Unidad 1: Introducción
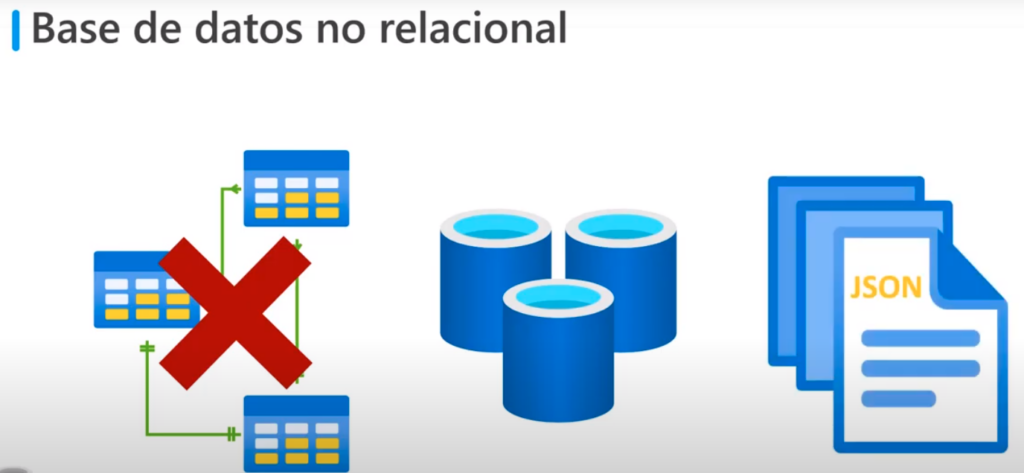
La mayoría de las aplicaciones de software necesitan almacenar datos. Por lo general, esto adopta la forma de una base de datos relacional en la que los datos se organizan en tablas relacionadas y se administran mediante el Lenguaje de consulta estructurado (SQL). Sin embargo, muchas aplicaciones no necesitan la estructura rígida de una base de datos relacional y se basan en el almacenamiento no relacional (conocido a menudo como NoSQL).
Azure Storage es uno de los servicios principales de Microsoft Azure y ofrece una variedad de opciones para almacenar datos en la nube. En este módulo, explorará las funcionalidades principales de Azure Storage y aprenderá cómo se usa para admitir aplicaciones que requieren almacenes de datos no relacionales.
MCT: Video 3.1.1 Descripción de las características de las bases de datos no relacionales
Bases de datos no relacional
- Una BD no relacional es la BD que no utiliza el esquema tabular de filas y columnas
- Utilizan un modelo al almacenamiento optimizado para para el tipo de datos que almacena
- Por ejemplo los valores se pueden almacenar como pares clave:valor, documentos JSON o como un grafo que consta de bordes y vértices
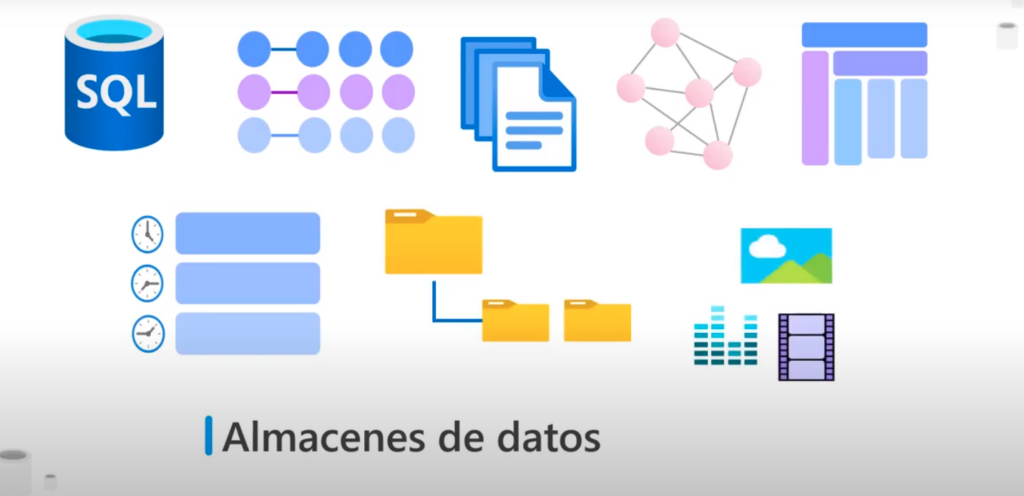
Almacenes de datos
- Para los datos no relacionales existen diferentes tipos de almacenes, por ejemplo:
- clave:valor
- documentos
- JSON
- grafos
- familias de columnas
- Series temporales
- Archivos compartidos
- Almacenamiento de objetos
Clave:valor
- Asocia cada valor de datos a una clave única
- Están optimizados para las aplicaciones que realizan búsquedas simples
- Se almacenan mediante una tablas HASH
- Un ejemplo de aplicación es: un carro de compras:
- Estas pueden recibir un gran número de compras en segundos
- Las BD de clave:valor pueden manejar el escalado de datos y cambios de estado
- Es este caso la clave puede ser el ID del usuario y el valor los productos que ha solicitado

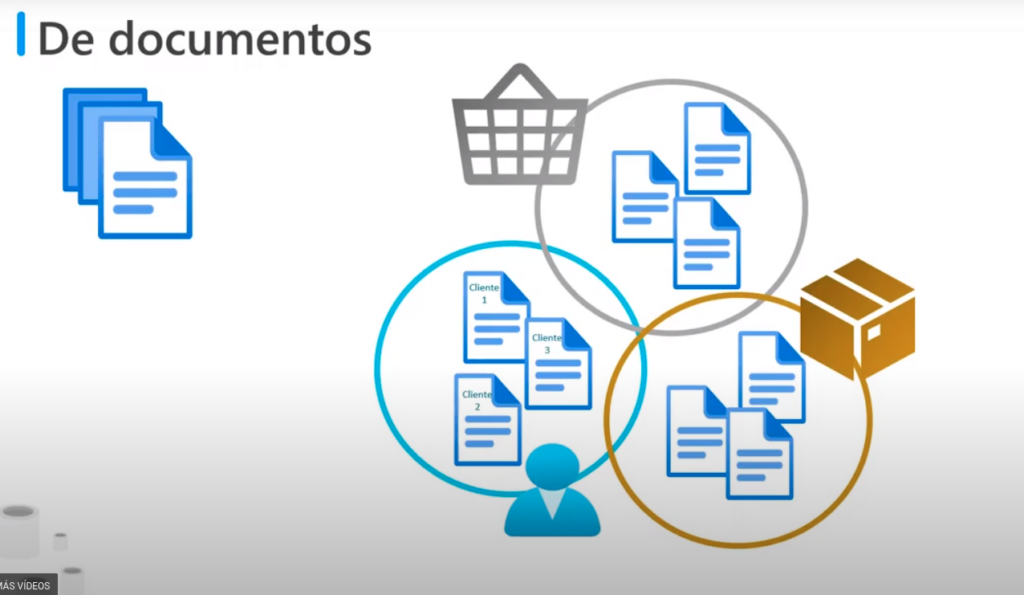
De documentos
- Una BD de documentos, almacena una colección de documentos
- donde cada documento consta de campos como nombre y datos
- Los documentos se recuperan mediante claves únicas
- Normalmente los documentos contienen los datos de una sola identidad como: un cliente, producto o un pedido
- No es necesario que los documentos tengan la misma estructura
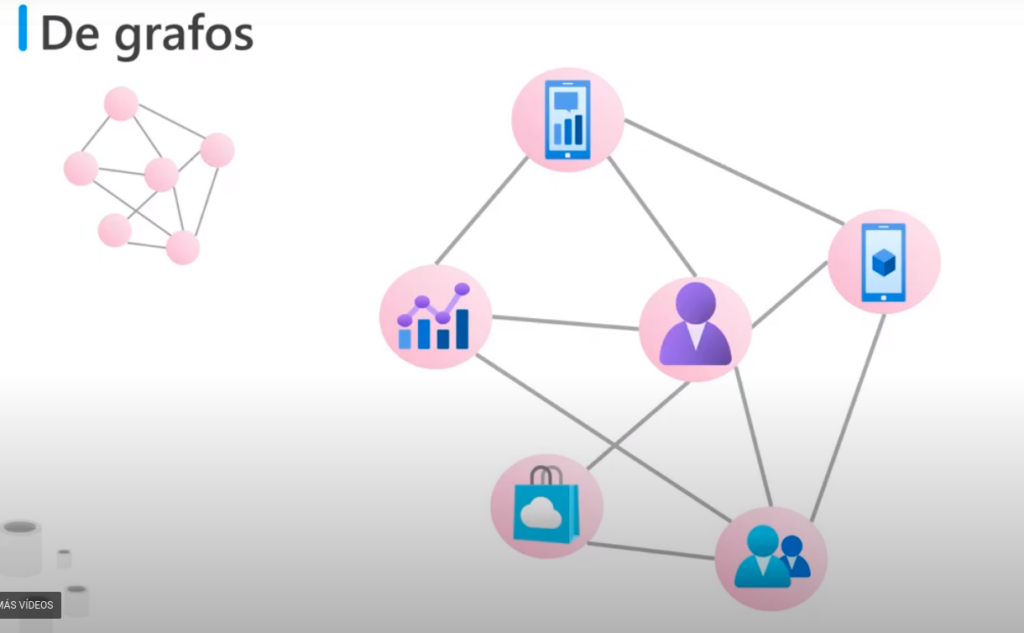
De grafos
- Una BD de grafos almacena dos tipos de información:
- Nodos
- Bordes: especifican las relación entre los nodos
- Esta estructura hace que sea fácil realizar consultas donde las relaciones son complejas
- Por ejemplo: es el análisis de relaciones entre los usuarios de las redes sociales o hábitos de compras de los clientes en las tiendas onlines
Familia de columnas
- Una BD de familias de columnas organiza los datos en filas y columnas, pero a diferencias de una BD relacional permite organizar los datos con un enfoque desnormalizado para estructurar datos dispersos
- Facebook messenger hace uso del sistema de ficheros de almacenamiento masivo de de datos, por lo que esta preparado para almacenar una enorme cantidad de información en tablas de manera que después pueda ser recuperada mediante consultas por rangos, es decir mediante consultas de columnas

Series temporales
- los almacenes de datos de series temporales son un conjunto de valores que se organizan por horas
- Recopilan grandes cantidades de datos en tiempo real a partir de una gran número de orígenes
- Normalmente tienen muchos registros y el total de los datos puede crecer rápidamente
- Ejemplo:
- cotizaciones bursátiles capturadas en el tiempo para detectar tendencias
- Datos de rendimiento de un servidor
Archivos compartidos
- Permiten acceder a los archivos a través de una red
- Permiten establecer la seguridad y mecanismos de control de acceso
- Permiten también permitir a los servicios distribuidos proporcionar un acceso para operaciones básicas como lectura y escritura
- Permite acceder al mismo archivo desde dos ubicaciones distintas, por ejemplo 2 desarrolladores que acceden a los mismos recursos desde dos ubicaciones distintas
Almacenamiento de objetos
- Esta optimizado para almacenar y recuperar objetos binarios grandes, como imágenes, archivos, transmisiones de vídeo y audio, objetos de datos de gran tamaño, documentos y imágenes de disco de una MV
- Ejemplos: sitios web estáticos o de consulta es decir que no requieren interacción del usuario o modificación constante de sus datos

Unidad 2: Exploración de Azure Blob Storage
Azure Blob Storage es un servicio que le permite almacenar grandes cantidades de datos no estructurados como objetos binarios grandes, o blobs, en la nube. Los blobs son una manera eficaz de almacenar archivos de datos en un formato optimizado para el almacenamiento basado en la nube, y las aplicaciones pueden leerlos y escribirlos mediante la API de Azure Blob Storage.
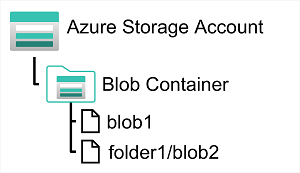
En una cuenta de Azure Storage, los blobs se almacenan en contenedores. Un contenedor proporciona una manera cómoda de agrupar blobs relacionados. Puede controlar quién puede leer y escribir blobs dentro de un contenedor en el nivel de contenedor.
Dentro de un contenedor, puede organizar los blobs en una jerarquía de carpetas virtuales, similares a los archivos de un sistema de archivos en un disco. Sin embargo, de manera predeterminada, estas carpetas no son más que una forma de utilizar un carácter «/» en el nombre de un blob para organizar los blobs en espacios de nombres. Las carpetas son puramente virtuales y no es posible hacer operaciones de nivel de carpeta para controlar el acceso ni hacer operaciones masivas.
Azure Blob Storage admite tres tipos de blobs diferentes:
- Blobs en bloques. Un blob en bloques se trata como un conjunto de bloques. Cada bloque puede tener un tamaño distinto, de hasta 100 MB. Un blob en bloques puede contener hasta 50 000 bloques, con un tamaño máximo de más de 4,7 TB. El bloque es la cantidad más pequeña de datos que se puede leer o escribir como una unidad individual. Los blobs en bloques se recomiendan especialmente para almacenar objetos binarios grandes discretos que cambian con poca frecuencia.
- Blobs en páginas. Un blob en páginas se organiza como una colección de páginas de tamaño fijo de 512 bytes. Un blob en páginas está optimizado para admitir operaciones de lectura y escritura aleatorias; puede capturar y almacenar datos para una sola página si es necesario. Un blob en páginas puede contener hasta 8 TB de datos. Azure usa blobs en páginas para implementar el almacenamiento de discos virtuales de las máquinas virtuales.
- Blobs en anexos. Un blob en anexos es un blob en bloques optimizado para admitir operaciones de anexión. Solo puede agregar bloques al final de un blob en anexos; no se admite la actualización o eliminación de bloques existentes. Cada bloque puede tener un tamaño distinto, de hasta 4 MB. El tamaño máximo de un blob en anexos es de algo más de 195 GB.
El almacenamiento de blobs proporciona tres niveles de acceso, que ayudan a equilibrar la latencia de acceso y el costo de almacenamiento:
- El nivel de acceso frecuente es el predeterminado. Este nivel se usa para los blobs a los que se accede con frecuencia. Los datos de blob se almacenan en medios de alto rendimiento.
- El nivel Esporádico tiene un rendimiento inferior e incurre en cargos de almacenamiento reducidos en comparación con el nivel Frecuente. Use el nivel de acceso esporádico para los datos a los que se accede con poca frecuencia. Es habitual que el acceso a los blobs recién creados sea más frecuente al principio y menos frecuente a medida que pasa el tiempo. En estas situaciones, puede crear el blob en el nivel de acceso frecuente, pero migrarlo al nivel de acceso esporádico más adelante. Puede migrar un blob del nivel de acceso esporádico al frecuente.
- El nivel Archivo proporciona el menor costo de almacenamiento, pero una mayor latencia. El nivel de acceso de archivo está pensado para los datos históricos que no deben perderse, pero que raramente se necesitan. Los blobs del nivel de acceso de archivo se almacenan de forma eficaz en un estado sin conexión. La latencia de lectura típica para los niveles de acceso frecuente y esporádico es de unos milisegundos, pero para el nivel de acceso de archivo los datos pueden tardar horas en estar disponibles. Para recuperar un blob desde el nivel de acceso de archivo, debe cambiar el nivel de acceso a acceso frecuente o esporádico. Con ello, el blob se rehidratará. Solo puede leer el blob una vez que se ha completado el proceso de rehidratación.
Puede crear directivas de administración del ciclo de vida para los blobs de una cuenta de almacenamiento. Una directiva de administración del ciclo de vida puede trasladar automáticamente un blob de acceso frecuente a acceso esporádico y, a continuación, al nivel de acceso de archivo, a medida que pasa el tiempo y se usa con menos frecuencia (la directiva se basa en el número de días transcurridos desde la última modificación). Una directiva de administración del ciclo de vida también puede organizarse para eliminar blobs obsoletos.
MCT: Video 3.1.3 Descripción de Azure Blob Storage
Blobs
- Muchas aplicaciones requieren almacenar objetos de datos binarios en la nube
- Como imágenes, audio y secuencias de vídeo

