https://docs.microsoft.com/es-mx/learn/modules/explore-relational-data-offerings/1-introduction
Unidad 1: Introducción
Cuando se empezaron a usar los sistemas informáticos, cada aplicación almacenaba los datos en su propia estructura, que era única. Cuando los desarrolladores querían crear aplicaciones para usar esos datos, necesitaban mucha información sobre la estructura de datos en particular para encontrar los que necesitaban. Estas estructuras de datos eran ineficaces, costosas de mantener y difíciles de optimizar para que la aplicación tuviera un buen rendimiento. El modelo de base de datos relacional se diseñó para resolver el problema de tener varias estructuras de datos arbitrarias. El modelo relacional proporciona una forma estándar de representar y consultar datos que cualquier aplicación puede usar. Una de las principales ventajas del modelo de base de datos relacional es el uso de tablas, que son una manera intuitiva, eficaz y flexible de almacenar información estructurada y acceder a ella.
El modelo relacional, sencillo pero eficaz, se usa en organizaciones de todo tipo y tamaño para satisfacer diferentes necesidades de administración de la información. Las bases de datos relacionales se utilizan para realizar un seguimiento de los inventarios, procesar transacciones de comercio electrónico, administrar grandes cantidades de información de clientes críticos y mucho más. Las bases de datos relacionales son útiles para almacenar cualquier información que contenga elementos de datos relacionados que se deban organizar en una estructura coherente y basada en reglas.
En este módulo, obtendrá información sobre las características clave de las bases de datos relacionales y explorará las estructuras de datos relacionales.
Unidad 2: Información sobre los datos relacionales
En una base de datos relacional, las colecciones de entidades del mundo real se modelan en forma de tablas. Una entidad puede ser cualquier elemento para el que quiera registrar información; por lo general, se trata de objetos y eventos importantes. Por ejemplo, en un sistema de venta al por menor, puede crear tablas para clientes, productos, pedidos y artículos de línea de un pedido. Una tabla contiene filas, y cada fila representa una instancia única de una entidad. En este escenario de venta al por menor, cada fila de la tabla de clientes contiene los datos de un solo cliente, cada fila de la tabla de productos define un único producto, cada fila de la tabla de pedidos representa un pedido realizado por un cliente y cada fila de la tabla de artículos de línea representa un producto que se ha incluido en un pedido.
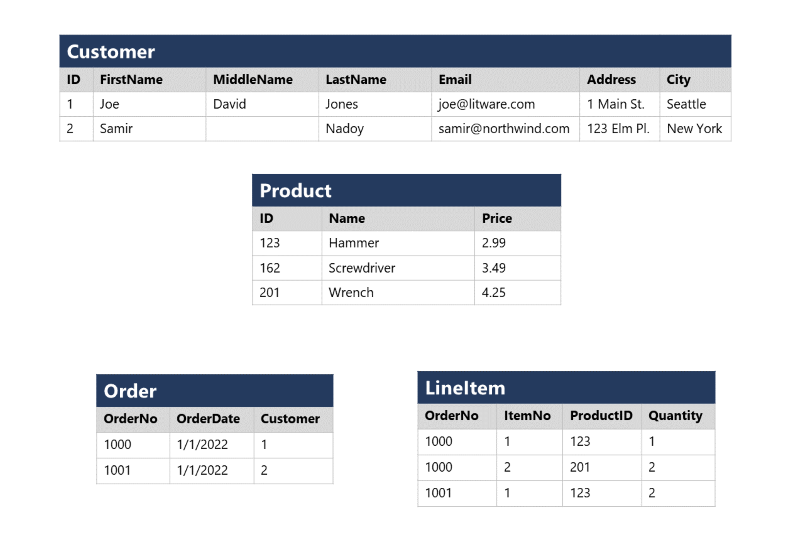
Las tablas relacionales son un formato para datos estructurados y cada fila de una tabla tiene las mismas columnas, aunque en algunos casos no todas las columnas necesitan tener un valor. Por ejemplo, una tabla de clientes puede incluir una columna MiddleName, que podría estar vacía (o ser NULL) para las filas que representan a los clientes que no tienen un segundo nombre o cuyo segundo nombre se desconoce.
Cada columna almacena los datos de un tipo de datos específico. Por ejemplo, una columna Email de una tabla Customer probablemente se definiría para almacenar datos basados en caracteres (texto), que podrían ser de longitud fija o variable. Una columna Price de una tabla Product podría definirse para almacenar datos numéricos decimales, mientras que una columna Quantity de una tabla Order podría estar restringida a valores numéricos enteros. Una columna OrderDate de la misma tabla Order se definiría para almacenar valores de fecha y hora. Los tipos de datos disponibles que se pueden usar al definir una tabla dependen del sistema de base de datos que se use, aunque hay tipos de datos estándar definidos por el American National Standards Institute (ANSI) que son compatibles con la mayoría de los sistemas de base de datos.
Unidad 3: Comprensión de la normalización
La normalización es un término que usan los profesionales de bases de datos para referirse a un proceso de diseño de esquemas que reduce al mínimo la duplicación de los datos e impone la integridad de los datos.
Aunque hay muchas reglas complejas que definen el proceso de refactorización de los datos en varios niveles (o formas) de normalización, una definición sencilla a efectos prácticos es:
- Separar cada entidad en su propia tabla.
- Separar cada atributo discreto en su propia columna.
- Identificar de forma única cada instancia de entidad (fila) mediante una clave principal.
- Usar columnas de clave externa para vincular entidades relacionadas.
Para comprender los principios básicos de la normalización, supongamos que la tabla siguiente representa una hoja de cálculo que una empresa usa para realizar un seguimiento de sus ventas.
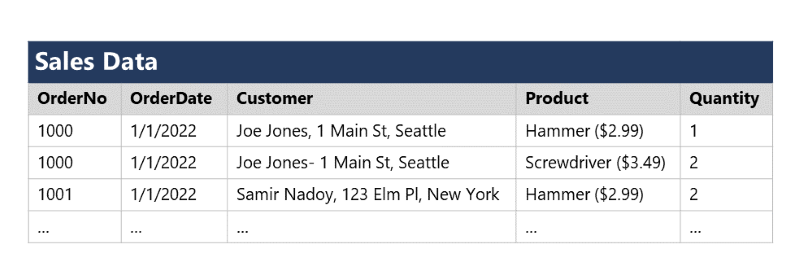
Observe que los detalles del cliente y del producto están duplicados para cada artículo individual que se vende. Además, el nombre del cliente y la dirección postal, así como el nombre del producto y el precio, están combinados en las mismas celdas de la hoja de cálculo.
Ahora veamos el modo en que la normalización cambia la forma de almacenar los datos.

