, 3ds Max, Arnold, y V-Ray.
Azure Batch también se puede ejecutar como parte de un flujo de trabajo mayor de Azure para transformar datos, administrado mediante herramientas como Azure Data Factory.
El siguiente diagrama muestra los pasos de un flujo de trabajo común de Batch, con una aplicación cliente o un servicio hospedado usando Batch para ejecutar una carga de trabajo paralela.
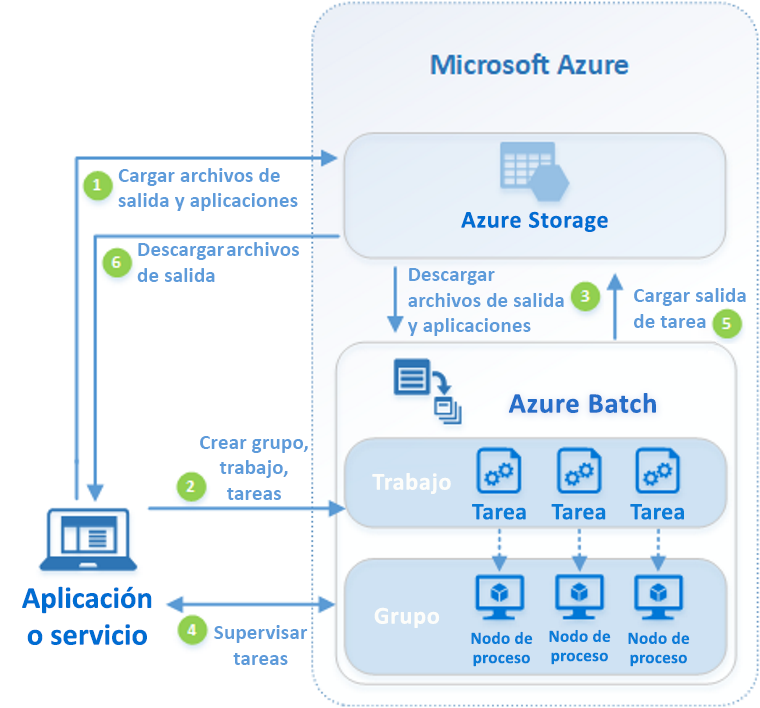
Parámetros esenciales
- Quien envía la tarea
- Que programa se ejecutará
- Ubicación de archivos de entrada y salida
- Cuando se debe ejecutar la tarea

Tipos de datos y su almacenamiento
- Los datos se pueden clasificar de muchas maneras diferentes entre ellas:
- Como están estructurados
- Y como se usan

Características de los datos relacionales y no relacionales
- Las BD relacionales proporcionan el modelo de BD más sencillo de almacenamiento de datos
- Las estructura de filas y columnas facilitan el uso inicial, sin embargo esta forma puede provocar errores en como se relacionan los datos