Tipo de blobs
Azure permite 3 tipos de blobs
Blob de bloques
- Es un conjunto de bloques
- Cada bloque puede tener un tamaño distinto
- Y es la cantidad más pequeña que se puede leer y escribir como una unidad individual
- Se recomiendan para almacenar objetos de datos binarios grandes, discretos y que cambian con poca frecuencia como imágenes y audio
Blob en páginas
- Se organizan como una colección de páginas del mismo tamaño (512Bytes)
- Esta optimizado para operaciones de lectura y escritura aleatorias
- Puede capturar o almacenar datos para una sola página si se requiere
- y puede contener hasta 8TB
- Azure utiliza esta forma para almacenar los discos duros de las MV’s
Blob en Anexos
- Es un blob optimizado para operaciones de anexión
- Solo se pueden agregar bloques al final
- No se permite la actualización o eliminación de un bloque existente
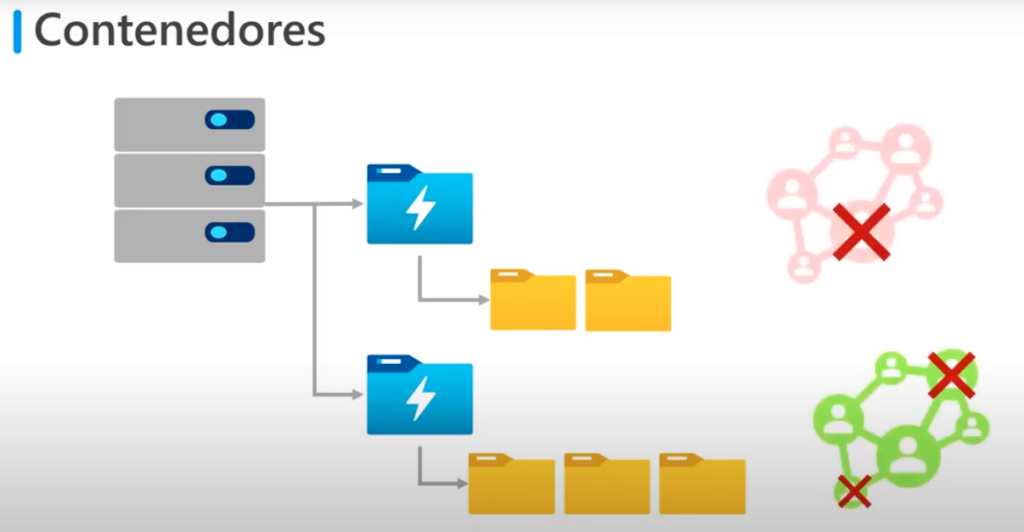
Contenedores
- Los blob se crean en contenedores
- Los contenedores proporcionan una forma cómoda de agrupar los blob’s relacionados y de organizarlos en una jerarquía de carpetas
- Gracias a esto puede configurar quien puede leer y escribir en cada nivel del contenedor
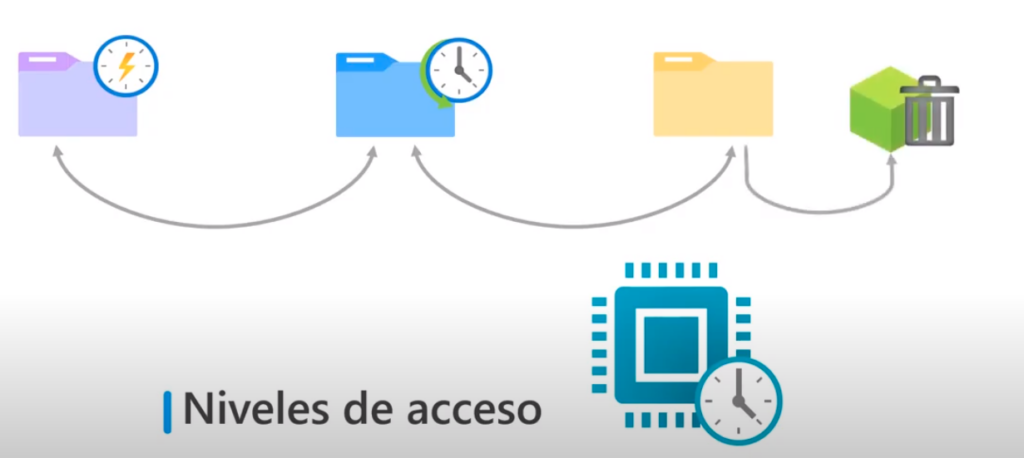
Niveles de acceso
El almacenamiento de blob’s proporciona 3 niveles de acceso que ayudan a equilibrar la latencia y el costo
Frecuente:
- Nivel predeterminado
- Los datos se almacenan en medios de alto rendimiento
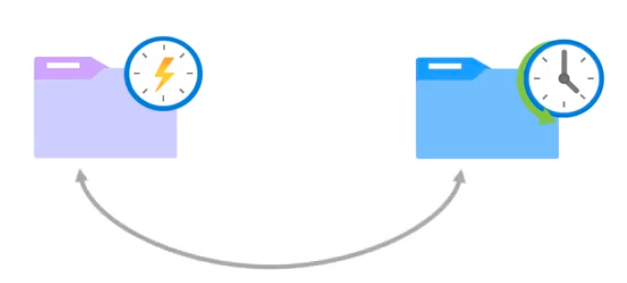
Esporádico:
- Tiene un rendimiento y costo menor
- Se utiliza para los datos que se acceden con poca frecuencia
- Se puede crear el acceso frecuente y migrarlo luego a esporádico y viceversa
Acceso de archivo
- Proporciona el menor costo para a una mayor latencia
- Esta pensado para los datos históricos que no deben perderse pero que rara vez se utilizan
- Para recuperar blob de este tipo primero debe convertirlo a frecuente o esporádico
- También se pueden crear directivas para los ciclos de vida de los blob’s
- Una directiva de administración puede cambiar automáticamente un blob de frecuente a esporádico y luego a acceso de archivo a medida que pasa el tiempo y se utiliza con menor frecuencia
- La directiva se basaría en el tiempo transcurrido desde la última modificación
- Una directiva también se puede crear para eliminar los blobs obsoletos
Ventajas
- Control de versiones: se pueden restablecer versiones anteriores de un blob
- Eliminación temporal: permite recuperar un blob que se ha eliminado o se ha sobreescrito
- Instantánea: es una versión de solo lectura de un blob en un momento determinado
- Fuente de cambios: proporciona un registro ordenado de solo lectura de actualizaciones realizadas en un blob, se utiliza para supervisar cambios y realizar operaciones como:
- Extraer métricas e información de análisis de negocio
- Almacenar, auditar y analizar cambios del objeto en un periodo de tiempo por seguridad, cumplimiento normativo o inteligencia de administración de datos empresariales
- Crear soluciones para las copias de seguridad el reflejado o las replicaciones del estado de los objetos para la administración de desastres o el cumplimiento
- Crear canalizaciones de aplicaciones conectadas para que reaccionen a eventos de cambio o para que programen ejecuciones basadas en objetos creados o modificados
- Garantiza la disponibilidad Azure Blob Storage brinda redundancia, estos siempre se replican 3 veces en la región en que se creó la cuenta, pero también se puede configurar para crear la redundancia en una segunda región por un costo adicional

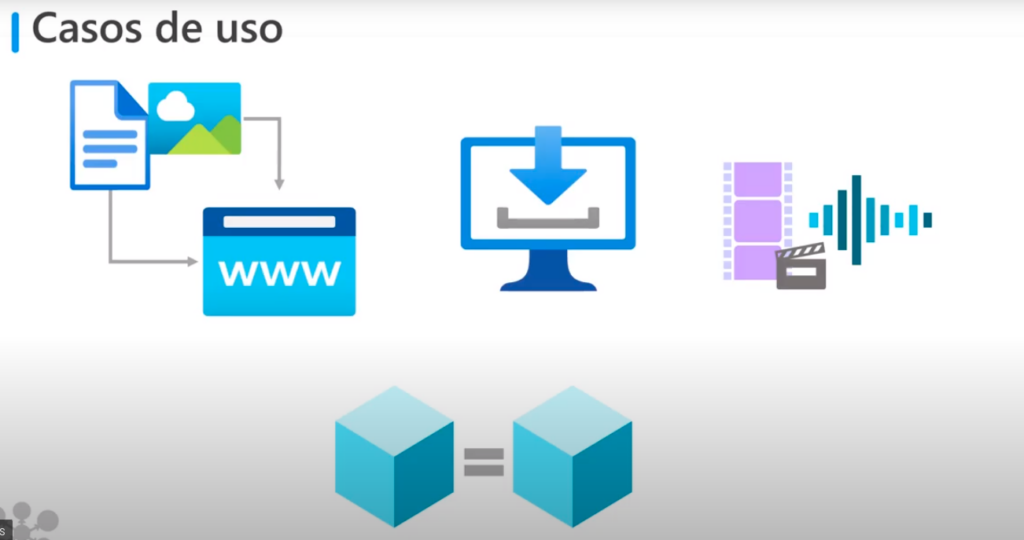
Casos de uso
- Suministrar imágenes o documentos a un sitio web estático (es decir que aquellos que están enfocados a brindar información y no a una interacción con el usuario)
- Almacenar archivos para el acceso distribuido
- Realizar streaming de audio y vídeo
- Almacenar datos para copias de seguridad, recuperación ante desastres, archivado o para el análisis realizado por un servicio local u hospedado por Azure
Azure Blob Storage carga de archivo desde portal
- Para aprovisionar el servicio
- Primero debemos crear una cuenta de almacenamiento y un grupo de recursos (Estos ya fueron creados)