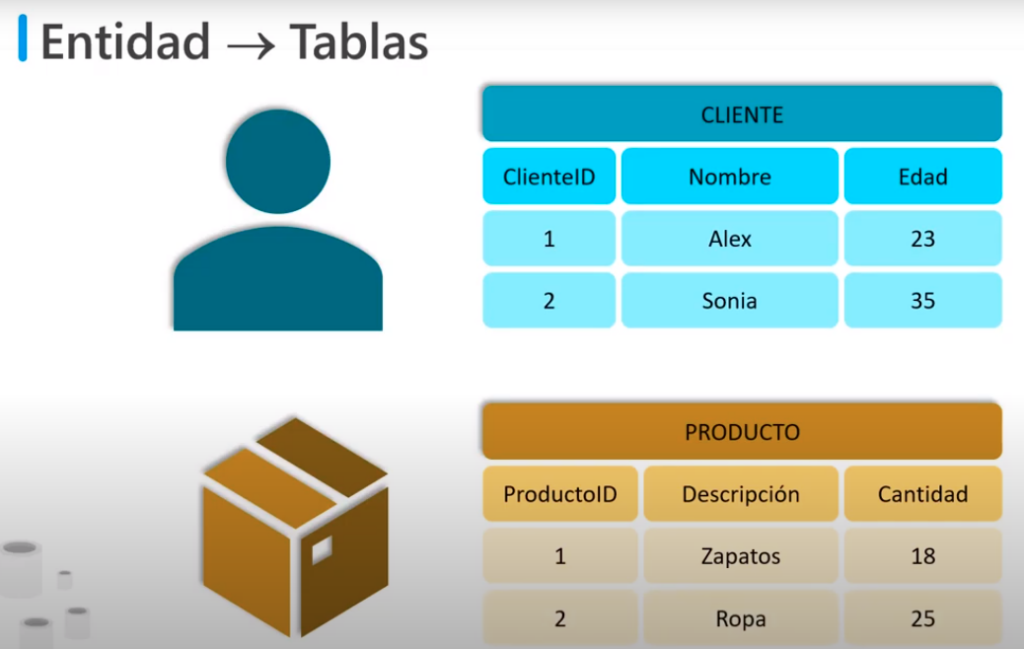
Cada entidad que se representa en los datos (cliente, producto, pedido de ventas y artículo de línea) se almacena en su propia tabla, y cada atributo discreto de esas entidades está en su propia columna.
Al registrar cada instancia de una entidad como una fila en una tabla específica de la entidad, se elimina la duplicación de datos. Por ejemplo, para cambiar la dirección de un cliente, solo hace falta modificar el valor en una sola fila.
La descomposición de atributos en columnas individuales garantiza que cada valor esté restringido a un tipo de datos adecuado. Por ejemplo, los precios de los productos deben ser valores decimales, mientras que las cantidades de artículos de línea deben ser números enteros. Además, la creación de columnas individuales aporta un nivel útil de granularidad a los datos a la hora de realizar las consultas; por ejemplo, puede filtrar fácilmente los clientes que viven en una ciudad concreta.
Las instancias de cada entidad se identifican de forma única mediante un identificador u otro valor de clave, conocido como clave principal; y cuando una entidad hace referencia a otra (por ejemplo, un pedido tiene un cliente asociado), la clave principal de la entidad relacionada se almacena como una clave externa. Puede buscar la dirección del cliente (que se almacena solo una vez) para cada registro de la tabla Order si hace referencia al registro correspondiente en la tabla Customer. Normalmente, un sistema de administración de bases de datos relacionales (RDBMS) puede aplicar la integridad referencial para garantizar que un valor especificado en un campo de clave externa tenga una clave principal correspondiente existente en la tabla relacionada (lo que, por ejemplo, impide la realización de pedidos para clientes que no existen).
En algunos casos, se puede definir una clave (principal o externa) como una clave compuesta basada en una combinación única de varias columnas. Por ejemplo, la tabla LineItem del ejemplo anterior usa una combinación única de OrderNo y ItemNo para identificar un artículo de línea de un pedido individual.
MCT: 2.1.1 Descripción de las caracteristicas de los datos relacionales
Inicio de las BD
- Cuando se comenzó a utilizar las BD cada organización almacenan su información con su propio estructura lo que provocaba diversas complicaciones, por ejemplo
- Los desarrolladores requerían demasiada información sobre la estructura de los datos
- Era ineficaces y costosas de mantener y difícil de optimizar para que la aplicación tuviera un buen rendimiento
Bases de datos Relacionales
- Una solución a este problema fue crear la BD relacionales
- Donde el aspecto más importe fue el uso de tablas ya que brinda una formula intuitiva, eficaz y casi flexible de almacenar y consultar información estructurada
Implementaciones
- Realizar un seguimiento de inventarios
- Administrar información de clientes, empleados, etc
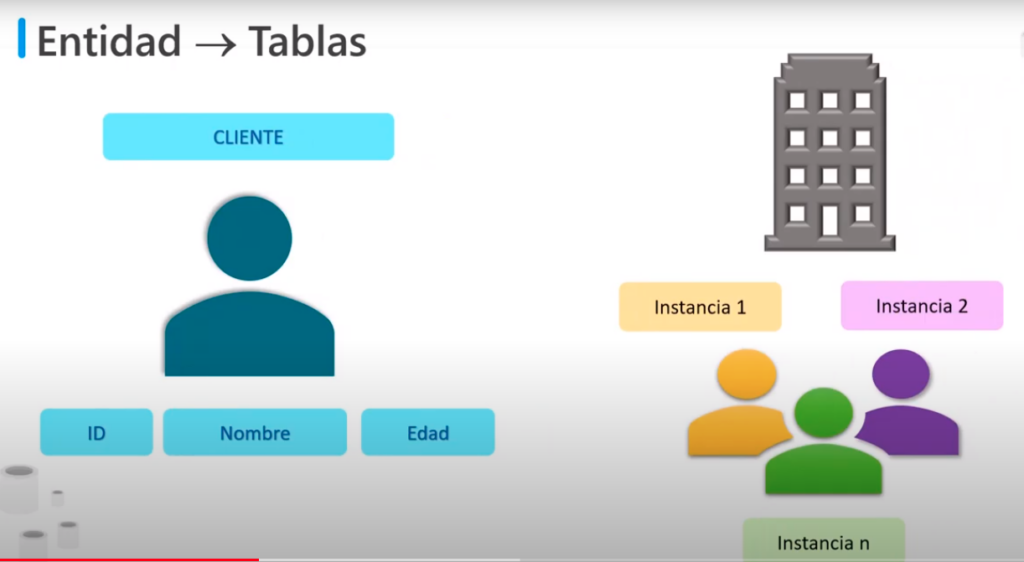
Entidad -> tablas
- En una BD relacional las colecciones de mundo real se modelan en forma de tablas
- Una entidad de describe como que información se debe conocerse o conservarse
- Por ejemplo:
- La entidad cliente cuenta con ciertas características que llamaremos propiedades y ppueden ser representada por datos como ID / Nombre / Edad
- En la empresa pueden existir un gran número de clientes y cada se le llamara instancia
- Las instancias las organizaremos en filas y las propiedades en columnas obteniendo las siguiente estructura
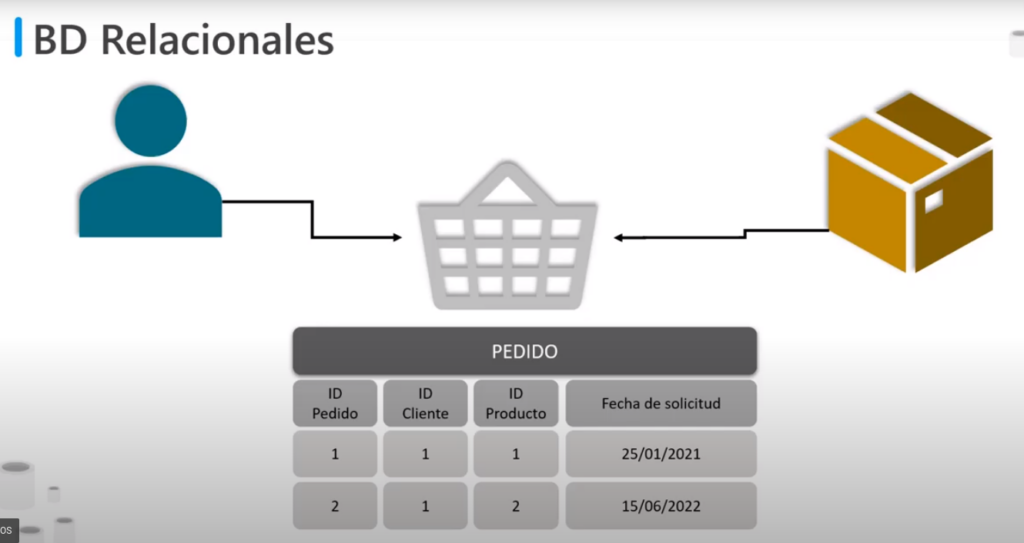
BD Relacionales
- Su nombre es por que las entidades se pueden relacionar entre sí creando una nueva tablas
- Por ejemplo: para relacionar un cliente con los productos es necesario crear una nueva tabla llamada pedido
Modelado
Una BD puede tener muchas entidades y muchas relaciones por tanto necesario seguir una serie de reglas
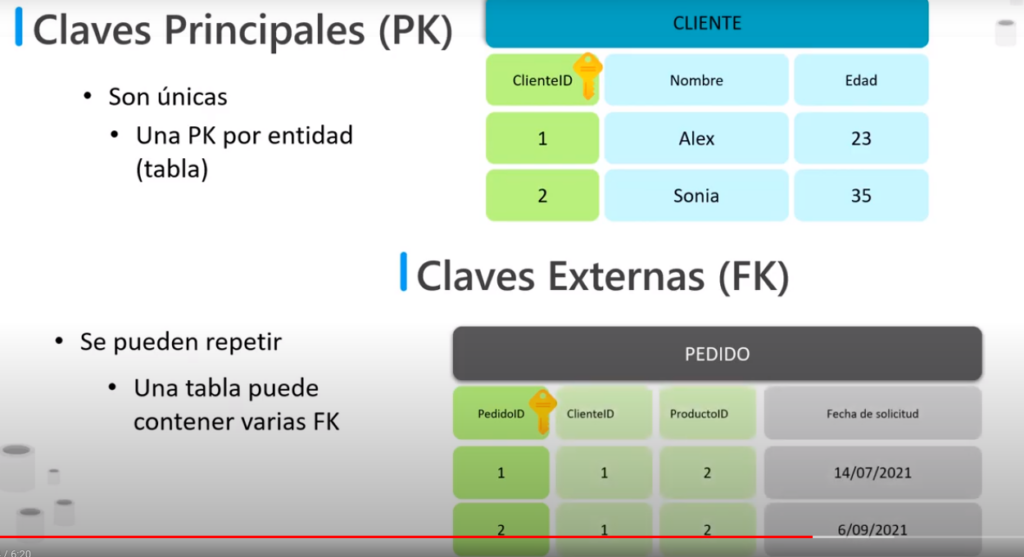
- Cada tabla requiere una clave Principal (PK) que debe ser única e irrepetible y es el identificador de cada entidad
- Cuando una instancia tiene llaves primarias de otras entidades son llamadas claves externas (FK), estas si se pueden repetir y una tabla puede contener más de una clave externa
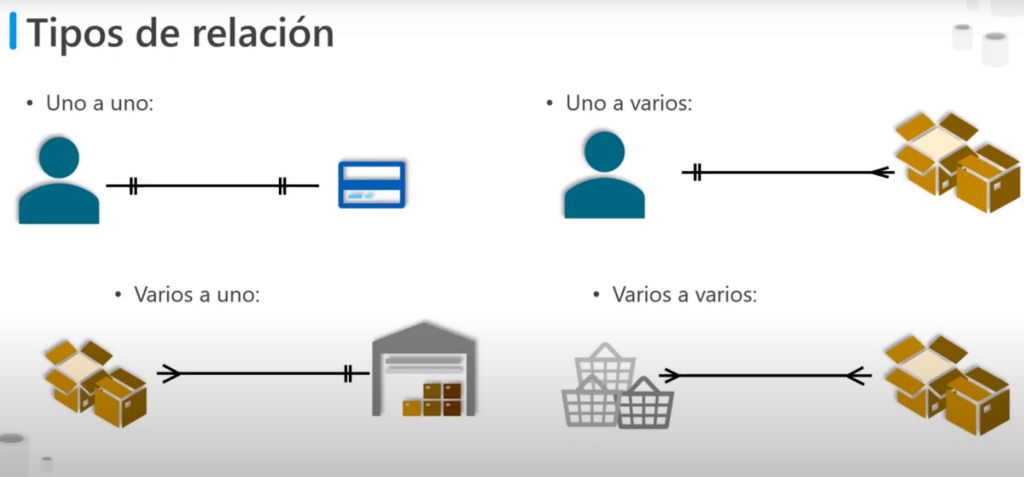
Tipos de relación
Para representar la relación entre entidades se utilizan diferentes notaciones:
- Uno a uno: por ejemplo un cliente puede tener solo una tarjeta de crédito
- Uno a varios: un cliente puede tener varios pedidos
- Varios a uno: varios productos llegan a un almacén
- Varios a Varios: varios pedidos pueden solicitar varios productos
- De esta forma podemos obtener el modelo de la base de datos por medio de tablas y su relaciones