- Por ejemplo que pasa si un cliente tiene más de una tarjeta de crédito para realizar los pagos
- Estos problemas se pueden resolver con la normalización, que hace que los datos se dividan en un gran nuevo de tablas, con pocas columnas y bien definidas
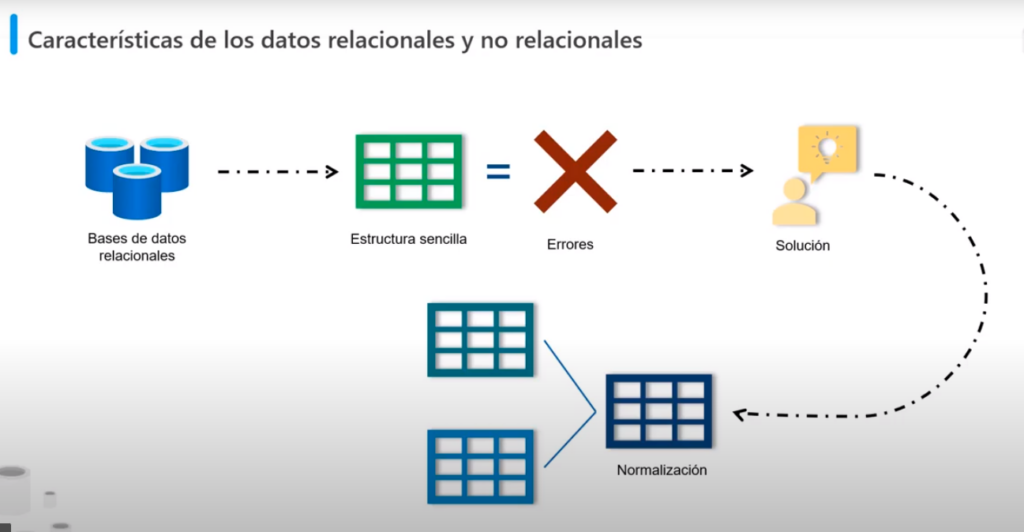
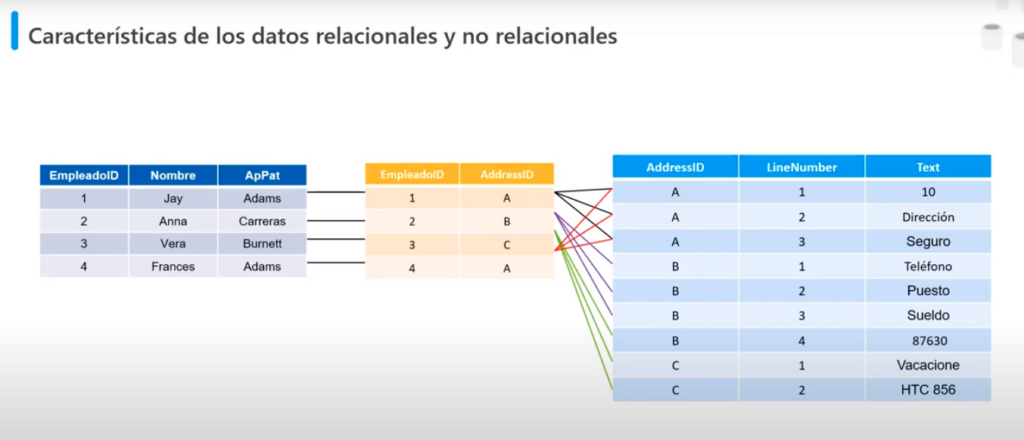
- Las bases de datos no relacionales permiten almacenar los datos en un formato que coincide más con la estructura original
- Si dos clientes tienen la misma dirección en una BD relacional solo se almacena la dirección una única vez, pero en una BD no relacional o de documentos la dirección se duplicará, esto aumenta el tamaño del almacenamiento y hará que el mantenimiento de los datos sea más complejo ya que si la dirección cambia se debe modificar en 2 documentos
Cargas de trabajo transaccionales
- Una transacción es una secuencia de operaciones atómicas
- Esto significa que todas las operaciones de la secuencia se deben completar correctamente