- Ingresamos en la cuenta de almacenamiento
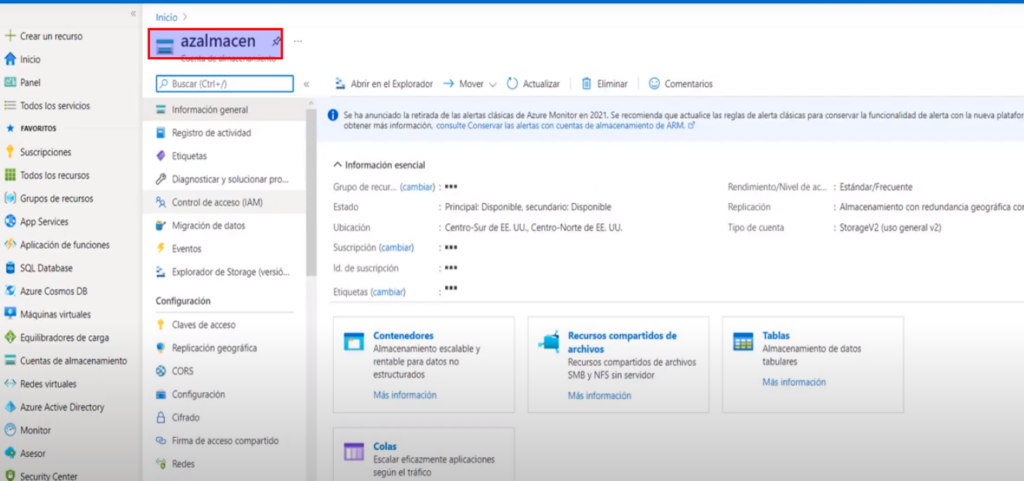
- Ingresamos al área de «CONTENEDORES»
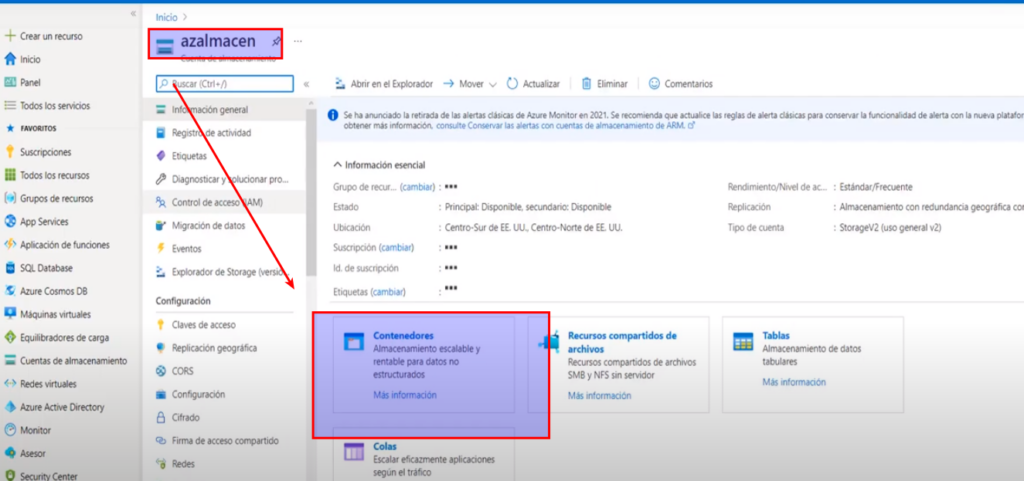
- Damos clic en agregar contenedor
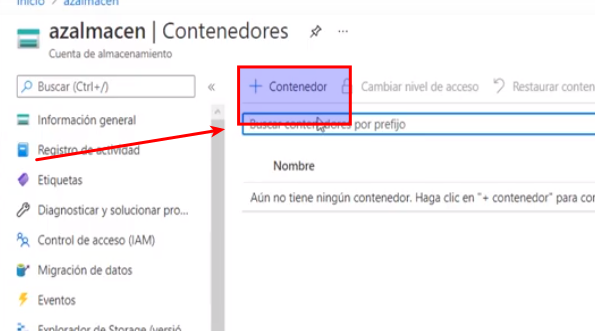
- Le asignamos un nombre (Solo minúsculas) y le damos crear
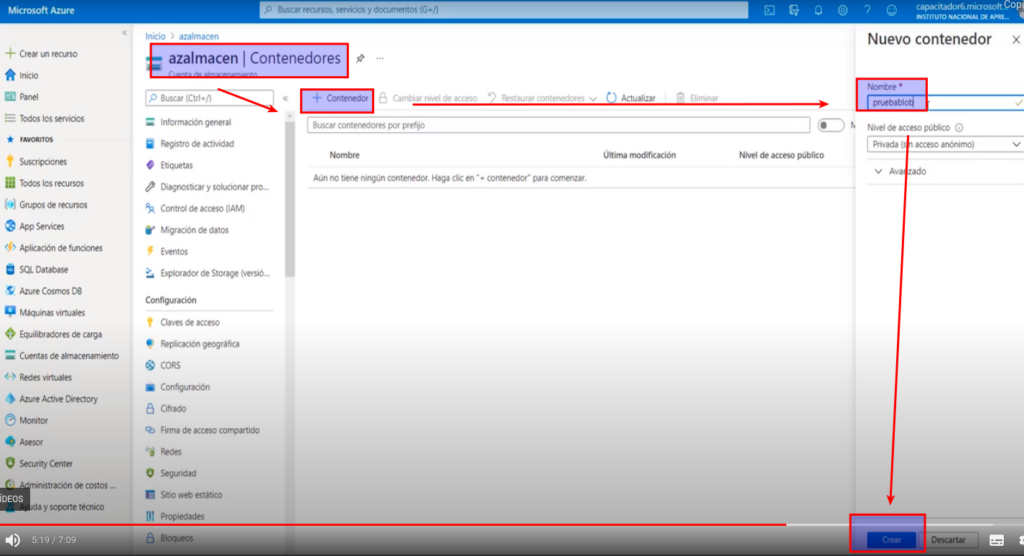
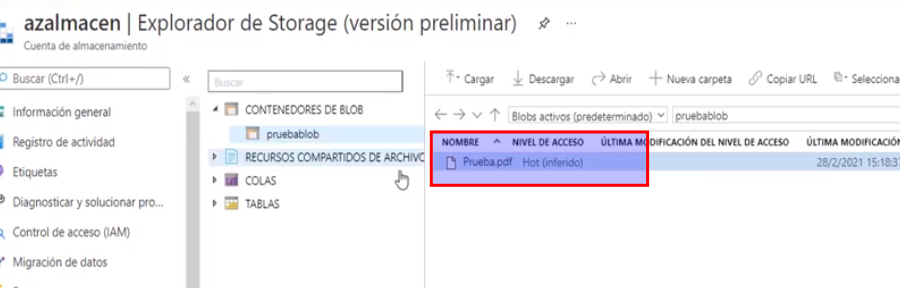
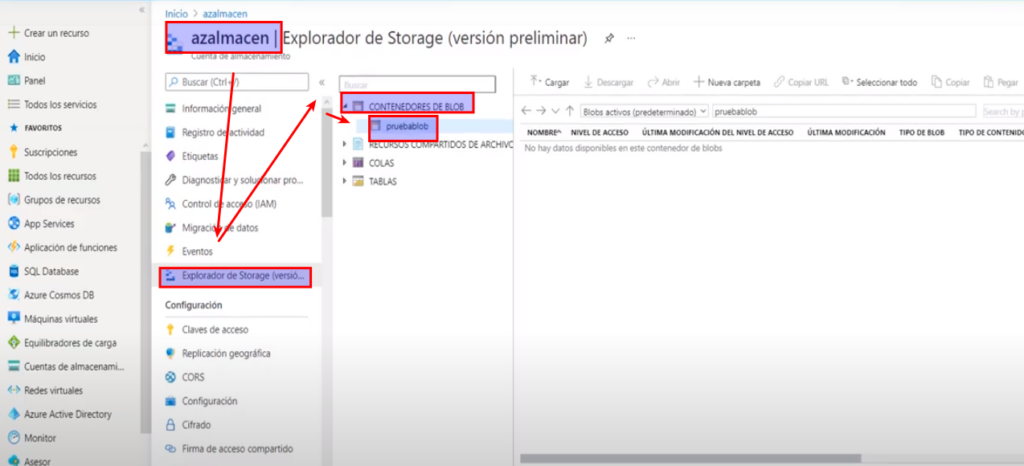
- Para verificar la creación ingresamos a «Explorador de Storage»
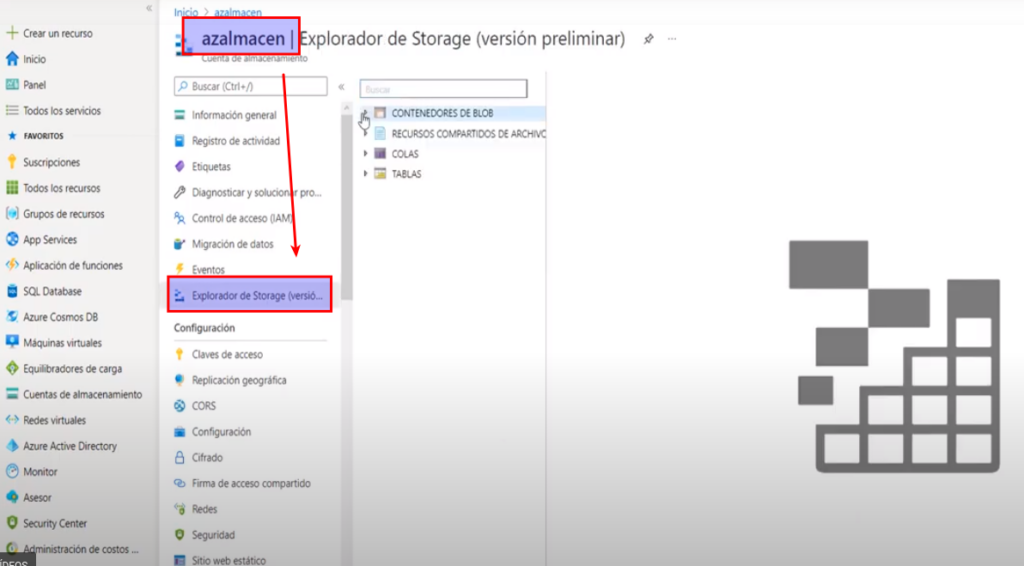
- Y dentro de «Contenedores de Blob» podemos ver que se creó correctamente
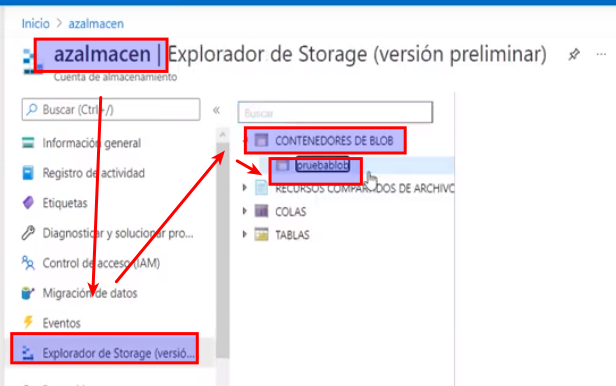
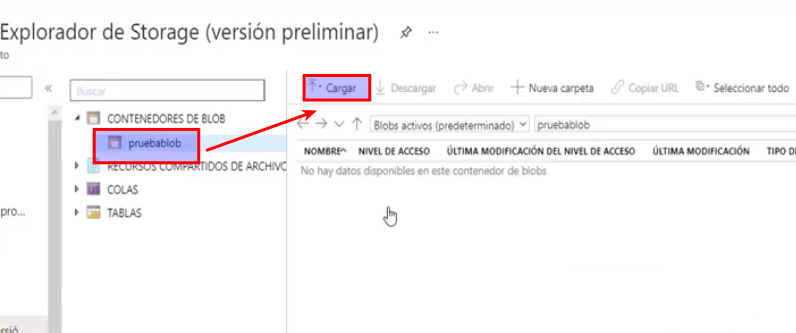
- Para cargar un archivo, damos clic en «Cargar»
- Seleccionamos el archivo y le damos cargar
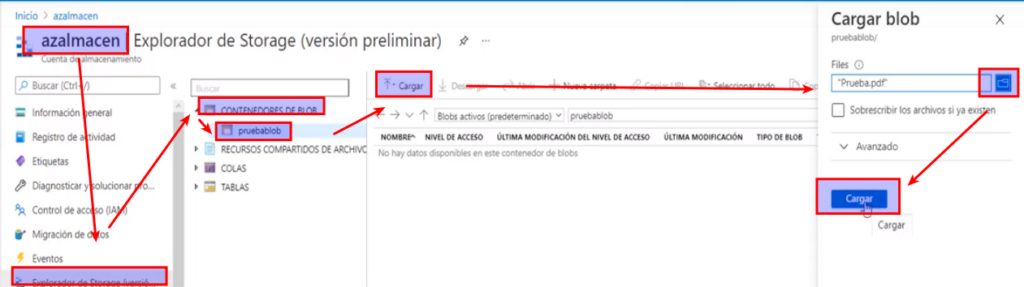
- Ahora podemos verificar que el archivo se encuentra dentro del contenedor
Azure Blob Storage carga de archivo desde CLI
- Ingresamos al shell
- Se debe tener la cuenta de almacenamiento y grupo de recursos creados
- Para la creación del blob se deben ejecutar las siguientes instrucciones
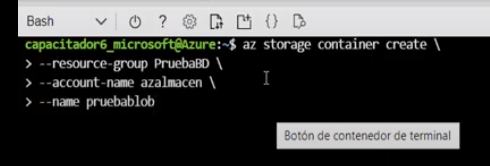
- az storage conatainer create: indica que se va a crear un nuevo contenedor
- –resource-group: indica el grupo de recursos
- –account-name: indica la cuenta de almacenamiento
- –name: nombre del contenedor
- Se muestra un mensaje de advertencia pero se crear correctamente

- Podemos verificar la creación desde el portal en
Unidad 3: Exploración de Azure Data Lake Storage Gen2
Azure Data Lake Store (Gen1) es un servicio independiente para el almacenamiento jerárquico de los datos de lagos de datos analíticos que, con frecuencia, usan las denominadas soluciones de análisis de macrodatos que funcionan con datos estructurados, semiestructurados y no estructurados, almacenados en archivos. Azure Data Lake Storage Gen2 es una versión más reciente de este servicio que se integra en Azure Storage; permite aprovechar la escalabilidad del almacenamiento en blobs y el control de costos de los niveles de almacenamiento, combinado con las capacidades del sistema de archivos jerárquico y la compatibilidad con los principales sistemas de análisis de Azure Data Lake Store.
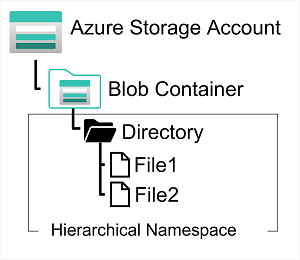
Sistemas como Hadoop en Azure HDInsight, Azure Databricks y Azure Synapse Analytics pueden montar un sistema de archivos distribuido hospedado en Azure Data Lake Store Gen2 y usarlo para procesar grandes volúmenes de datos.
Para crear un sistema de archivos de Azure Data Lake Store Gen2, debe habilitar la opción Espacio de nombres jerárquico de una cuenta de Azure Storage. Puede hacerlo al crear inicialmente la cuenta de almacenamiento, o bien puede actualizar una cuenta de Azure Storage ya existente para que admita Data Lake Gen2. Sin embargo, tenga en cuenta que la actualización es un proceso unidireccional: después de actualizar una cuenta de almacenamiento para que admita un espacio de nombres jerárquico de almacenamiento de blobs, no se puede revertir a espacio de nombres plano.
Unidad 4: Explorar Azure Files
Muchos sistemas locales que comprenden una red de equipos internos usan recursos compartidos de archivos. Un recurso compartido de archivos permite almacenar un archivo en un equipo y conceder acceso a ese archivo a los usuarios y las aplicaciones que se ejecutan en otros equipos. Esta estrategia puede funcionar bien para los equipos de la misma red de área local, pero no se escala correctamente a medida que aumenta el número de usuarios, o si los usuarios se encuentran en sitios diferentes.
En esencia, Azure Files es una manera de crear recursos compartidos de red basados en la nube, como suelen encontrarse en organizaciones locales para que los documentos y otros archivos estén a disposición de varios usuarios. Al hospedar recursos compartidos de archivos en Azure, las organizaciones pueden eliminar los costos de hardware y la sobrecarga de mantenimiento, y beneficiarse de la alta disponibilidad y el almacenamiento escalable en la nube para los archivos.
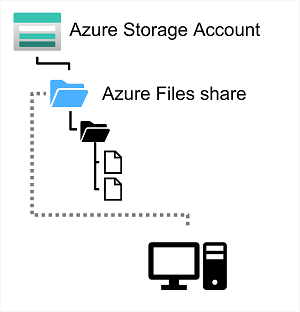
Azure File Storage se crea en una cuenta de almacenamiento. Azure Files le permite compartir hasta 100 TB de datos en una sola cuenta de almacenamiento. Estos datos se pueden distribuir en cualquier número de recursos compartidos de archivos de la cuenta. El tamaño máximo de un solo archivo es de 1 TB, pero puede establecer cuotas para limitar el tamaño de cada recurso compartido por debajo de esta cifra. Actualmente, Azure File Storage admite hasta 2000 conexiones simultáneas por cada archivo compartido.
Una vez que crea una cuenta de almacenamiento, puede cargar archivos en Azure File Storage mediante Azure Portal, o bien mediante herramientas como la utilidad AzCopy. Asimismo, puede usar el servicio Azure File Sync para sincronizar las copias almacenadas localmente en caché de archivos compartidos con los datos de Azure File Storage.
Azure File Storage ofrece dos niveles de rendimiento. El nivel Estándar usa hardware basado en disco duro en un centro de datos y el nivel Premium usa discos de estado sólido. El nivel Premium ofrece un mayor rendimiento, pero se cobra a una tarifa superior.
Azure Files admite dos protocolos comunes de uso compartido de archivos de red:
- El uso compartido de archivos Bloque de mensajes del servidor (SMB) se utiliza generalmente entre varios sistemas operativos (Windows, Linux, macOS).
- Los recursos compartidos Network File System (NFS) los utilizan algunas versiones de Linux y macOS. Para crear un recurso compartido NFS, debe usar una cuenta de almacenamiento de nivel Premium y crear y configurar una red virtual a través de la cual se pueda controlar el acceso al recurso compartido.
MCT: Video 3.1.4 Descripción de Azure File Storage
Azure File Storage
- Permite crear recursos de archivos compartidos en la nube y acceder a ellos desde una conexión a Internet
- Para esto utiliza los protocolos de:
- Bloque de mensajes del servidor (SMB – Server Message Block): es un protocolo de red que permite compartir archivos entre los nodos de una red que comparten el mismo Sistema Operativo Windows
- Un recurso compartido permite almacenar un archivo en un equipo y conceder acceso a este archivo a usuarios y aplicaciones que se ejecutan en otros equipos
- Permite compartir hasta 100TB de datos bajo una misma cuenta de alamcenamiento
- El tamaño máximo de un archivo es de 1TB
- Ofrecen dos niveles de rendimiento:
- Estándar: que se basa en discos duros mecánicos
- Premium: que utiliza discos de estado solido que dan un mejor rendimiento pero una tarifa superior