Resumen
- Todos los datos son tabulares
- Las entidades se modelan como tablas
- Cada instancia de la entidad es una fila de la tabla
- Cada propiedad se define como una columna
- Cada fila de una tabla tiene el mismo conjunto de columnas
- Una tabla puede tener cualquier número de filas
- Una clave principal identifica de forma única cada fila de la tabla
- Dos filas no pueden compartir la misma clave principal
- Una clave externa hace referencia a la clave principal de otra tabla
Unidad 4: Exploración de SQL
SQL significa Lenguaje de consulta estructurado (por sus siglas en inglés) y se usa para comunicarse con una base de datos relacional. Se trata del lenguaje estándar para los sistemas de administración de bases de datos relacionales. Las instrucciones SQL se usan para realizar tareas como actualizar o recuperar datos de una base de datos. Algunos sistemas de administración de bases de datos relacionales habituales que utilizan SQL incluyen Microsoft SQL Server, MySQL, PostgreSQL, MariaDB y Oracle.
Nota:
El Instituto Nacional Estadounidense de Estándares (ANSI) estandarizó originalmente el lenguaje SQL en 1986 y, luego, la Organización Internacional de Normalización (ISO), en 1987. Desde entonces, el estándar se ha ampliado varias veces a medida que los proveedores de bases de datos relacionales han agregado nuevas características a sus sistemas. Además, la mayoría de los proveedores de bases de datos incluyen sus propias extensiones que no forman parte del estándar, lo que ha dado lugar a la creación de varios dialectos de SQL.
Puede usar instrucciones SQL como SELECT, INSERT, UPDATE, DELETE, CREATE y DROP para realizar prácticamente cualquier tarea que deba llevarse a cabo con una base de datos. Si bien estas instrucciones SQL forman parte del estándar SQL, muchos sistemas de administración de bases de datos también cuentan con extensiones propias adicionales para controlar los detalles de ese sistema de administración de bases de datos. Estas extensiones proporcionan una funcionalidad que no se incluye en el estándar de SQL y contienen áreas como la administración de la seguridad y la capacidad de programación. Por ejemplo, Microsoft SQL Server y los servicios de base de datos de Azure basados en el motor de base de datos de SQL Server usan Transact-SQL. Esta implementación incluye extensiones propias para escribir procedimientos almacenados y desencadenadores (código de aplicación que se puede almacenar en la base de datos), y administrar cuentas de usuario. PostgreSQL y MySQL también tienen sus propias versiones de estas características.
Algunos dialectos populares de SQL incluyen:
- Transact-SQL (T-SQL). Esta versión de SQL la usan los servicios Microsoft SQL Server y Azure SQL.
- pgSQL. Se trata del dialecto, con extensiones, que se implementa en PostgreSQL.
- PL/SQL. Se trata del dialecto que utiliza Oracle. PL/SQL significa «lenguaje de procedimientos/SQL».
Los usuarios que planeen trabajar específicamente con un sistema de base de datos única deben conocer los pormenores del dialecto y la plataforma de SQL preferidos.
Nota
Los ejemplos de código SQL de este módulo se basan en el dialecto de Transact-SQL, a menos que se indique lo contrario. La sintaxis de otros dialectos suele ser similar, pero puede variar en algunos detalles.
Tipos de instrucción SQL
Las instrucciones SQL se agrupan en tres grupos lógicos principales:
- Lenguaje de definición de datos (DDL)
- Lenguaje de control de datos (DCL)
- Lenguaje de manipulación de datos (DML)
Instrucciones DDL
Las instrucciones DDL se usan para crear, modificar y quitar tablas y otros objetos de una base de datos (tabla, procedimientos almacenados, vistas, etc.).
Las instrucciones de DDL más habituales son las siguientes:

Advertencia: La instrucción DROP es muy eficaz. Al quitar una tabla, se pierden todas las filas de esa tabla. Salvo en el caso de que tenga una copia de seguridad, no podrá recuperar los datos.
En el siguiente ejemplo se crea una nueva tabla de base de datos. Los elementos entre paréntesis especifican los detalles de cada columna, como el nombre, el tipo de datos, si la columna debe contener siempre un valor (distinto de NULL) y si los datos de la columna se usan para identificar de forma única una fila (CLAVE PRINCIPAL). Cada tabla debe tener una clave principal, aunque SQL no aplica forzosamente esta regla.
Nota
Las columnas marcadas como NOT NULL se denominan columnas obligatorias. Si omite la cláusula NOT NULL, puede crear filas que no contengan un valor en la columna. Se considera que una columna vacía de una fila tiene un valor NULL.
CREATE TABLE Product
(
ID INT PRIMARY KEY,
Name VARCHAR(20) NOT NULL,
Price DECIMAL NULL
);Los tipos de datos disponibles para las columnas de una tabla variarán en función del sistema de administración de bases de datos. Aun así, la mayoría de los sistemas de administración de bases de datos admiten tipos numéricos como INT (un número entero), DECIMAL (un número decimal) y tipos de cadena como VARCHAR (VARCHAR significa «datos de caracteres de longitud variable»). Para obtener más información, consulte la documentación del sistema de administración de bases de datos que ha seleccionado.
Instrucciones DCL
Los administradores de bases de datos suelen usar instrucciones DCL para administrar el acceso a objetos de una base de datos mediante la concesión, denegación o revocación de permisos a usuarios o grupos específicos.
Las tres instrucciones DCL principales son las siguientes:

Por ejemplo, la siguiente instrucción GRANT permite a un usuario denominado user1 leer, insertar y modificar datos en la tabla Product.
GRANT SELECT, INSERT, UPDATE
ON Product
TO user1;Instrucciones DML
Las instrucciones DML se usan para manipular las filas de las tablas. Estas instrucciones permiten recuperar (consultar) datos, insertar nuevas filas o modificar filas existentes. También puede eliminar filas si ya no las necesita.
Las cuatro instrucciones DML principales son las siguientes:

La forma básica de una instrucción INSERT insertará una fila cada vez. De forma predeterminada, las instrucciones SELECT, UPDATE y DELETE se aplican a todas las filas de una tabla. Normalmente, se aplica una cláusula WHERE con estas instrucciones para especificar criterios, de forma que solo se seleccionen, actualicen o eliminen las filas que cumplan estos criterios.
Advertencia: SQL no ofrece solicitudes de confirmación, por lo que debe tener cuidado al usar DELETE o UPDATE sin una cláusula WHERE, ya que podría perder o modificar una gran cantidad de datos.
El código siguiente es un ejemplo de una instrucción SQL que permite seleccionar todas las filas (indicadas con *) de la tabla Customer, donde el valor de la columna Ciudad es «Seattle»:
SELECT *
FROM Customer
WHERE City = 'Seattle';Para recuperar solo un subconjunto específico de columnas de la tabla, puede enumerarlas en la cláusula SELECT, tal como se muestra a continuación:
SELECT FirstName, LastName, Address, City
FROM Customer
WHERE City = 'Seattle';Si una consulta devuelve muchas filas, estas no necesariamente aparecen en una secuencia concreta. Si quiere ordenar los datos, puede agregar una cláusula ORDER BY. Los datos se ordenarán por la columna especificada:
SELECT FirstName, LastName, Address, City
FROM Customer
WHERE City = 'Seattle'
ORDER BY LastName;También puede ejecutar instrucciones SELECT que recuperen datos de varias tablas mediante una cláusula JOIN. Las combinaciones indican cómo las filas de una tabla se conectan con las filas de la otra para determinar qué datos se van a devolver. Una condición de combinación típica coincide con una clave externa de una tabla y su clave principal asociada en la otra tabla.
En la consulta siguiente se muestra un ejemplo que une las tablas Customer y Order. La consulta usa alias de tabla para abreviar los nombres de tabla al especificar qué columnas deben recuperarse en la cláusula SELECT y qué columnas deben coincidir en la cláusula JOIN.
SELECT o.OrderNo, o.OrderDate, c.Address, c.City
FROM Order AS o
JOIN Customer AS c
ON o.Customer = c.IDEn el ejemplo siguiente se muestra cómo modificar una fila existente mediante SQL. Se cambia el valor de la columna Address de la tabla Customer para las filas que tienen el valor 1 en la columna ID. Todas las demás filas permanecen sin cambios:
UPDATE Customer
SET Address = '123 High St.'
WHERE ID = 1;Advertencia: Si omite la cláusula WHERE, una instrucción UPDATE modificará todas las filas de la tabla.
Use la instrucción DELETE para quitar filas. Debe especificar la tabla en la que se va a realizar la eliminación y una cláusula WHERE que identifique las filas que se van a eliminar:
DELETE FROM Product
WHERE ID = 162;Advertencia: Si omite la cláusula WHERE, una instrucción DELETE quitará todas las filas de la tabla.
La instrucción INSERT tiene un formato ligeramente diferente. Debe especificar una tabla y las columnas en una cláusula INTO, y una lista de valores que se van a almacenar en estas columnas. El lenguaje SQL estándar solo admite la inserción de una fila cada vez, tal como se muestra en el ejemplo siguiente. Algunos dialectos le permiten especificar varias cláusulas VALUES para agregar varias filas a la vez:
INSERT INTO Product(ID, Name, Price)
VALUES (99, 'Drill', 4.99);Nota:
En este tema se describen algunas instrucciones SQL y sintaxis básicas para ayudarle a comprender cómo se usa SQL para trabajar con objetos en una base de datos. Si quiere obtener más información sobre cómo consultar datos con SQL, revise la ruta de aprendizaje Introducción a las consultas con Transact-SQL en Microsoft Learn.
Unidad 5: Descripción de objetos de base de datos
Además de las tablas, una base de datos relacional puede contener otras estructuras que ayudan a optimizar la organización de los datos, encapsular acciones mediante programación y mejorar la velocidad de acceso. En esta unidad, obtendrá más información sobre tres de estas estructuras: vistas, procedimientos almacenados e índices.
¿Qué es una vista?
Una vista es una tabla virtual basada en los resultados de una consulta SELECT. Podría decirse que una vista es como una ventana que muestra unas filas concretas de una o varias tablas subyacentes. Por ejemplo, podría crear una vista en las tablas Order y Customer que recupere los datos de pedidos y clientes para proporcionar un objeto único que haga más fácil determinar las direcciones de entrega de los pedidos:
CREATE VIEW Deliveries
AS
SELECT o.OrderNo, o.OrderDate,
c.FirstName, c.LastName, c.Address, c.City
FROM Order AS o JOIN Customer AS c
ON o.CustomerID = c.ID;Puede consultar la vista y filtrar los datos de la misma forma que una tabla. La consulta siguiente busca detalles de los pedidos de los clientes que viven en Seattle:
SELECT OrderNo, OrderDate, LastName, Address
FROM Deliveries
WHERE City = 'Seattle';¿Qué es un procedimiento almacenado?
Un procedimiento almacenado define instrucciones SQL que se pueden ejecutar a petición. Los procedimientos almacenados se usan para encapsular la lógica de programación en una base de datos para las acciones que las aplicaciones deben realizar al trabajar con datos.
Puede definir un procedimiento almacenado con parámetros a fin de crear una solución flexible para las acciones comunes que podrían tener que aplicarse a los datos en función de una clave o criterios específicos. Por ejemplo, se podría definir el siguiente procedimiento almacenado para cambiar el nombre de un producto en función del identificador de producto especificado.
CREATE PROCEDURE RenameProduct
@ProductID INT,
@NewName VARCHAR(20)
AS
UPDATE Product
SET Name = @NewName
WHERE ID = @ProductID;Cuando haya que cambiar el nombre de un producto, puede ejecutar el procedimiento almacenado y pasar el identificador del producto y el nuevo nombre que se va a asignar:
EXEC RenameProduct 201, 'Spanner';¿Qué es un índice?
Un índice le ayuda a buscar datos en una tabla. Piense en el índice de una tabla como en el índice de la parte final de un libro. El índice de un libro contiene un conjunto ordenado de contenido, junto a las páginas en las que aparece. El índice le servirá para buscar la referencia a un elemento del libro. Puede usar los números de página del índice para ir directamente a las páginas correctas del libro. Sin el índice, es posible que tenga que leer todo el libro para encontrar el contenido que está buscando.
Cuando se crea un índice en una base de datos, se especifica una columna de la tabla; el índice contiene una copia de estos datos con un criterio de ordenación y punteros a las filas correspondientes de la tabla. Cuando el usuario ejecuta una consulta que especifica esa columna en la cláusula WHERE, el sistema de administración de bases de datos puede utilizar el índice para capturar los datos más rápidamente que si tuviera que examinar toda la tabla fila por fila.
Por ejemplo, podría usar el código siguiente para crear un índice en la columna Name de la tabla Product:
CREATE INDEX idx_ProductName
ON Product(Name);El índice crea una estructura basada en árbol que el optimizador de consultas del sistema de base de datos puede usar para buscar rápidamente filas en la tabla Product en función de un nombre específico (Name).
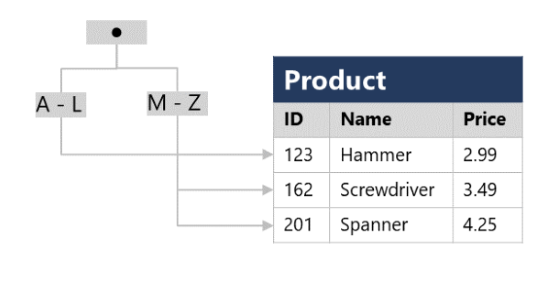
Para una tabla que contiene pocas filas, el uso del índice probablemente no sea más eficaz que simplemente leer toda la tabla y buscar las filas solicitadas por la consulta (en cuyo caso, el optimizador de consultas omitirá el índice). Pero cuando una tabla tiene muchas filas, los índices pueden mejorar drásticamente el rendimiento de las consultas.
Puede crear muchos índices en una tabla. Por lo tanto, si también quisiera buscar productos basados en el precio, podría resultar útil crear otro índice en la columna Price de la tabla Product. Sin embargo, los índices no son gratuitos. Un índice consume espacio de almacenamiento y, cada vez que inserte datos en una tabla, los actualice o los elimine, tendrá que hacer el mantenimiento de sus índices. Este trabajo adicional puede ralentizar las operaciones de inserción, actualización y eliminación. Debe conseguir un equilibrio entre tener índices que aceleren las consultas y el coste de realizar otras operaciones.
MCT: 2.1.2 Descripción de la estructura de datos relaciones con SQL
Tablas en SQL
- Para crear una tabla se utiliza la instrucción CREATE TABLE
- Dentro de los paréntesis se definen los campos (nombre_campo tipo_dato restricciones)
- restricciones:
- Primary Key: clave primaria
- NOT NULL: indica que la columna no puede estar vacia
- UNIQUE: indica que lo valores de na columna no se pueden repetir

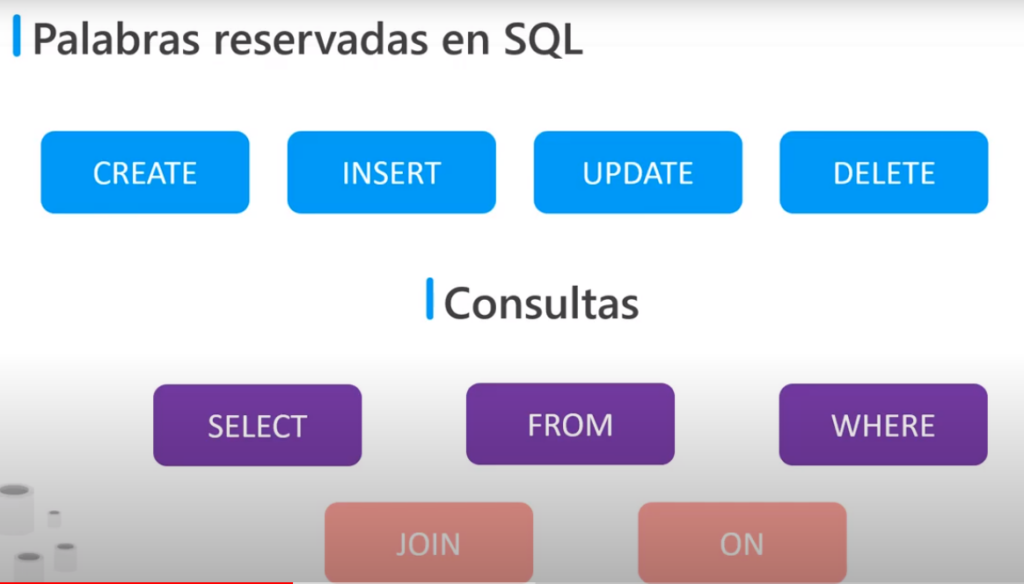
Palabras reservadas
- CREATE: permite crear objetos
- INSERT: almacena datos en una tabla
- UPDATE: actualiza datos de una tabla
- DELETE: quita filas de una tabla
- SELECT: consulta datos de una tabla
- FROM: indica que tabla se va a consultar
- WHERE: permite agregar una condición
- JOIN: unión de tablas
- ON: comparación entre columnas
- Por ejemplo consultas los clientes que sean mayores de 15 años