- O si ocurre un error se deben revertir todas las operaciones
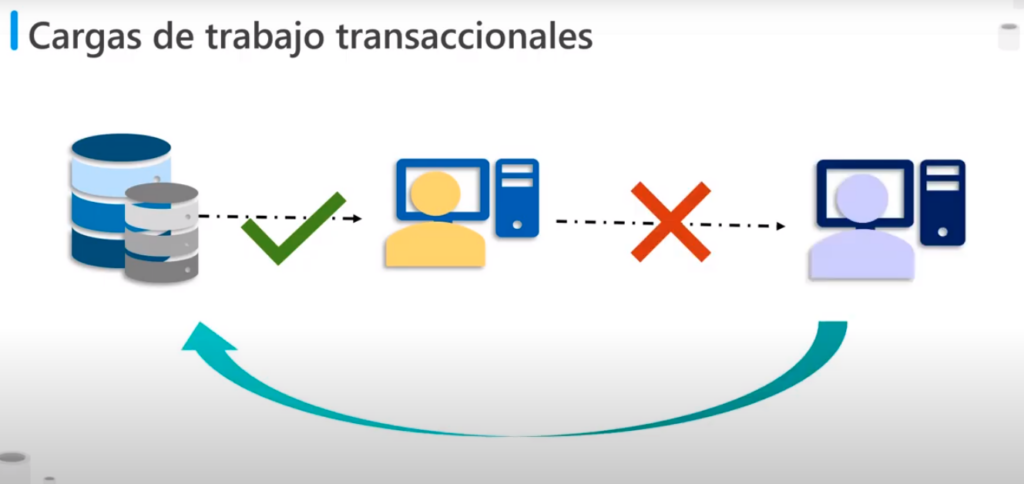
- Cada transacción de BD tiene un punto inicial definido, seguidos de los pasos para modificar los datos de la BD
- Al final BD confirma los cambios para que estos sean permanentes o los revierte al punto inicial

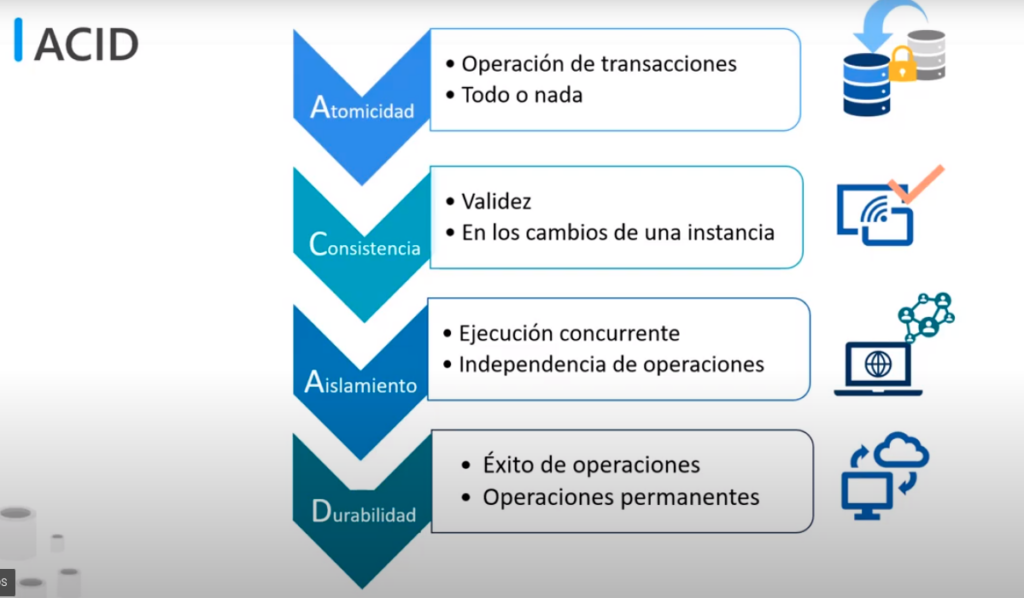
ACID
- Una BD transaccional tiene las propiedades ACID, para garantizar que la BD sigue siendo coherente mientras se procesan las transacciones
- Atomicidad: garantiza que cada transacción se trata como una unidad única, donde se completa correctamente o produce un error
- Coherencia: garantiza que una transacción solo puede pasar de un estado valido a otro
- Aislamiento: garantiza que la ejecución simultanea de transacciones deja la BD como si estas se ejecutarán de manera secuencial
- Durabilidad: garantiza que una vez confirmada la transacción permanecerá confirmada incluso se se produce un error en el sistema
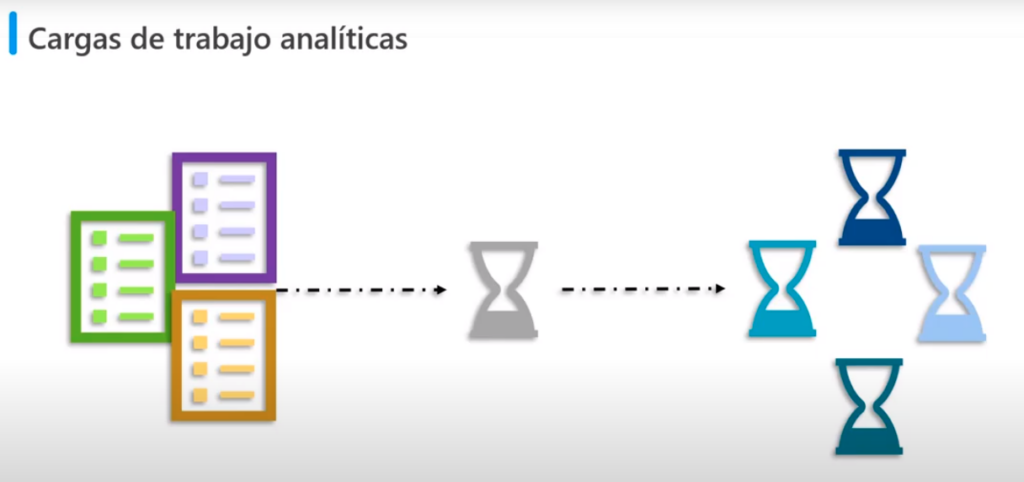