Casos de uso
- Migrar aplicaciones existentes a la nube sin tener que aprovisionar MV
- Compartir datos entre un servidor local y uno en la nube como archivos de registro, datos de eventos y copias de seguridad
- Se pueden integrar las aplicaciones heredadas por aplicaciones modernas en la nube
- O desarrollar nuevas aplicaciones basadas en archivos compartidos
- Se ofrece disponibilidad continua lo que permite alojar aplicaciones como SQL Server con datos almacenados en la cuenta de archivos compartidos
- Es importante no utilizar Azure File Storage para archivo que requieren acceso simultaneo (Que se necesite escribir al mismo tiempo)

Ejemplo práctico
- Es el desarrollo de pruebas y depuración ya que cuando los desarrolladores o administradores están trabajando en MV, a menudo requieren diversas herramientas o utilidades copiar estas utilidades en cada MV puede ser una tarea que requiera mucho tiempo, pero mediante el montaje de un recurso compartido en la nube solventa la situación

Ventajas
- Es un servicio totalmente administrado es decir los recursos se pueden crear sin la necesidad de administrar el hardware ni el SO
- Los datos compartidos se replican localmente dentro de una región pero también se puede hacer en otra
- Todos los datos se cifran en reposo y se puede habilitar el cifrado para los datos en transito

Azure File Storage: aprovisionar desde el portal de Azure
- Es necesario contar con una cuenta de almacenamiento (Ya se cuenta creada)
- Primero acedemos a la cuenta de almacenamiento
- Luego buscamos la opción de «Recursos Compartidos de Archivos»
- Y damos clic en «Agregar Recurso compartido de archivos»
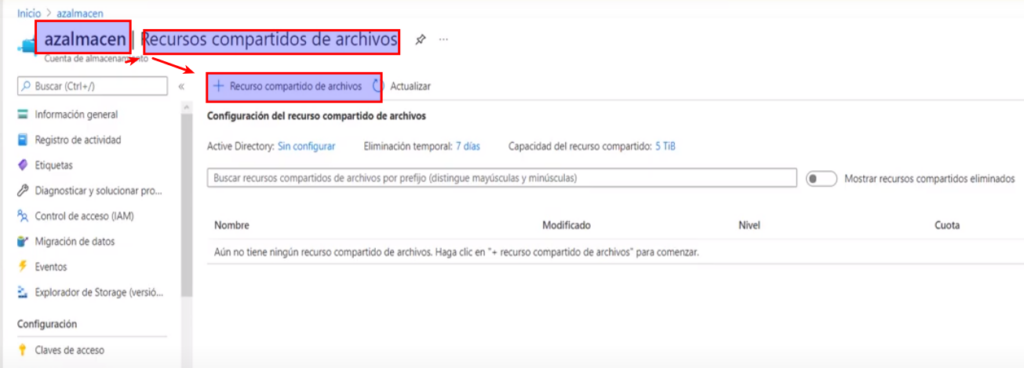
- Le asignamos un nombre y como nivel «esporádico» (esto determina el costo del servicio) y damos clic en crear
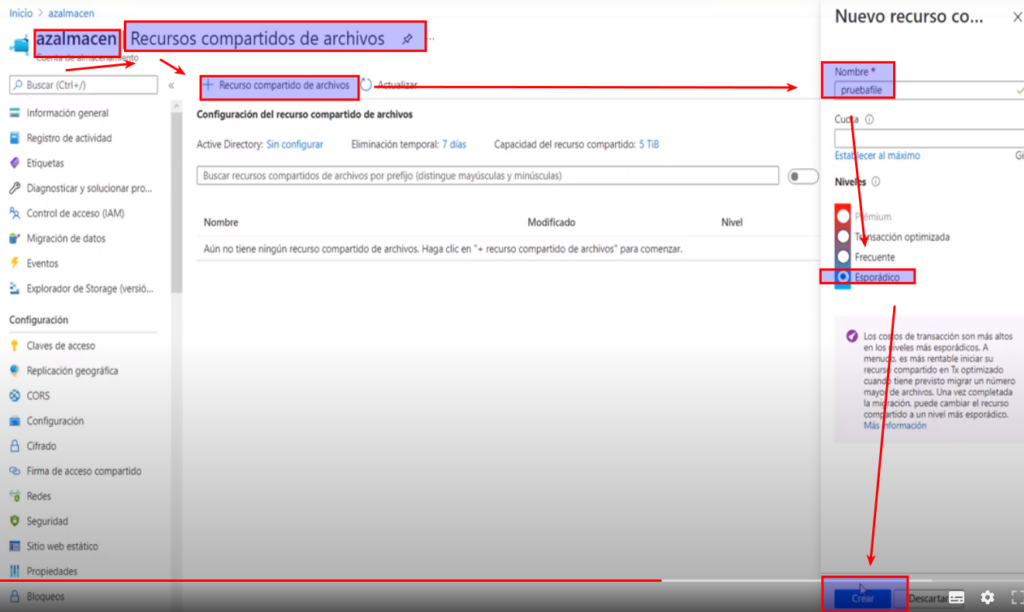
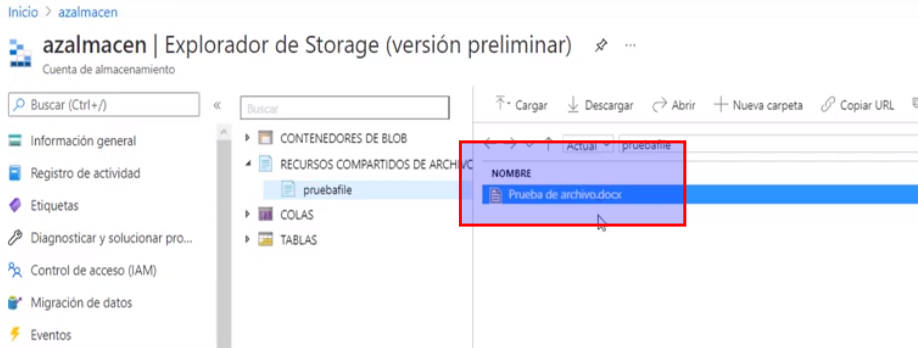
- Para comprobar que el almacenamiento se creó correctamente vamos a la opción de «Explorador de Storage» y en la sección de «Recursos Compartidos» podemos ver que se creó correctamente
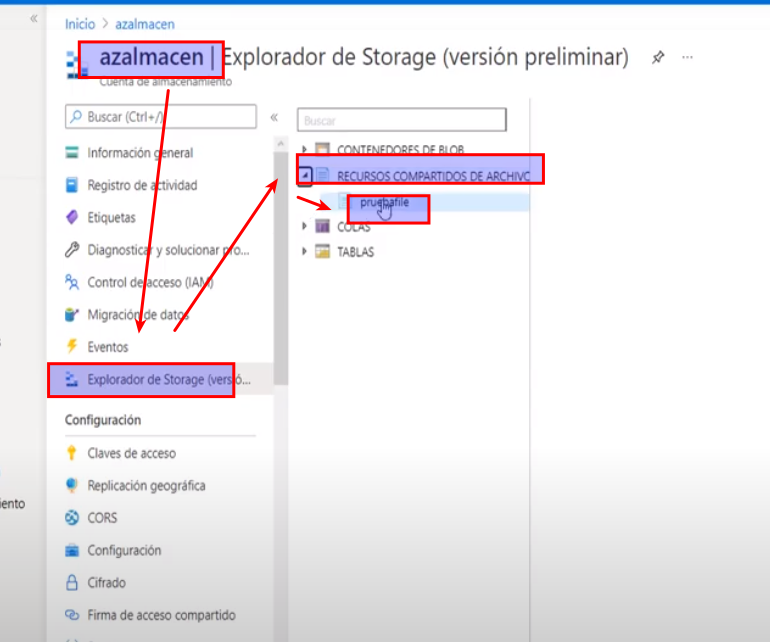
- Para cargar un archivo le damos en cargar seleccionamos el archivo y damos clic en cargar
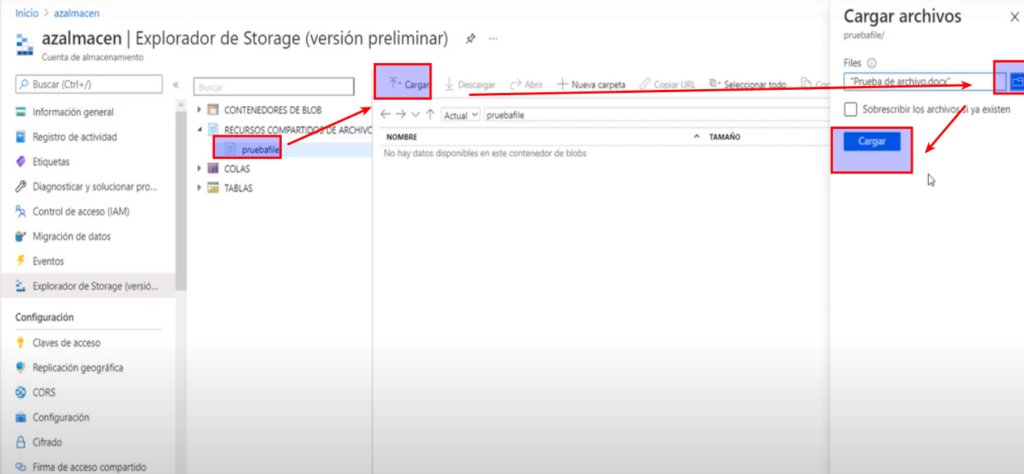
- Y podemos verificar que el archivo se cargo correctamente
Azure File Storage: aprovisionamiento desde la CLI
- Debemos tener una cuenta de almacenamiento creada
- Ingresamos a la shell
- Escribimos las siguientes instrucciones
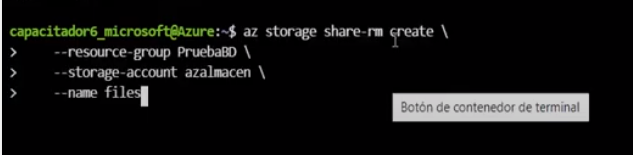
- az storage share-rm create: indica que se va a crear un servicio de archivos compartidos
- –resource-group: grupo de recursos
- –storage-account: cuenta de almacenamiento
- –name: nombre del servicio de archivos compartidos
- El resultado nos indica cada uno de los valores que se le dieron al servicio
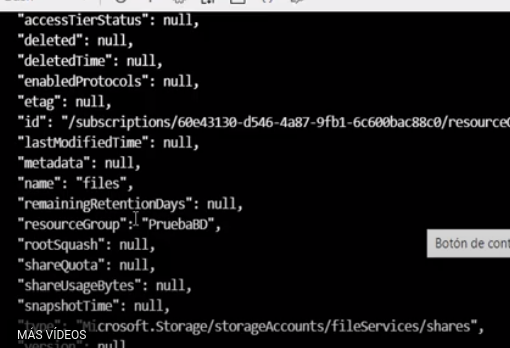
- Para comprobar que el servicio se creó correctamente ingresamos a la cuenta de almacenamiento -> Explorador de Storage -> Recursos compartidos podemos verificar
Unidad 5: Exploración de tablas de Azure
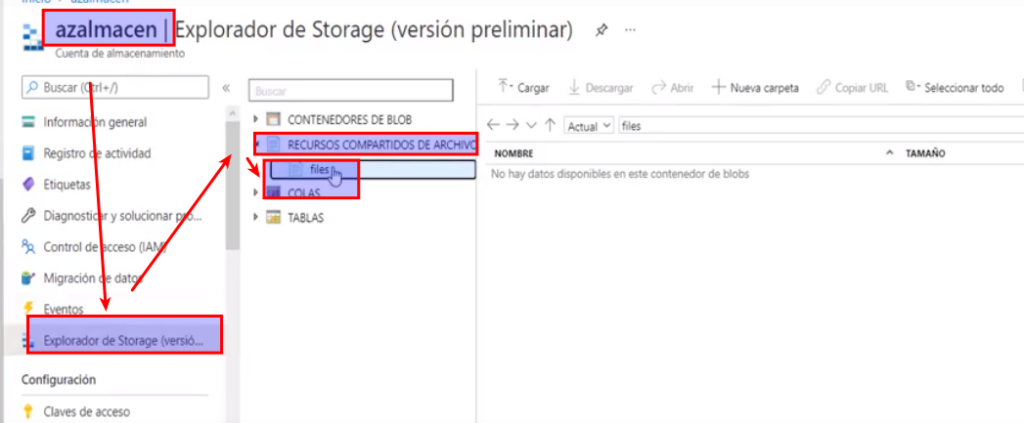
Azure Table Storage es una solución de almacenamiento NoSQL que usa tablas que contienen elementos de datos de clave-valor. Cada elemento se representa mediante una fila que contiene columnas para los campos de datos que deben almacenarse.
Sin embargo, no se confunda al pensar que una tabla de Azure Table Storage es como una tabla de una base de datos relacional. Una tabla de Azure le permite almacenar datos semiestructurados. Todas las filas de una tabla deben tener una clave única (compuesta de una clave de partición y una clave de fila) y, al modificar los datos de la tabla, una columna de marca de tiempo registra la fecha y la hora en las que se realizó la modificación; pero, aparte de eso, las columnas de cada fila pueden variar. Las tablas de Azure Table Storage no tienen los conceptos de claves externas, relaciones, procedimientos almacenados, vistas u otros objetos que puede encontrar en una base de datos relacional. Normalmente, los datos en Azure Table Storage se desnormalizan y cada fila contiene los datos completos de una entidad lógica. Por ejemplo, una tabla que contiene información de clientes podría almacenar el nombre, el apellido, uno o varios números de teléfono, y una o varias direcciones de cada cliente. El número de campos de cada fila puede ser diferente, en función de la cantidad de números de teléfono y direcciones de cada cliente, y de los detalles registrados para cada dirección. En una base de datos relacional, esta información se dividiría en varias filas de varias tablas.
Para garantizar que el acceso sea rápido, Azure Table Storage divide una tabla en particiones. La creación de particiones es un mecanismo para agrupar filas relacionadas según una propiedad común o clave de partición. Las filas que comparten la misma clave de partición se almacenarán juntas. Además de ayudar a organizar los datos, la creación de particiones también puede mejorar la escalabilidad y el rendimiento de las siguientes formas:
- Las particiones son independientes entre sí, y pueden agrandarse o reducirse a medida que se agregan o se quitan filas de una partición. Una tabla puede contener cualquier número de particiones.
- Al buscar datos, puede incluir la clave de partición en los criterios de búsqueda. Esto ayuda a reducir el volumen de datos que se va a examinar y mejora el rendimiento, ya que reduce la cantidad de E/S (operaciones de entrada y salida o lecturas y escrituras) necesaria para localizar los datos.
La clave de una tabla de Azure Table Storage consta de dos elementos: la clave de partición, que identifica la partición que contiene la fila, y una clave de fila, que es única para cada fila de la misma partición. Los elementos de una misma partición se almacenan en el orden de las claves de fila. Si una aplicación agrega una nueva fila a una tabla, Azure garantiza que la fila se coloca en la posición correcta de la tabla. Este esquema permite que una aplicación realice rápidamente consultas de punto, que identifican una sola fila, y consultas por rango, que capturan un bloque contiguo de filas en una partición.
MCT: Video 3.1.2 Descripción de Azure Table Storage
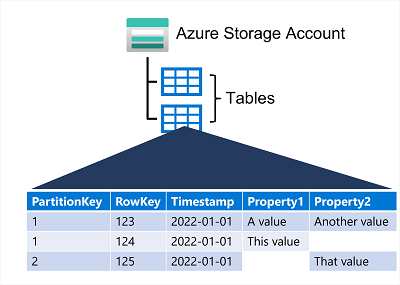
Clave – Valor
- Azure Table Storage implementa el modelo clave-valor de NoSQL
- En este modelo los datos se almacenan como un conjunto de campos y el elemento se identifica con una clave única
- Los elementos se conocen como filas y los campos se denominan columnas
- Pero no es como una tabla de una BD relacional
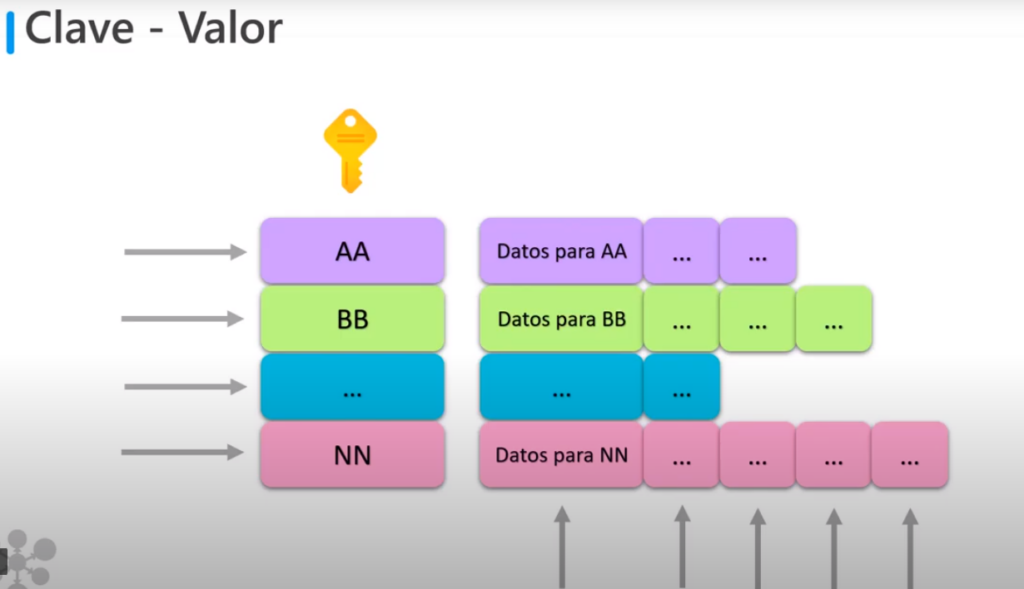
Azure Table Storage
- No tiene ningún concepto de relaciones
- Permite almacenar datos semiestruturados
- todas las filas deben tener una clave
- Y las columnas de cada fila pueden variar
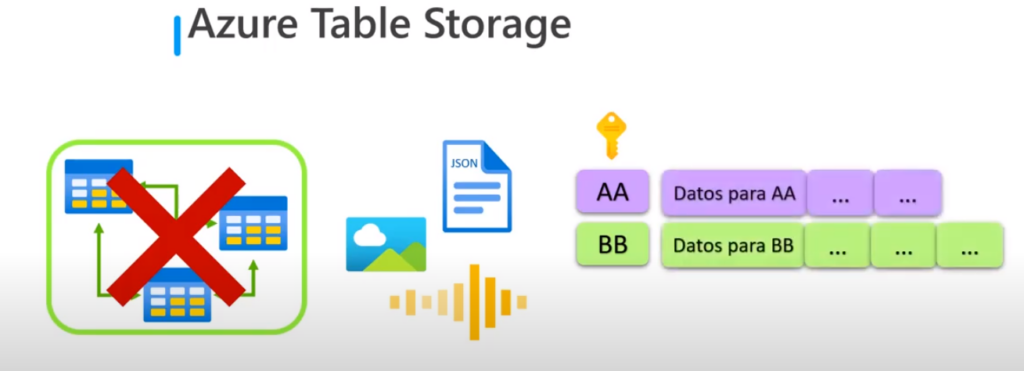
Acceso de datos
- El acceso de datos se realiza a través de particiones
- Que es un mecanismo de agrupación de filas según la propiedad o clave
- Cada partición es independiente entre sí
- La clave de una Azure Table Storage consta de 2 elementos:
- Clave de la partición: que identifica la partición que contiene la fila
- Clave de fila: que es única para cada fila de una partición
- Los elementos de una partición se almacenan en el orden de las claves de la fila
- Este esquema permite que una aplicación realice rápidamente consultas de punto que identifican una sola fila
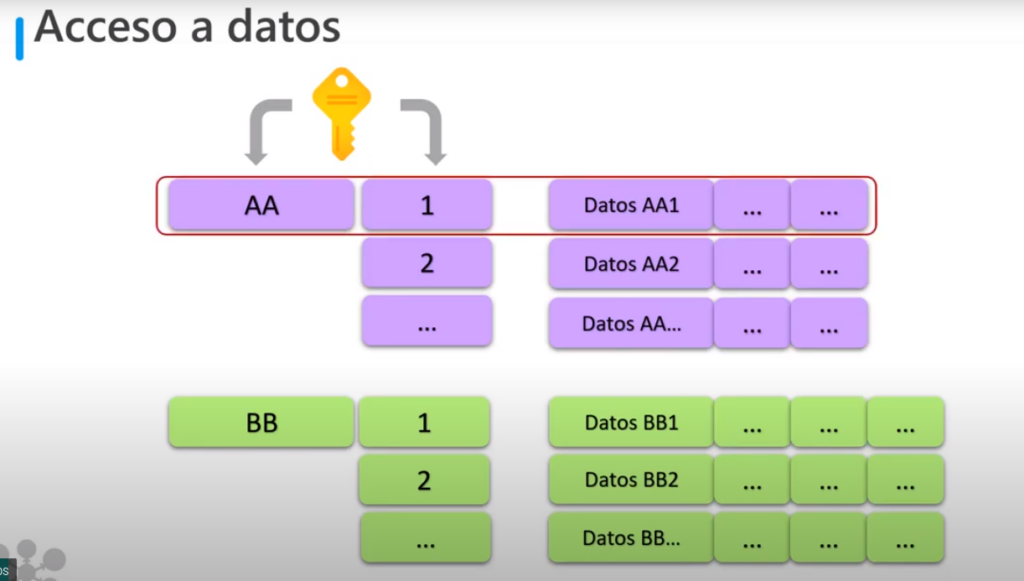
- Y consultas de rango que capturan un grupo de filas continuó en una partición