- Para consultas más complejas se pueden agregar uniones con la palabra reservada JOIN
- Por ejemplo consultar los ID’s de cliente cuyo sea igual al ID’s del producto que solicitaron
- El dato antes del punto se refiere a la tabla y el datos después del punto a la columna solicitada

Vistas
- Existen consultas que son constantemente utilizadas por lo que para mejorar el rendimiento de la BD y que estas consultas se procesen desde cero se pueden utilizar vistas
- Es una tabla virtual definida a partir de una consulta determinada que puede contener distintas columnas de varias tablas
- Por ejemplo: si necesitamos consultas constantemente los pedidos del producto 1
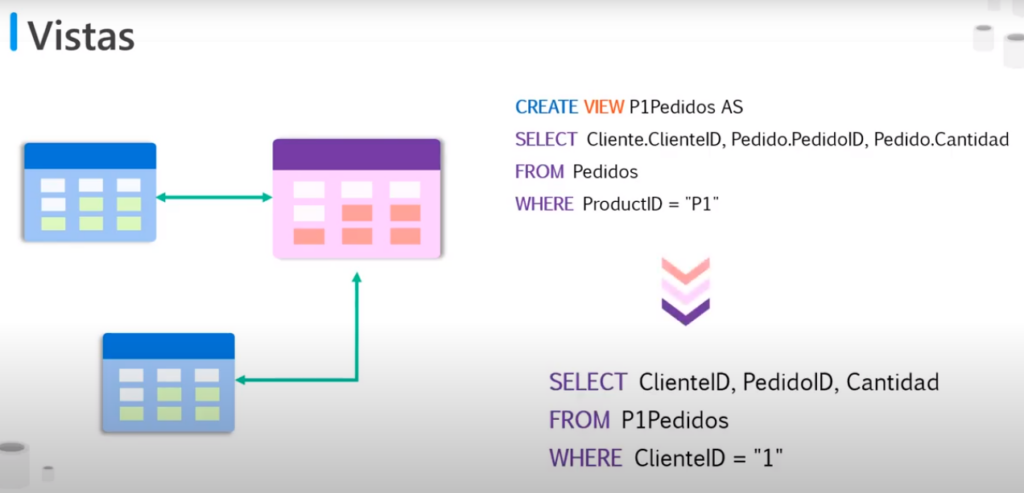
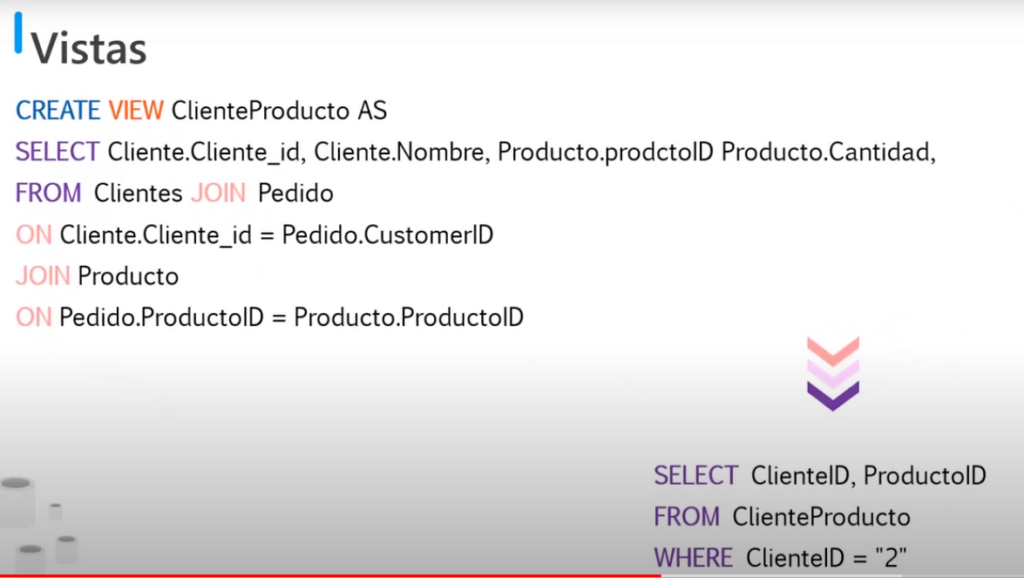
- También se pueden utilizar para combinar datos de dos tablas que se consultan constantemente
- Por ejemplo: se necesita consultar información de los clientes y productos que han pedido
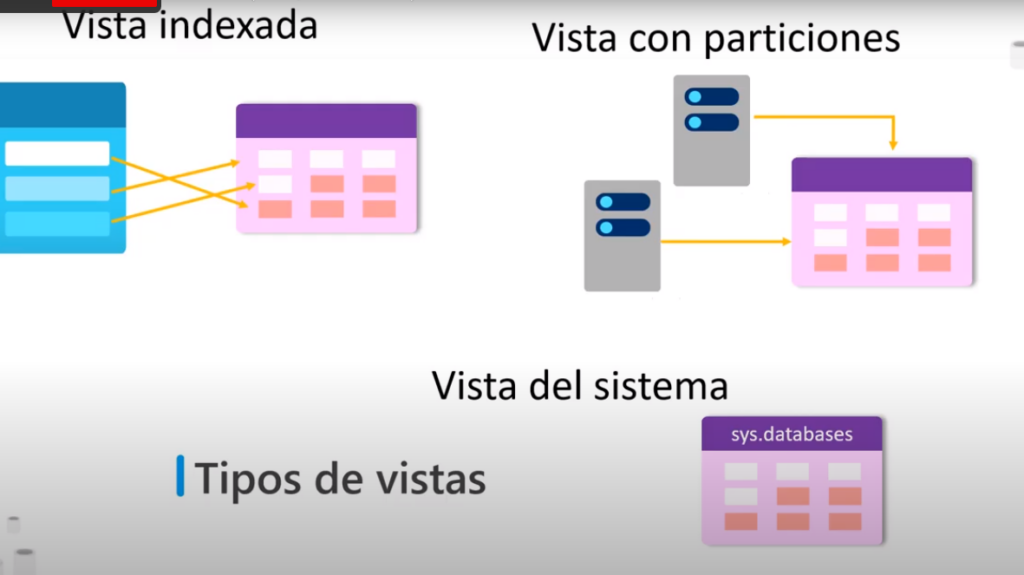
Tipos de vistas
- Vistas indexadas: vistan en las que se crean un índice y que mejoran el rendimiento de las consultas
- Vistas con particiones: combina datos horizontales con particiones de un conjunto de tablas miembro en uno o más servidores
- Vistas del sistemas: expone metadatos que se usan para devolver información de la instancia de SQL Server u objetos definidos en la instancia. Por ejemplo la vista del catalogo sys.database
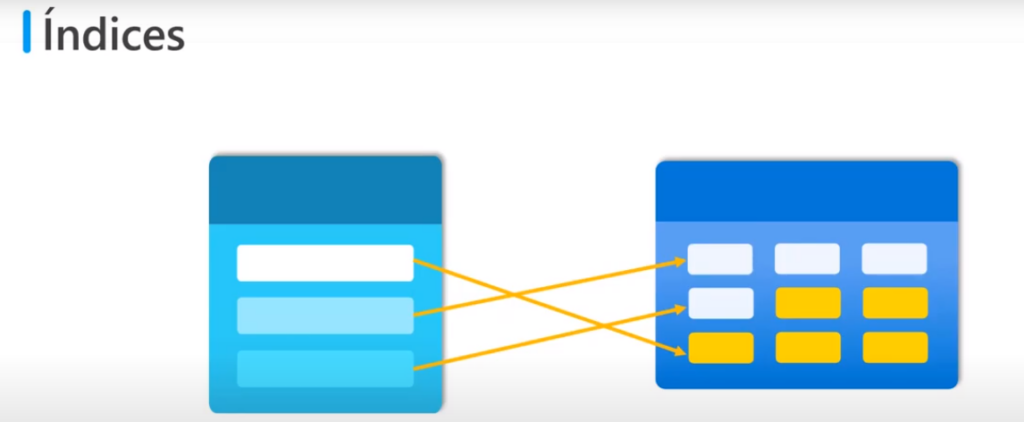
Índice
- Es una estructura asociada con una tabla o vista contiene claves generadas a partir de una o varias columnas
- Sirve para hacer referencia a algunos elementos determinados lo que al hacer consultas acelera la recuperación de filas de una tabla
- Cuando se crea un índice se debe especificar una columna de una tabla, el índice contiene una copia de estos datos como un criterio de ordenación y punteros a las filas correspondientes de la tabla
- Cuando el usuario realiza una consulta que contiene la columna de la cláusula WHERE el sistema de administración de BD puede utilizar el índice obtener los datos más rápidamente que si tuviera que analizar toda la fila
Índice vs Almacenamiento
- Los índices requiere espacio de almacenamiento y mantenimiento que se realiza de forma automática al modificar o eliminar datos de la tabla original
- Por esto no se recomienda crear índices para todas las columnas existentes en una tabla
- Se recomiendan solo cuando la columna sea constantemente requerida en las consultas o en tablas de solo lectura ya que tener una gran cantidad de índices puede afectar el rendimiento de una BD
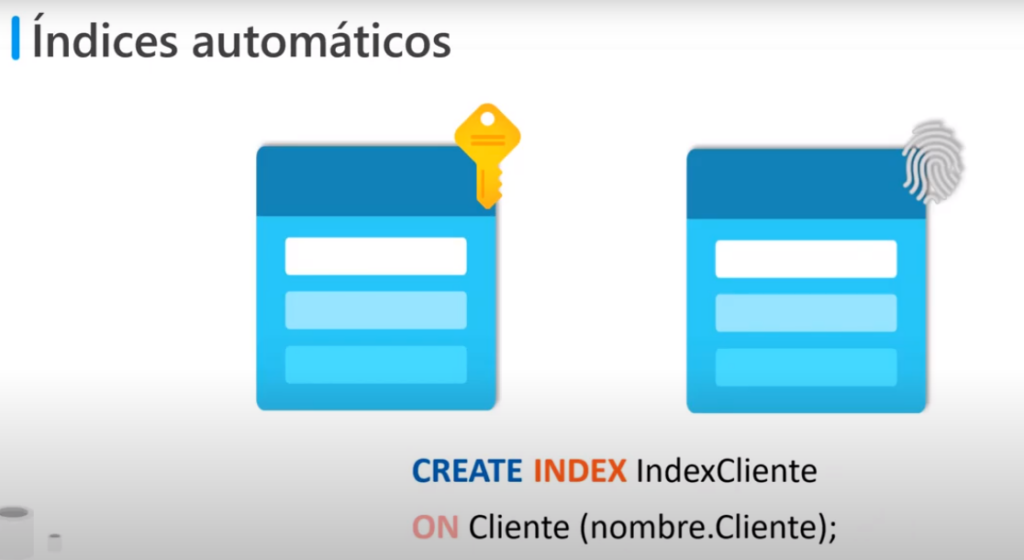
Índices automáticos