Cargas de trabajo analíticas
- Son sistemas de solo lectura
- Que almacenan grandes volúmenes de datos históricos o de métricas empresariales
- Por ejemplo: Rendimientos de ventas o niveles de inventario
- Se utilizan para analizar datos y tomar decisiones
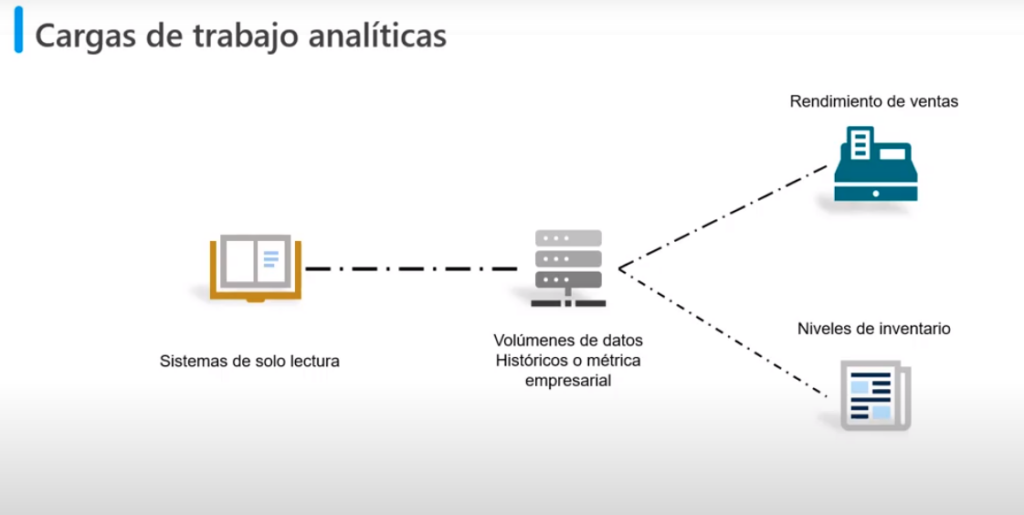
- Los análisis pueden basarse en una instancia de los datos en un momento específico, o en una serie de instancias
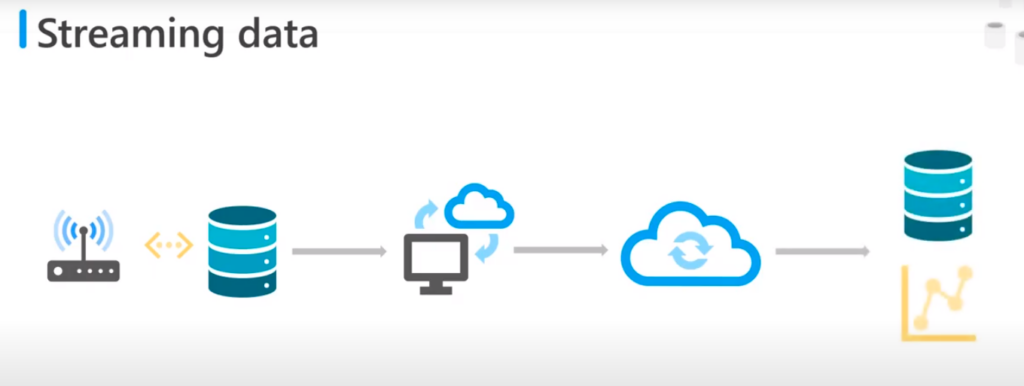
MCT: Video 1.1.3: Descripción de Streaming Data
Streaming data
- Los sistemas de streaming poseen una arquitectura orientada a manejar eventos individualmente, para que los datos de puedan procesar tan pronto como se genera el evento
- Los casos de uso:
- Donde se requiere respuesta activa de los usuarios tan pronto ocurran los eventos
- Por ejemplo: el monitoreo de datos provenientes de sensores, redes sociales, servidores, aplicaciones, etc
- Esta arquitectura puede tener problemas de accesibilidad y calidad de datos
¿Qué es Streaming?