Datos
- Las columnas de una tabla pueden contener valores numéricos / Cadena / Binarios de hasta 64KB
- Lata tabla puede tener hasta 252 columnas ademas de la clave de fila y partición
- El tamaño máximo de las filas es de 1 MB
- Y los más importante es elegir correctamente las claves de fila-partición

Ejemplo
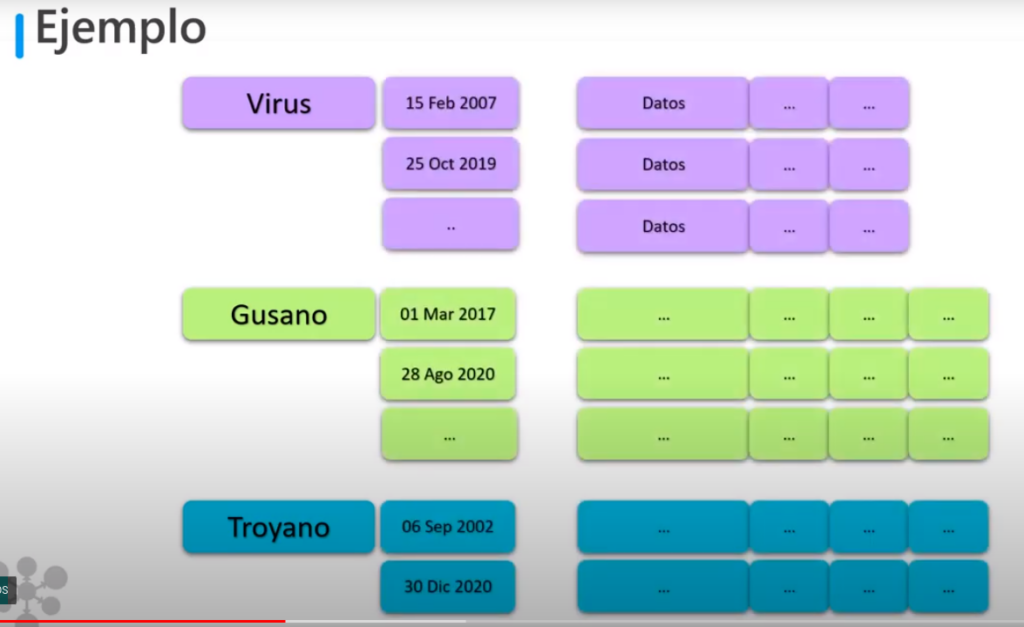
- Una organización de seguridad informática estudia los ciberataques que son reportados por varias empresas, para ellos se lleva un registro donde los ataques se clasifican por tipo y fecha
- cada uno es distinto por lo que la información a almacenar es distinta para cada uno
- Se pueden guardar archivos, imágenes, audios, etc
- Esto se puede almacenar en Azure Table Storage con la siguiente estructura
- La clave de la partición es el tipo de ciberataque
- Y la clave de la fila es la fecha
- Y cada partición permite almacenar distintos datos
Ventajas
- Es fácil de escalar
- Se tarda el mismo tiempo en insertar datos en una tabla vacía que en una tabla como miles de millones de registros
- Una cuenta de almacenamiento de Azure puede almacenar hasta 500TB de datos
- No es necesario asignar y mantener las relaciones complejas que se deben tener en una BD relacional
- La inserción de filas es rápida
- La recuperación de datos también es rápida si se brinda la clave de fila y partición como criterios de búsqueda
- Esta diseñado para manejar grandes volúmenes de datos con hasta cientos de TB’s
- Ofrece garantías de alta disponibilidad en una sola región, los datos se replican hasta 3 veces en la misma región, pero también lo puede configurar para tener redundancia en otra zona geográfica pero con un precio
- Permite proteger los datos ya que puede configurar la seguridad y control de acceso basado en roles RBAC

Desventajas
- Se debe tener en cuenta la coherencia de los datos ya que no esta restringido como en las BD relacionales
- No hay integridad referencial lo que quiere decir que cualquier relación entre filas debe mantenerse en forma externa a la tabla
- Es difícil filtrar y ordenar los datos que no son claves, las consultas que se realizan en función de campos que no son clave pueden dar lugar a recorridos de la tabla completa
Casos de uso
- Útil para almacenar terabytes de datos no estructurados, por ejemplo
- catálogos de productos para aplicaciones de comercio electrónico e información de clientes
- Donde los datos se pueden identificar y ordenar rápidamente mediante una clave
- Para almacenar conjuntos de datos que no requieren combinaciones complejas, claves externas o procedimientos almacenados y que se puedan desnormalizar para un acceso rápido
- Sistema de IoT, donde puede recuperar datos desde un sensor, como datos de rendimiento y registro de eventos
Azure Table Storage: aprovisionamiento desde el portal
- Se debe tener una cuenta de almacenamiento
- Luego ingresamos al cuenta de almacenamiento, e ingresamos a tablas
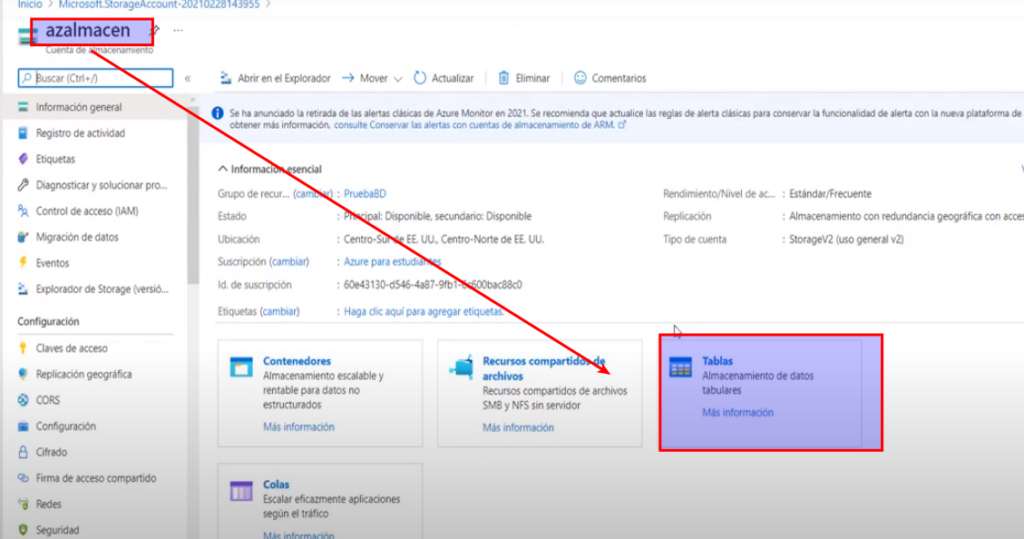
- Le damos a agregar tabla
- Le damos un nombre y Aceptar
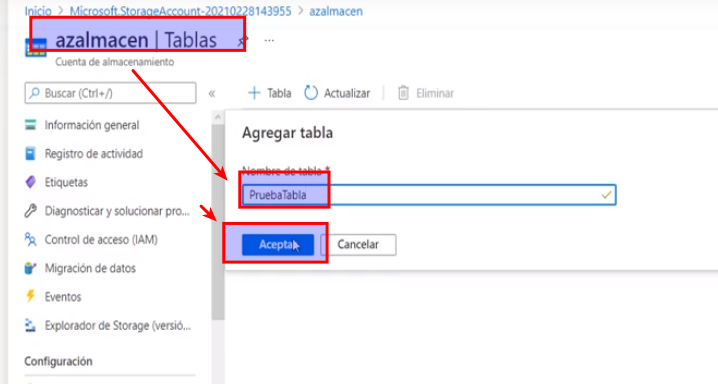
- Para verificar que se creó correctamente vamos a la cuenta de almacenamiento -> Explorador de Storage -> Tablas
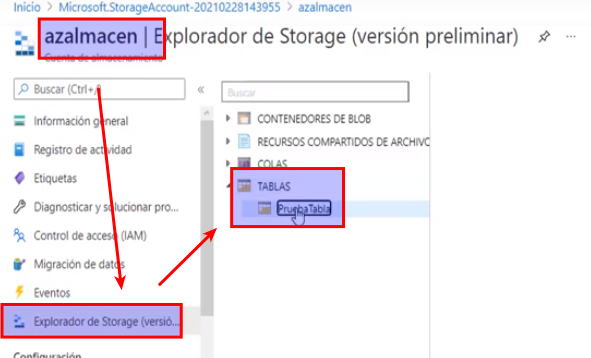
Azure Table Storage: Aprovisionamiento desde CLI
- Abrimos la shell y seleccionamos «PowerShell»
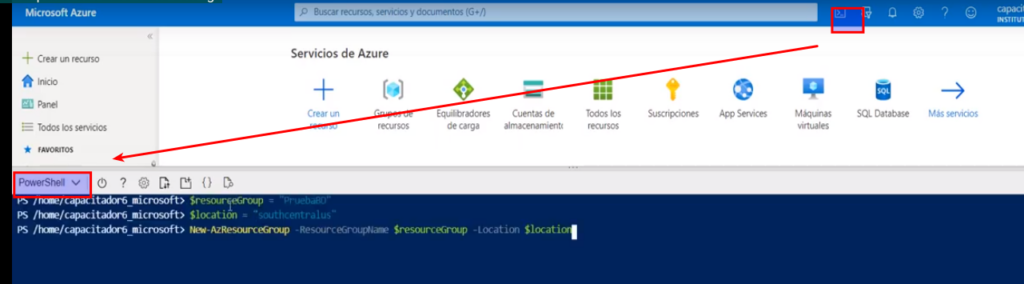
- Ejecutamos los siguientes comandos