- Existen índices que se crean automáticamente, por ejemplo cuando se crea una restricción «Primary Key» se crea un índice clúster único en las columnas si aún no existe un índice cluster en la tabla o o se ha especificado un índice no cluster
- Cuando se crea una restricción «UNIQUE» se creara un índice no cluster único, puede especificarse un índice cluster único si todavía no existe un índice cluster en la tabla
- Para crear un índice se requiere la siguiente sentencia
MCT: 2.1.3 Comparación de Data Definition Lenguaje DDL vs Data Manipulation Language DML
Introducción a SQL
- SQL significa Lenguaje de Consultas Estructurada
- Se utiliza como lenguaje estándar para comunicarse y administrar las BD relacionales
- Permite insertar, actualizar o recuperar información
- Algunos administradores de BD que utilizan SQL son: SQL Database / PosgreSQL / MYSQL /MariaBD / Oracle
- La mayoría acepta tipos de datos como
- INT: Entero
- VARCHAR: cadenas (datos de longitud variable)
Dialectos de SQL
- Existen instrucciones que forman parte del estándar de SQL SELECT / INSERT / UPDATE / CREATE / DROP
- Pero muchos sistemas de administración de BD’s tienen extensiones propias que proporcionan funcionalidades extras en temas de seguridad o programación que no se incluyen en el estándar SQL, es estos se les llama «Dialectos»
- Algunos dialectos más populares son:
- T-SQL: Transac-SQL ( SQL Server / Azure SQL Database)
- PgSQL: para postgreSQL
- PL/SQL: ORACLE
Tipos de instrucciones SQL
Las instrucciones SQL se agrupan en dos grupos principales
- Lenguaje de Manipulación de Datos (DML): que se aplican a los registros de una tabla
- Lenguaje de Definición de Datos (DDL): que se aplican sobre los componentes, columnas o sobre la tabla
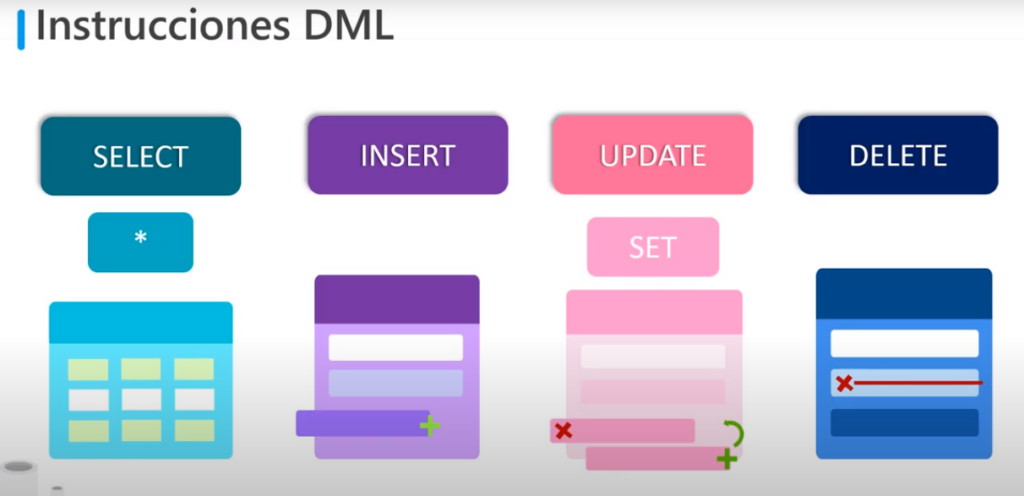
Instrucciones DML
- Se utilizan para manipular las filas de una tabla ( insertar / modificar / eliminar / consultar )
- SET: Permite indicar el valor por el cual se modificará un campo en una instrucción UPDATE
- *: Se utiliza después del SELECT para indicar que se deben obtener todas las columnas
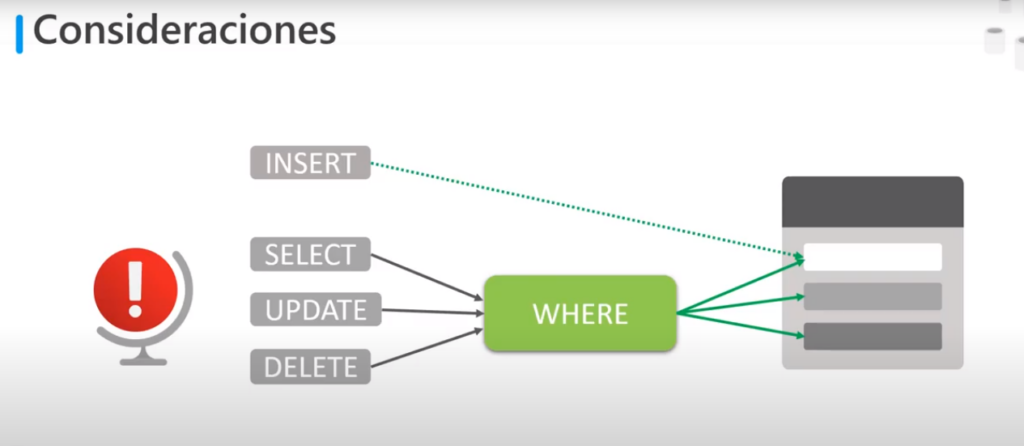
Consideraciones
- La forma básica de una instrucción INSERT insertará una fila de forma predeterminada
- Las instrucciones SELECT / UPDATE / DELETE se aplican a todas las filas de una tabla
- La clausula WHERE es el medio para determinar a que filas deseamos aplicarle la instrucción
- SQL: no ofrece solicitudes de confirmación por lo que se debe tener cuidado al usar DELETE / UPDATE sin una clausula WHERE por que podría perder o modificar una gran cantidad de datos
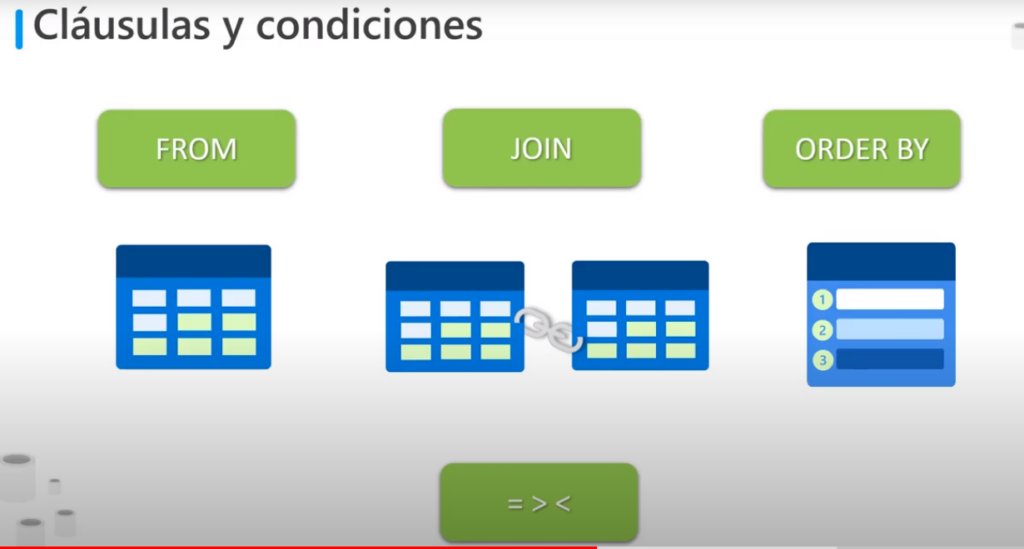
Cláusulas y condiciones
- FROM: indica la tabla que se desea utilizar
- JOIN: permite la combinación de tablas
- ORDER BY: permite ordenar las filas
- Algunas condiciones puede utilizar operadores lógicos (= < >)
Caso de estudio
- Tenemos las siguientes tablas