- Es la tecnología de transmisión de datos por Internet que pueden ser accedidos por los usuarios sin la necesidad de la descarga previa
- La carga del contenido publicado en este formato se realiza mientras el archivo esta siendo accedido, lo que disminuye el tiempo de espera de los usuarios, permitiendo el acceso casi instantáneo
- Con streaming se puede transmitir contenido en vivo o grabados anteriormente, sin que los datos tengan que ser almacenados en computadoras u otro dispositivo

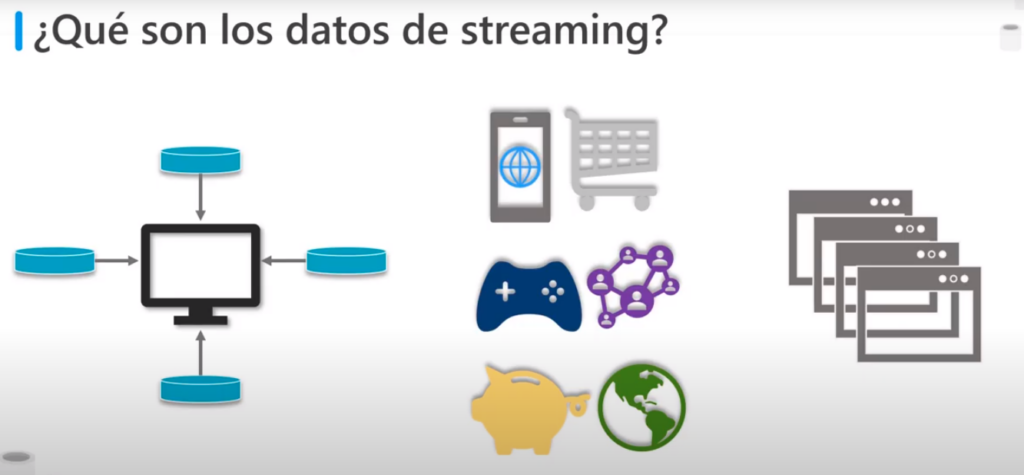
¿Qué son los datos de Streaming?