- El signo de «$» nos permite definir una variable y asignarle un valor
- $resourceGroup: grupo de recursos
- $lacation: ubicación geográfica
- New-AzResourceGroup: nos permite crear el grupo de recursos
- Luego creamos la cuenta de alamacenamiento

- $storageAccountName: variable con el nombre del la cuenta de almacenamiento
- New-AzStorageAccount: crea la cuenta de almacenamiento
- –ResourceGroupName: nombre del grupo de recursos
- –name: nombre de la cuenta
- –Location: ubicación
- -SkuName: indica el tipo de replicación, en este caso redundancia local
- -King: es el tipo en este caso storage (de uso general)
- Luego ejecutamos

- Donde vamos a almacenar todo el contexto de la cuenta de almacenamiento
- Luego ejecutamos

- $tablenam: nombre de la tabla
- New-AzStorageTable: crea la tabla de almacenamiento
- –name: nombre
- –Context: contexto
- Se crea la tabla

- Para verificar que se creó correctamente vamos a la cuenta de almacenamiento -> Explorador de Storage -> Tablas
MCT: Video 3.1.5 Profundización y configuración Azure Storage
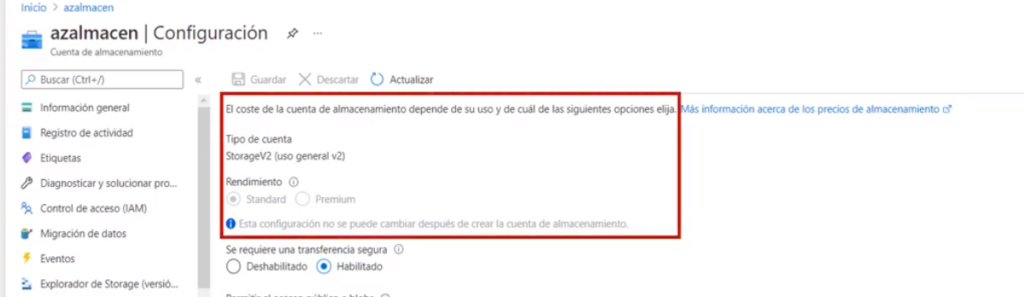
Configuración de la cuentas de Storage
- La sección de configuración de las cuentas de almacenamiento permite
- Habilitar o deshabilitar las conexiones seguras y por defecto todas van por HTTPS y puede deshabilitar el cifrado aun que no se recomienda
- Puede cambiar el nivel de acceso entre esporádico o frecuente
- Cambiar la forma como se replica la cuenta
- Habilitar o deshabiliar la integración de Azure Active Directory para las solcitudes para acceder a los archivos compartidos
- Puede consultar el tipo de cuenta y nivel de rendimiento (no se puede modificar)
Configuración del cifrado
- Todos los datos incluidos en una cuenta de Azure Storage son cifrados
- De forma predetermina se cifran con las claves de cifrado que son propiedad de Microsoft
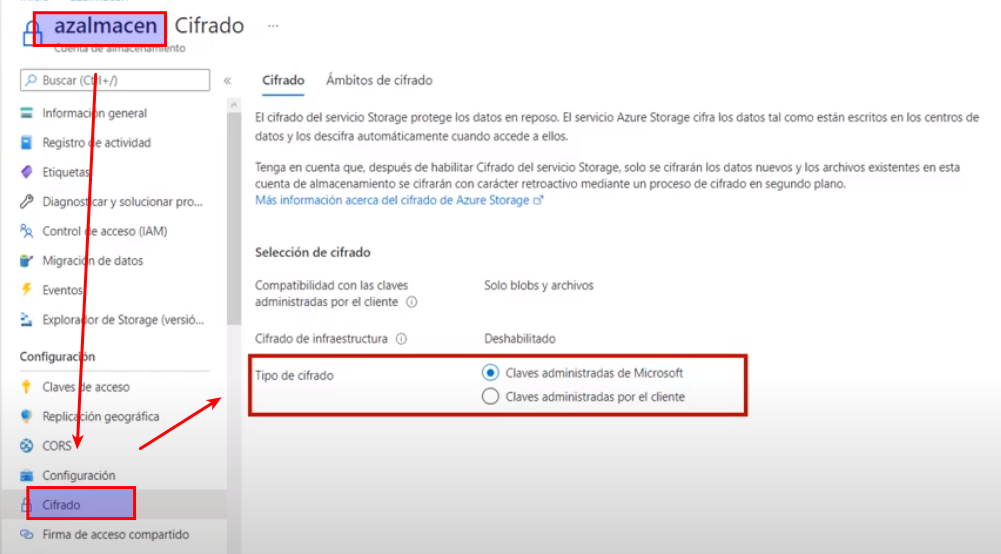
- Pero también se pueden proporcionar claves propias de cifrado
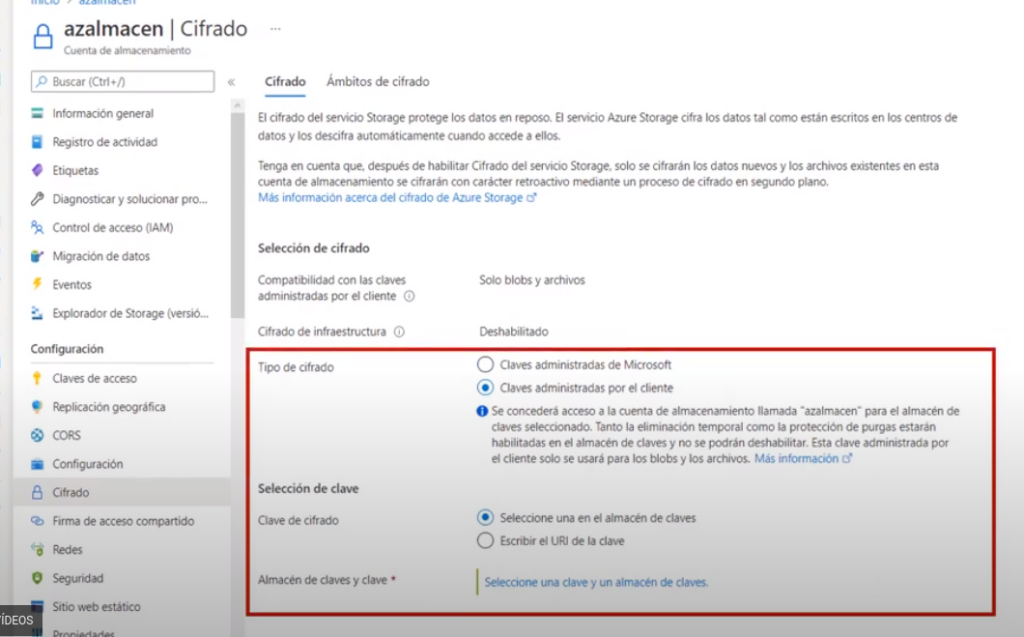
- Para hacer esto es necesario agregar estas claves en el servicio de Azure Key Vault
- Los nuevos datos se cifran con esta nueva clave
- Y los valores anteriores pasan por un proceso de segundo plano que los cifra con el nuevo valor
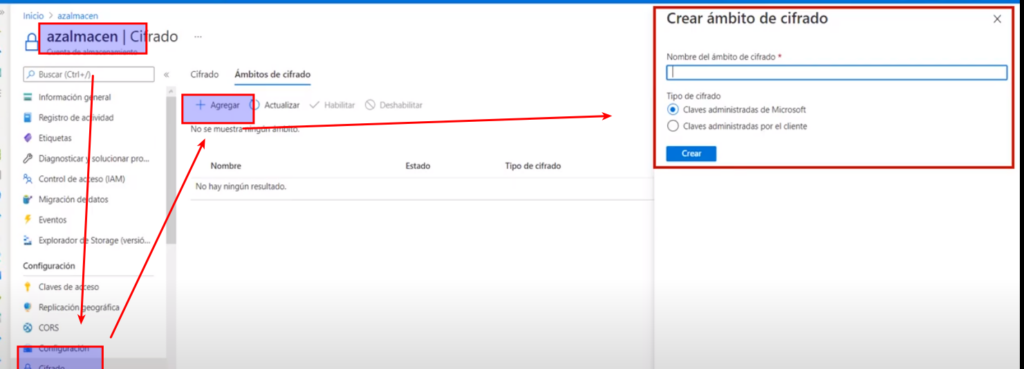
Configuración de las firmas de acceso compartido
- Se pueden utilizar formas de acceso compartido para conceder derechos limitados a los recursos de una cuenta de Azure Storage durante un periodo de tiempo especificado
- Esto permite que las aplicaciones accedan a recursos como blob’s y archivos sin la necesidad de autenticarse primero
- Solo debe utilizar SAS para los datos que se deban hacer públicos
- La aplicación anexa el token a la URL del recurso, después la aplicación puede enviar solicitudes para leer o escribir datos mediante esta dirección URL
- Se puede crear un token que conceda acceso temporal a todo el servicio, a los contenedores del servicio o a objetos individuales como blob’s o archivos
- Se debe especificar:
- Los permisos
- El periodo de tiempo donde el token es válido
- E intervalo de direcciones IP de los equipos que tienen permiso de utilizar el token
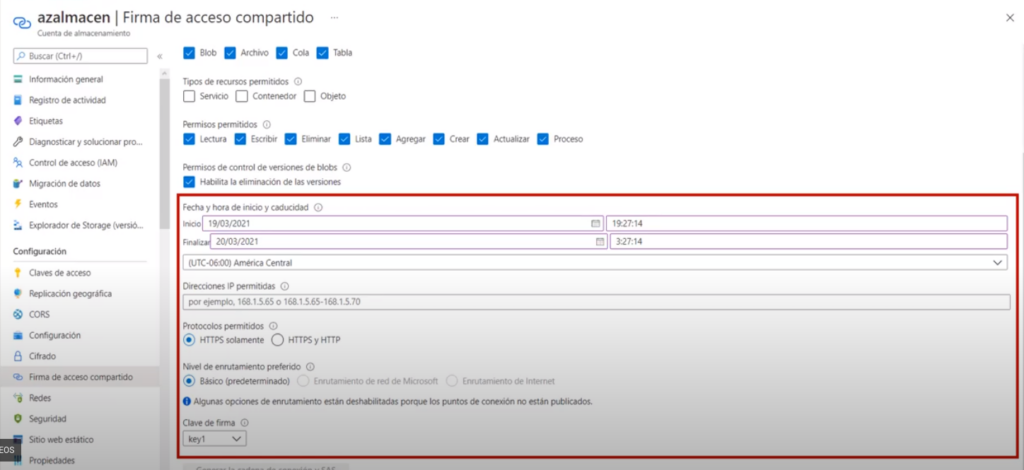
- El token se cifra mediante una de las claves de acceso
Unidad 6: Ejercicio: Exploración de Azure Storage
Aprovisionamiento de una cuenta de Azure Storage
El primer paso para usar Azure Storage es aprovisionar una cuenta de Azure Storage en su suscripción de Azure.
Si todavía no lo ha hecho, inicie sesión en Azure Portal en https://portal.azure.com. En la página principal de Azure Portal, seleccione + Crear un recurso en la esquina superior izquierda y busque Cuenta de almacenamiento. Luego, en la página Cuenta de almacenamiento resultante, seleccione Crear.
- Escriba los valores siguientes en la página Crear una cuenta de almacenamiento:
- Suscripción: si usa un espacio aislado, seleccione la opción Concierge Subscription (Suscripción de Concierge). En caso contrario, seleccione su suscripción de Azure.
- Grupo de recursos: si usa un espacio aislado, seleccione el grupo de recursos existente (que tendrá un nombre como learn-xxxx…). De lo contrario, cree un grupo de recursos con el nombre que prefiera.
- Nombre de la cuenta de almacenamiento: escriba un nombre único para la cuenta de almacenamiento con números y letras minúsculas.
- Región: seleccione cualquier ubicación disponible.
- Rendimiento: Estándar
- Redundancia: almacenamiento con redundancia local (LRS)
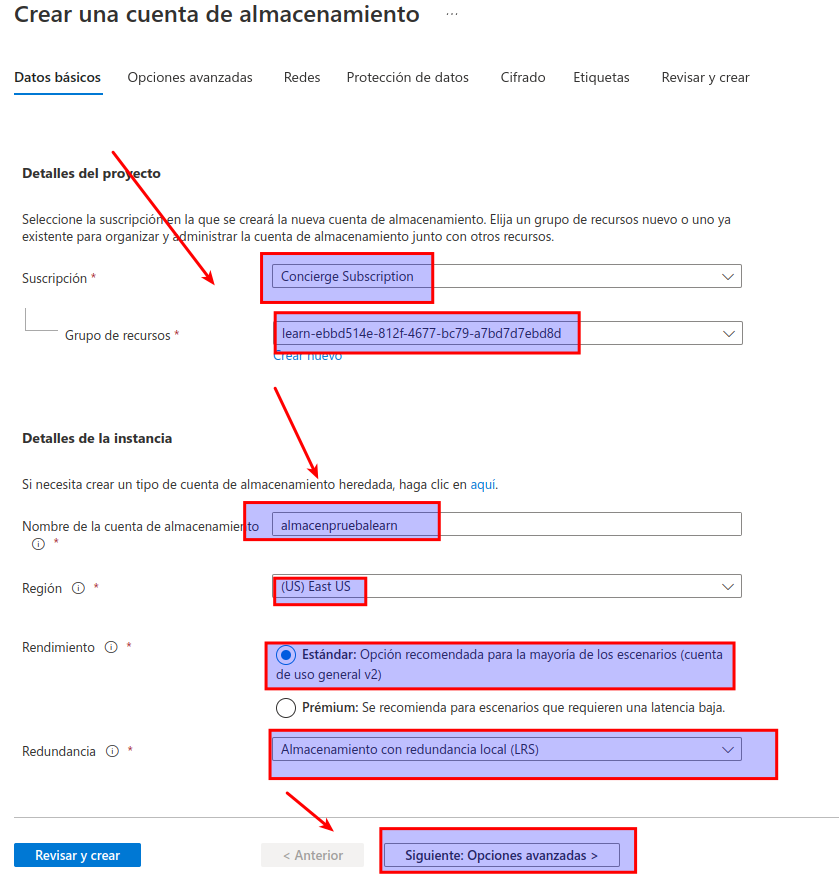
Seleccione Siguiente: Opciones avanzadas > y vea las opciones de configuración avanzada. En concreto, tenga en cuenta que es así donde puede habilitar el espacio de nombres jerárquico para admitir Azure Data Lake Storage Gen2. Deje esta opción sin seleccionar (la habilitará más adelante)