- Obtener todos los clientes

- Obtener todo los ID’s de clientes cuya edad sea mayor o igual a 18 años

- Cliente más joven

- Obtener todos los productos donde la descripción = «ropa»

- Actualizar nombre de un producto

- Obtener los pedidos de un cliente

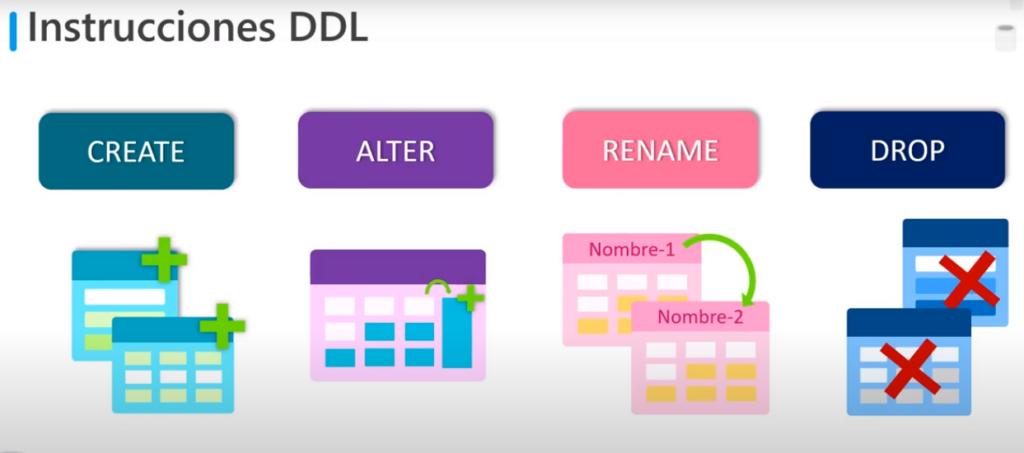
Instrucciones DDL
- Se utilizan para crear, modificar y eliminar tablas u otros objetos como índices, vistas, procedimientos almacenados
- Las más comunes son:
- CREATE: permite crear objetos
- ALTER: modifica la estructura de un objeto (Ej: agregar o quitar columna)
- DROP: eliminar un objeto
- RENAME: renombrar un objeto
Consideraciones
- Al aplicar DROP sobre una tabla esta y sus filas son eliminadas y no se pueden recupar a menos que tenga un respaldo
- Las columnas con NOT NULL se consideran obligatorias
- Las columnas NULL pueden tener o no datos

Ejemplos DDL
- Crear tabla, renombrarla y agregar columna