- Son datos que se generan constantemente a partir de muchas fuentes de datos, que envían los datos simultáneamente en conjuntos de datos pequeños
- Estos datos deben procesarse de manera secuencial de registro por registro o en ventanas graduales
- Se utilizan para diferentes tipos de análisis como correccionales, agregaciones, filtrado y muestreo
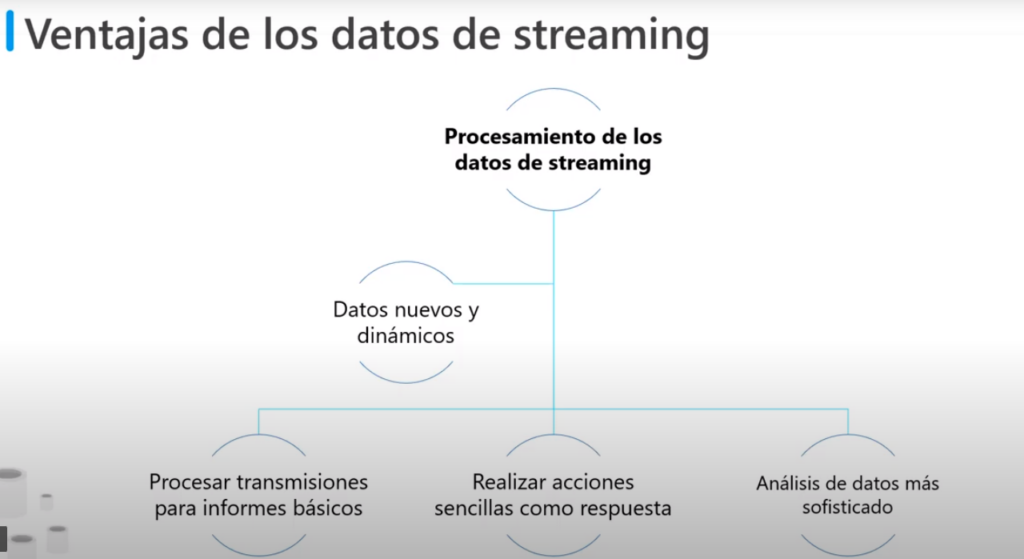
Ventajas
- Tiene ventaja cuando se generan datos nuevos y dinámicos en forma constante
- Se basa en procesar transmisiones, para realizar acciones sencillas como respuesta
- Por ejemplo emitir alertas cuando se supera cierto umbral
- Y con el tiempo pueden realizar análisis más sofisticados, como algoritmos de aprendizaje automático
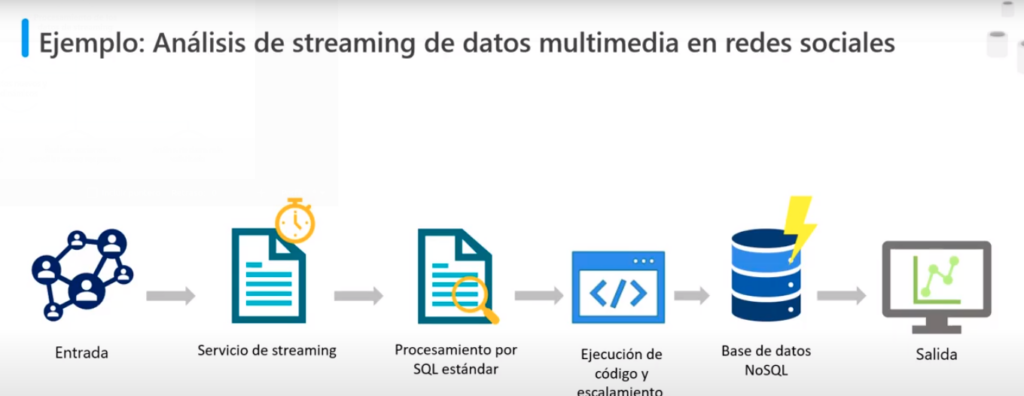
Ejemplos
- Sensores de vehículos de transporte
- Datos multimedia en redes sociales
- Con la entrada se cargan los datos a un servicio de streaming
- Este servicio ingiere y almacena los feed’s de las redes sociales para para su procesamiento
- El procesamiento de SQL estándar genera datos de HashTag en tiempo real
- Se ejecuta el código solo cuando es necesario
- Y se escala automáticamente
- Se escriben los datos a un BD No SQL
- Aquí se almacenan las tendencias de las redes sociales
- Ya se pueden visualizar los resultados
MCT: Video1.1.4: Descripción de las diferencias entre procesamiento por lotes y streaming
El procesamiento de datos
- El procesamiento de datos es la conversión datos a información significativa
- En función de como llegan los datos al sistemas se pueden clasificar en
- Streaming:
- Donde se procesan cada uno de los datos según como llegan
- Procesamiento por lotes:
- Se pueden almacenar el el bufer de datos sin procesar y procesarlos en grupos
- Streaming:

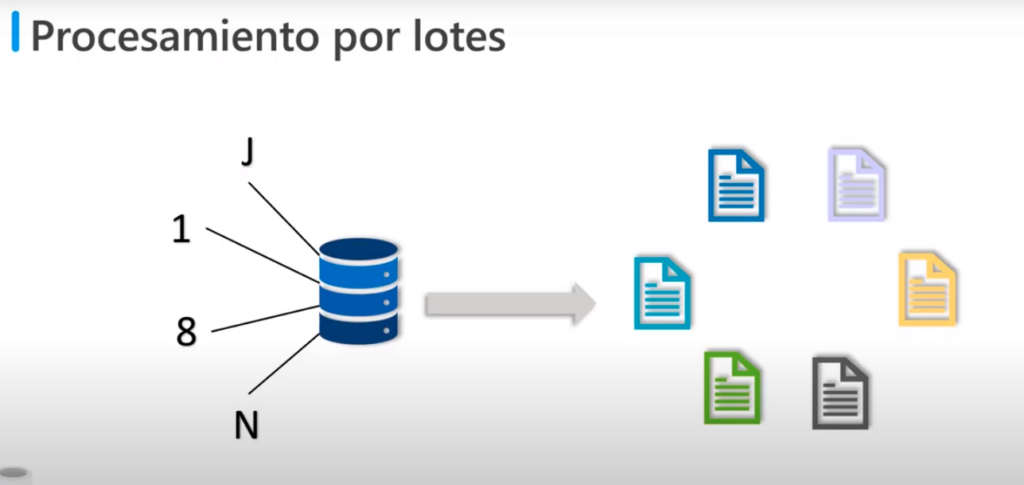
Procesamiento por lotes
- En el procesamiento por lotes los alimentos de datos se recopilan en un grupo conforme van llegando