seleccione Siguiente: Redes > para conocer las opciones de redes correspondientes a la cuenta de almacenamiento.
Seleccione Siguiente: Protección de datos > y, luego, en la sección Recuperación, anule la selección de todas las opciones Habilitar eliminación temporal…. Estas opciones conservan los archivos eliminados para su posterior recuperación, pero pueden causar problemas más adelante cuando se habilite el espacio de nombres jerárquico.
Continúe por el resto de las páginas Siguiente > sin cambiar la configuración predeterminada y, luego, en la página Revisar y crear, espere la validación de sus selecciones y seleccione Crear para crear una cuenta de Azure Storage.
Espere a que la implementación finalice. Luego, vaya al recurso que se implementó.
Exploración de almacenamiento de blobs
Ahora que tiene una cuenta de Azure Storage, puede crear un contenedor para los datos de blobs.
Descargue el archivo JSON product1.json desde https://aka.ms/product1.json y guárdelo en el equipo (puede guardarlo en cualquier carpeta, porque lo cargará en el almacenamiento de blobs más adelante).
Si el archivo JSON aparece en el explorador, guarde la página como product1.json.
En la página del contenedor de almacenamiento en Azure Portal, en la sección Almacenamiento de datos que aparece al lado izquierdo, seleccione Contenedores.
En la página Contenedores, seleccione + Contenedor y agregue un contenedor nuevo denominado data con un nivel de acceso público de Privado (sin acceso anónimo).
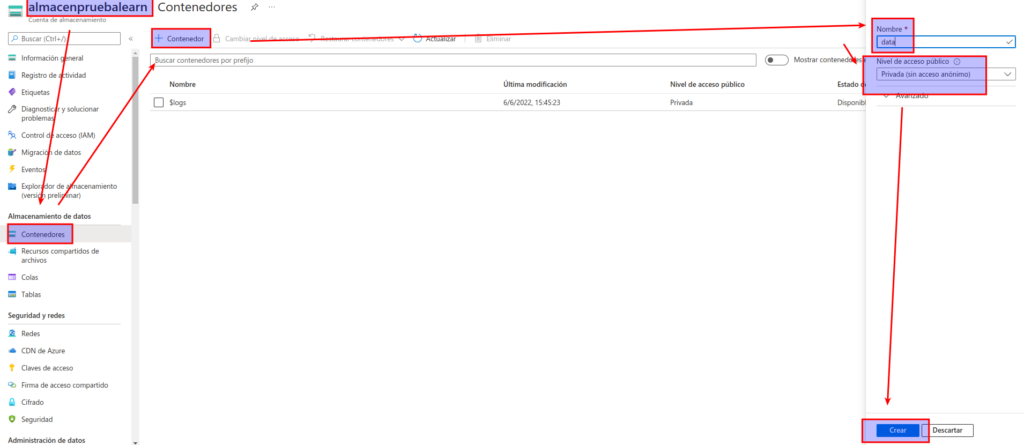
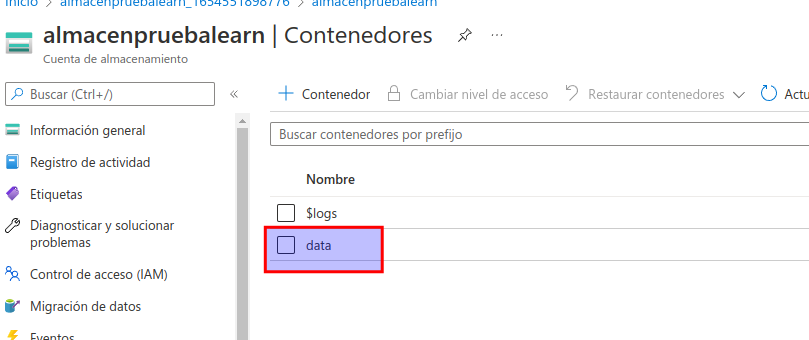
Una vez creado el contenedor data, compruebe que aparece en la página Contenedores.
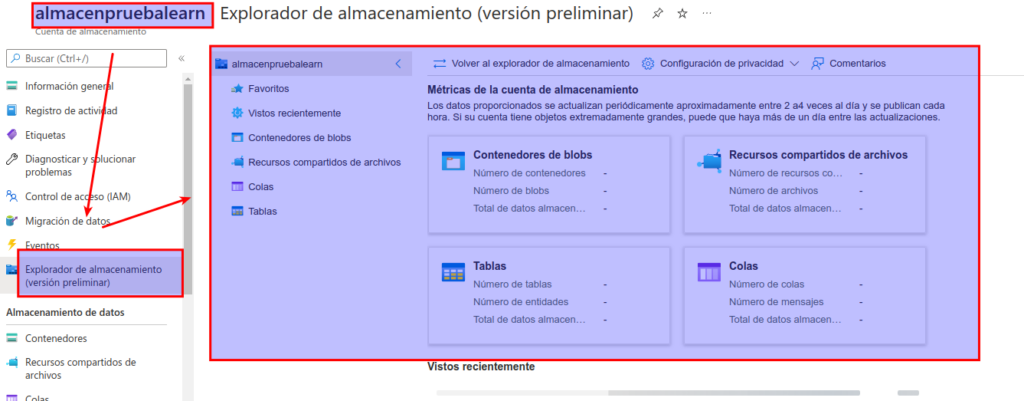
En la sección superior del panel de la izquierda, seleccione Explorador de almacenamiento (versión preliminar). En esta página, se proporciona una interfaz basada en explorador que puede utilizar para trabajar con los datos de la cuenta de almacenamiento.
En la página del explorador de almacenamiento, seleccione Contenedores de blobs y compruebe que aparece el contenedor data.
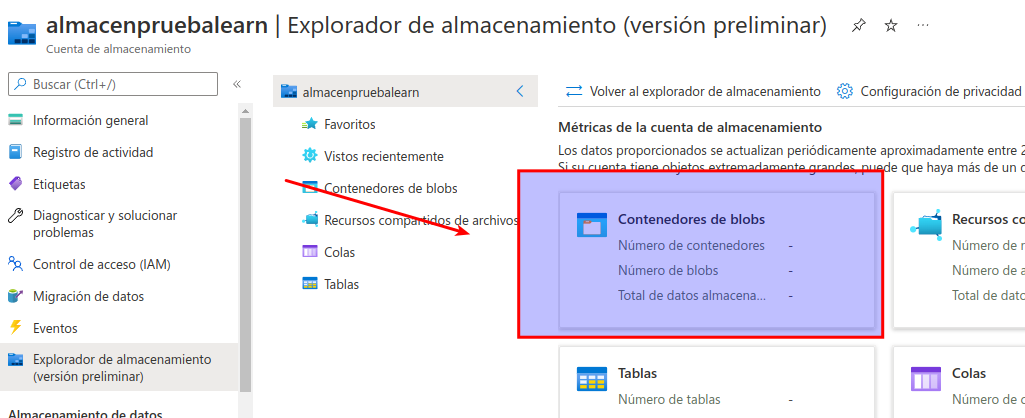
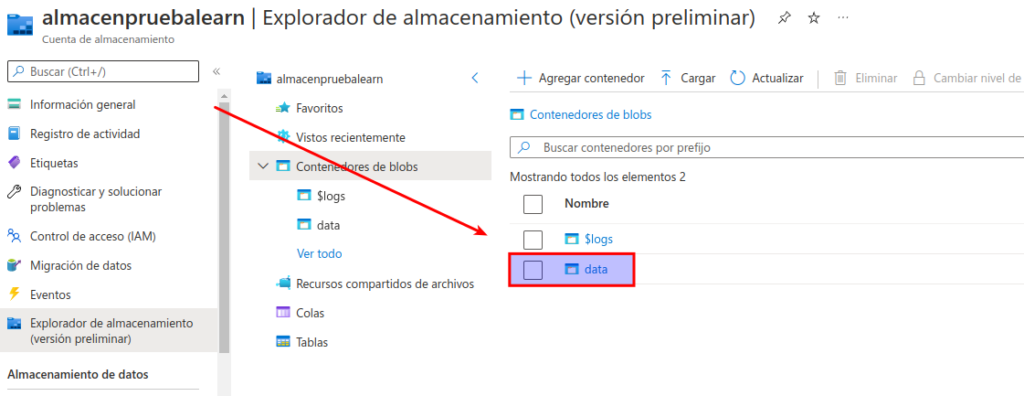
Seleccione el contenedor data y observe que está vacío.
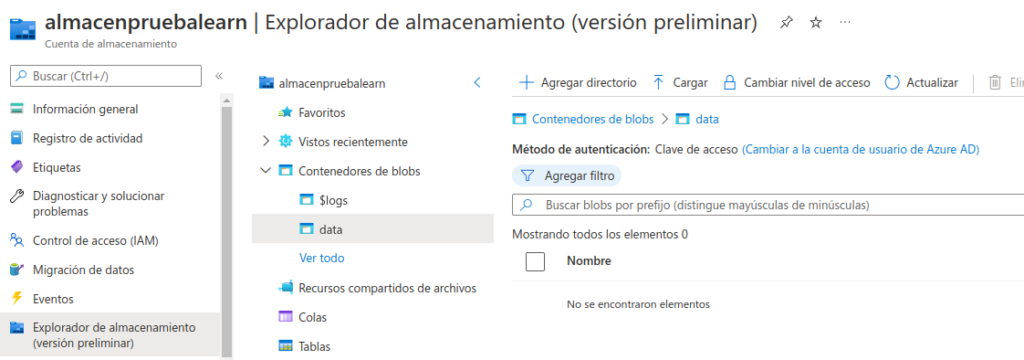
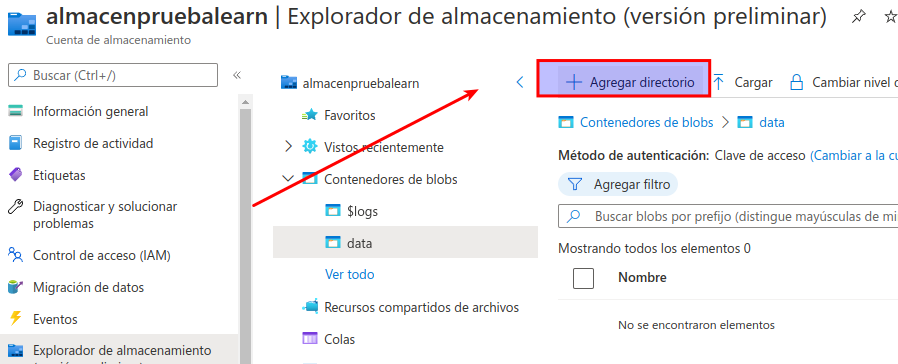
Seleccione + Agregar directorio y lea la información sobre las carpetas antes de crear un directorio denominado products.
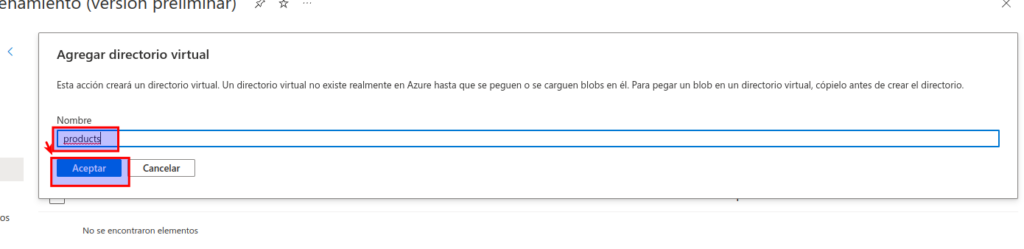
En el explorador de almacenamiento, compruebe que la vista actual muestra el contenido de la carpeta products que acaba de crear. Observe que las rutas de navegación que se encuentran en la parte superior de la página reflejen la ruta de acceso Contenedores de blobs > data > products.
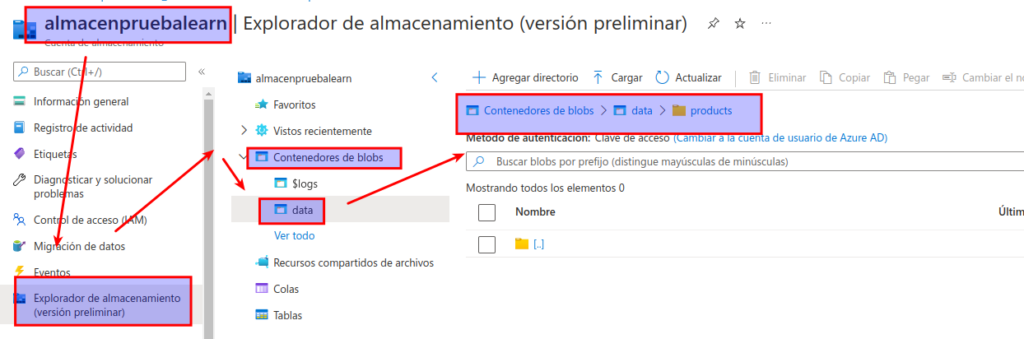
En las rutas de navegación, seleccione data para cambiar al contenedor data y observe que no contiene ninguna carpeta denominada products.
Las carpetas del almacenamiento de blobs son virtuales y solo existen como parte de la ruta de acceso de un blob. Como la carpeta products no contiene ningún blob, en realidad no existe.
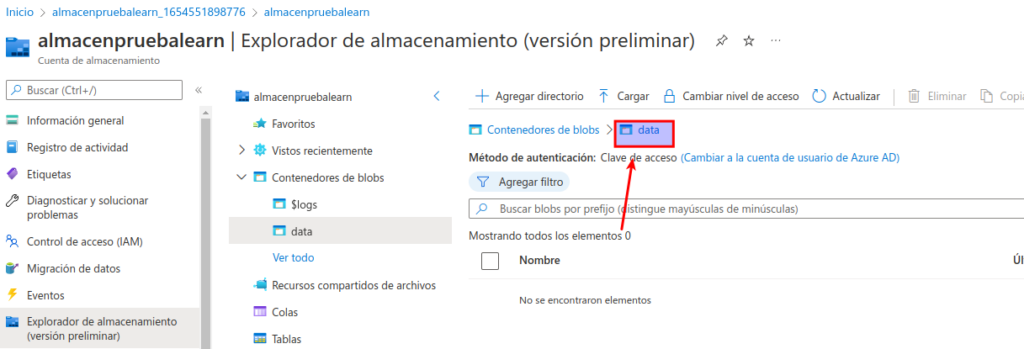
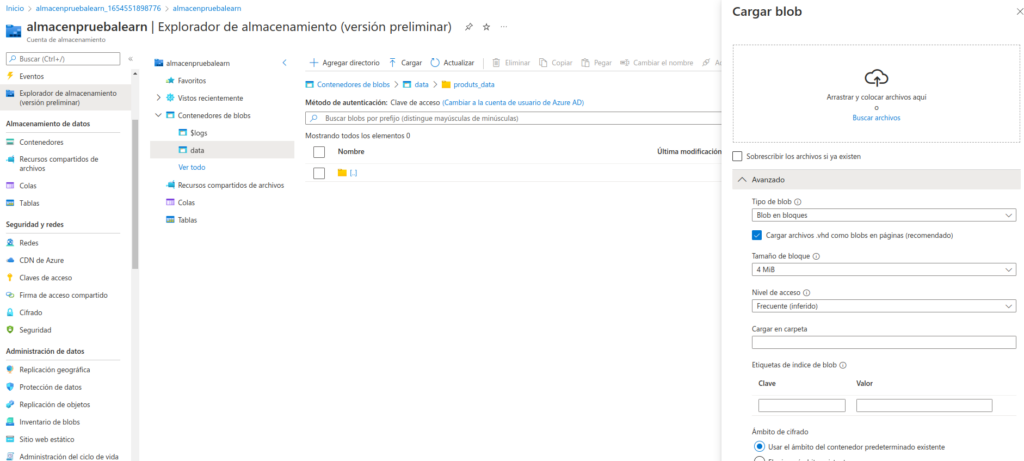
Utilice el botón ⤒ Cargar para abrir el panel Cargar blob.
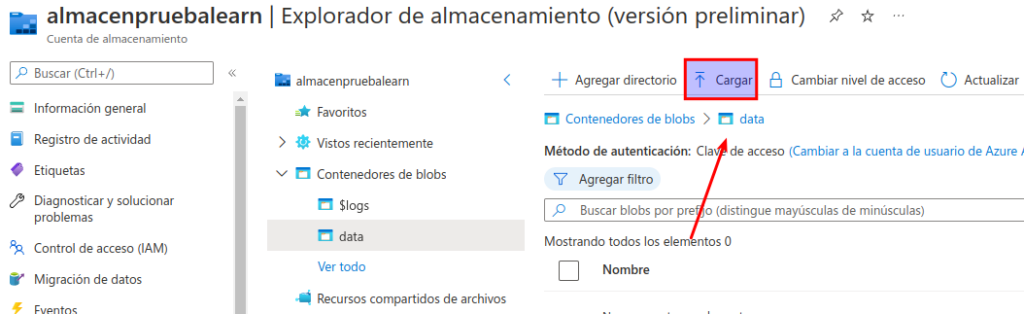
En el panel Cargar blob, seleccione el archivo product1.json que guardó anteriormente en el equipo local. Luego, en la sección Opciones avanzadas, en el cuadro Cargar en carpeta, escriba product_data y seleccione el botón Cargar. (Dio ERROR)