- Después todo el grupo se procesa más adelante como un lote
- La forma en como se procesa cada grupo se puede determinar de varias maneras
- Ventajas
- Se pueden procesar grandes volúmenes de datos en un momento determinado y se pueden programar en la noche o momento de poca actividad
- Desventajas
- El tiempo de retardo entre la ingesta de datos y la obtención de los resultados
- Todos los datos deben estar listos para poder procesar un lote, es decir los datos deben comprobarse con cuidado
- Los problemas que se dan con los datos, errores y bloqueos de los programas que se dan mientras se realiza la carga de los datos
Procesamiento de datos de streaming y en tiempo real
- En el procesamiento en streaming cada nuevo fragmento de datos se procesa cuando llega
- Trata los datos en tiempo real
- Ejemplos:
- Institución financiera: seguimiento en tiempo real de la bolsa de valores
- Vídeo juegos en linea: registra las acciones de los jugadores

Diferencias entre los datos de streaming y por lotes
| Lote | Streaming | |
| Ámbito de los datos | puede procesar todos los datos del conjunto de datos | Solo tiene los últimos datos |
| Tamaño | Puede procesar grandes conjuntos de datos de manera eficaz | Esta diseñado para registros individuales o microlotes que constan de pocos registros |
| Rendimiento | La latencia es de unas horas | Es casi inmediato, lantencia de segundos o milisegundos |
| Análisis | Para análisis complejos | Para análisis de respuestas simples, agregaciones o cálculos, como la media acumulada |
MCT: Video 1.1.5: Descripción de los datos relacionales
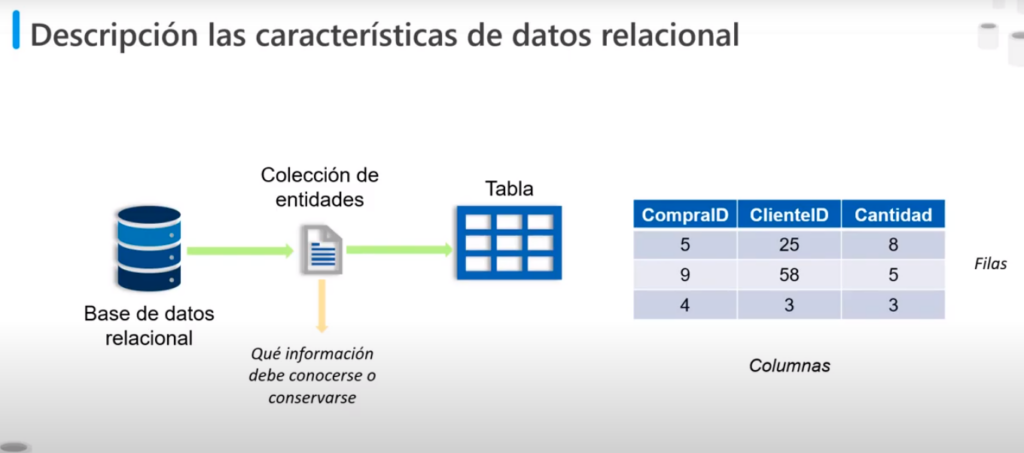
Descripción las características de datos relacional
- En una BD relacional las colecciones de entidades del mundo real se modelan en forma de tablas
- Una entidad se define como: ¿Qué información debe conocerse o conservarse?
- Las filas de una tabla tienen 1 o más columnas que definen las propiedades de la entidad
- Por ejemplo: nombre del cliente o ID del producto
- Todas las filas tienen las mismas columnas
- Algunas columnas se utilizan para mantener la relación entre las tablas, de aquí proviene el nombre de modelo relacional
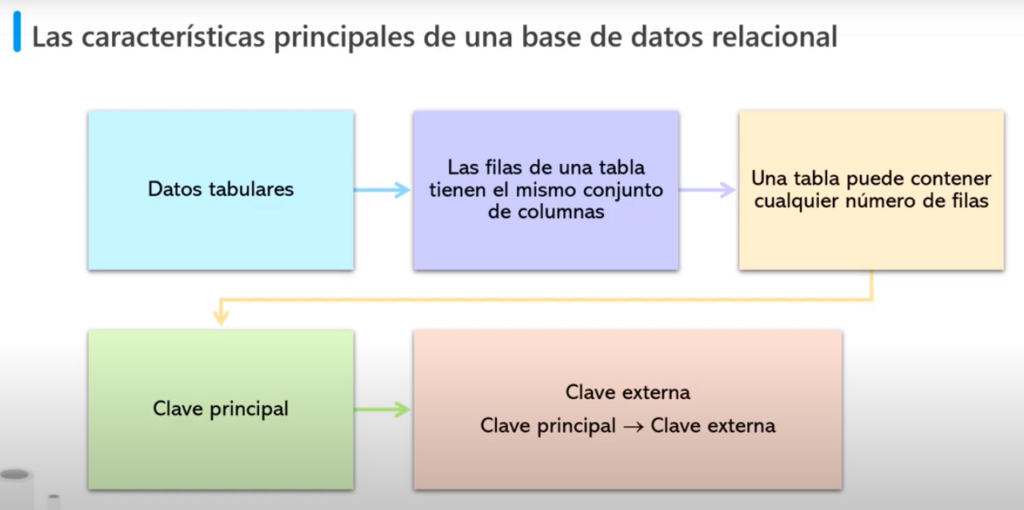
Características de una BD relacional
- Todos los datos son tabulares
- Las entidades se modelan como tablas
- Cada instancia de la entidad es una fila de la tabla y cada propiedad se define como una columna
- Todas las filas tienen las mismas columnas
- Una tabla puede tener cualquier número de filas
- La clave principal identifica de forma exclusiva cada fila de la tabla
- La clave externa hace referencia a las filas de otra tabla relacionada
- La mayoría de la bases de datos relacionales admiten el Lenguaje de Consulta Estructurado (SQL)
Casos de uso de una BD relacional
- Las aplicaciones OLTP se centran en transacciones, que procesan un gran número de interacciones por minuto
- Admiten operaciones de inserción, actualización y eliminación
- Ejemplos: Bancos / Comercios en linea / Reserva de vuelos / etc