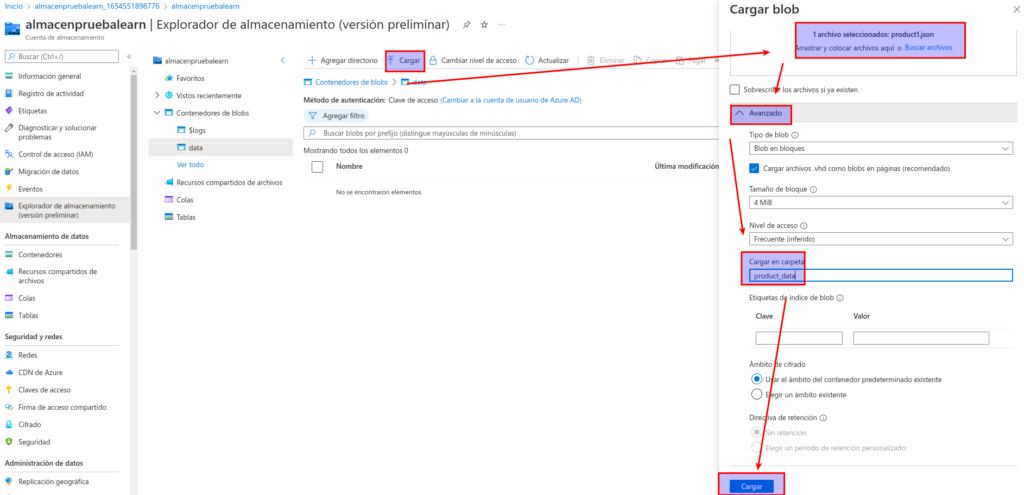
Cierre el panel Cargar blob si todavía está abierto y compruebe que se creó una carpeta virtual denominada product_data en el contenedor data.
Seleccione la carpeta product_data y compruebe que contiene el blob product1.json que cargó.
En el lado izquierdo, en la sección Almacenamiento de datos, seleccione Contenedores.
Abra el contenedor data y compruebe que aparece la carpeta product_data que creó.
Seleccione el icono ‧‧‧ que aparece en el extremo derecho de la carpeta y observe que no muestra ninguna opción. Las carpetas de un contenedor de blobs de espacio de nombres plano son virtuales y no se pueden administrar.
Use el icono X que está en la parte superior derecha de la página data para cerrarla y vuelva a la página Contenedores.
Exploración de Azure Data Lake Storage Gen2
La compatibilidad con Azure Data Lake Store Gen2 le permite usar carpetas jerárquicas para organizar y administrar el acceso a los blobs. También le permite utilizar Azure Blob Storage para hospedar sistemas de archivos distribuidos para plataformas comunes de análisis de macrodatos.
Descargue el archivo JSON product2.json desde https://aka.ms/product2.json y guárdelo en el equipo en la misma carpeta en la que descargó anteriormente product1.json (lo cargará en el almacenamiento de blobs más adelante).
En la página del contenedor de almacenamiento en Azure Portal, en el lado izquierdo, desplácese a la sección Configuración y seleccione Actualización de Data Lake Gen2.
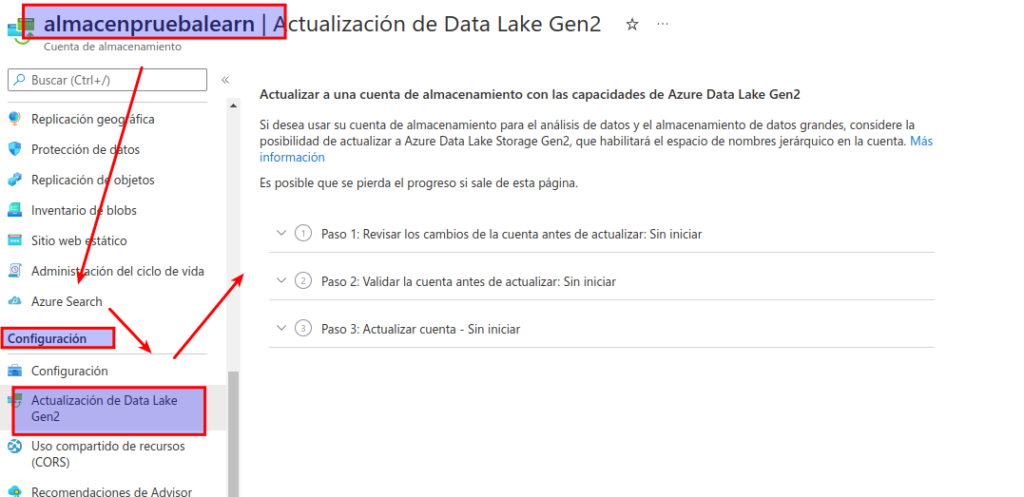
En la página Actualización de Data Lake Gen2, expanda y complete cada paso para actualizar la cuenta de almacenamiento a fin de habilitar el espacio de nombres jerárquico y admitir Azure Data Lake Storage Gen2. Esto puede llevar algo de tiempo.
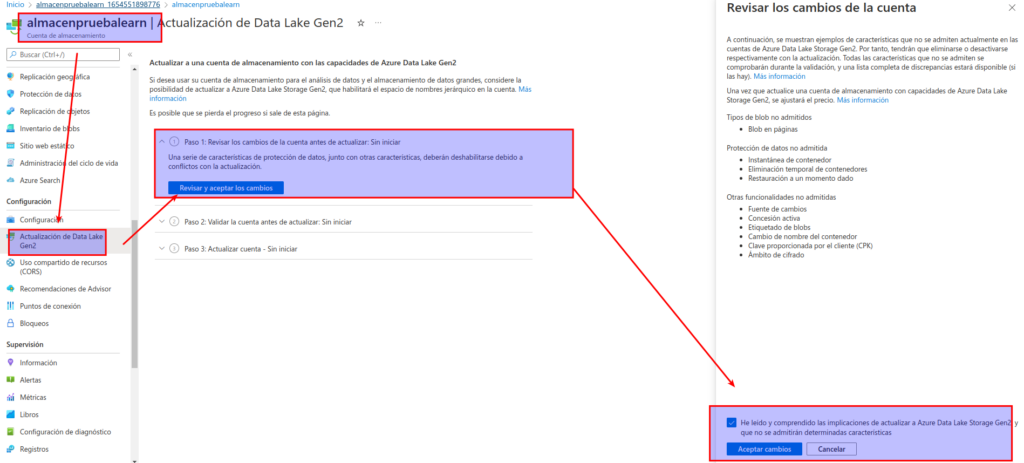
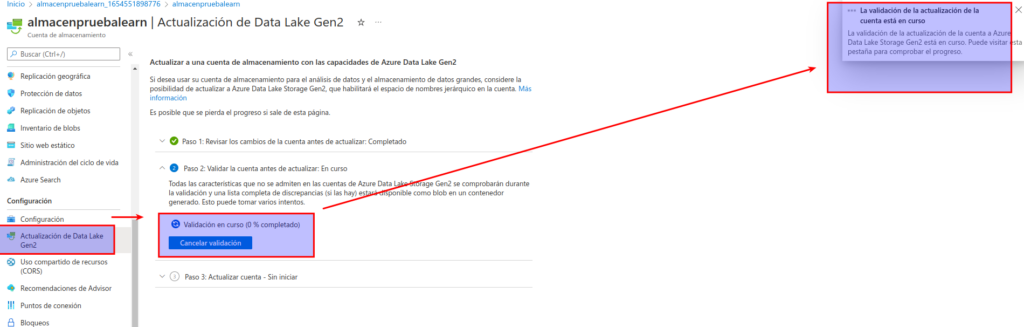
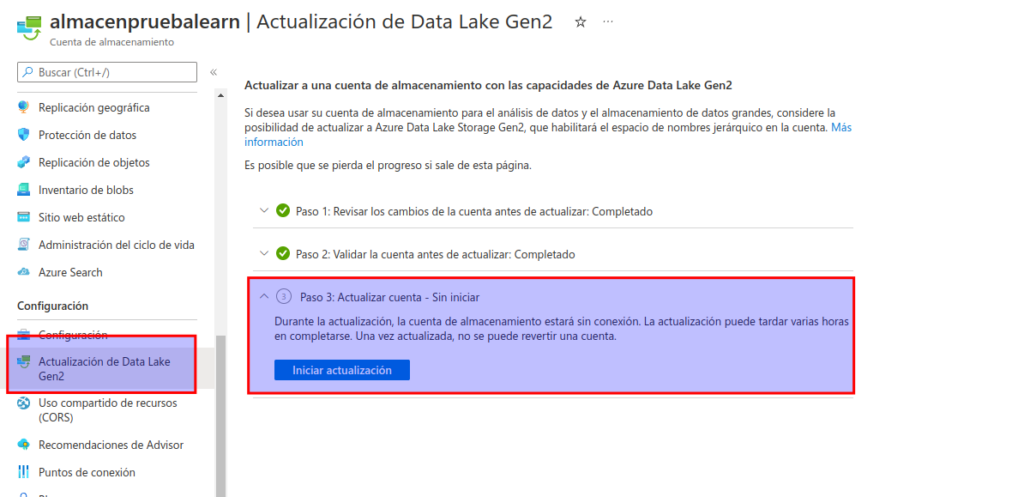
Una vez que se complete la actualización, en la sección superior del panel de la izquierda, seleccione Explorador de almacenamiento (versión preliminar) y navegue de vuelta a la raíz del contenedor de blobs data, que todavía contiene la carpeta product_data.
Seleccione la carpeta product_data y compruebe que todavía contiene el archivo product1.json que cargó anteriormente.
Utilice el botón ⤒ Cargar para abrir el panel Cargar blob.
En el panel Cargar blob, seleccione el archivo product2.json que guardó en el equipo local. Luego, seleccione el botón Cargar.(ERROR)
Cierre el panel Cargar blob si todavía está abierto y compruebe que la carpeta product_data ahora contiene el archivo product2.json.
En el lado izquierdo, en la sección Almacenamiento de datos, seleccione Contenedores.
Abra el contenedor data y compruebe que aparece la carpeta product_data que creó.
Seleccione el icono ‧‧‧ que aparece en el extremo derecho de la carpeta y observe que, si el espacio de nombres jerárquico está habilitado, puede hacer tareas de configuración en el nivel de carpeta, incluido el cambio de nombre de carpetas y la configuración de permisos.
Use el icono X que está en la parte superior derecha de la página data para cerrarla y vuelva a la página Contenedores.
Explorar Azure Files
Azure Files proporciona una manera de crear recursos compartidos de archivos basados en la nube.
En la página del contenedor de almacenamiento en Azure Portal, en la sección Almacenamiento de datos que aparece al lado izquierdo, seleccione Recursos compartidos de archivos.
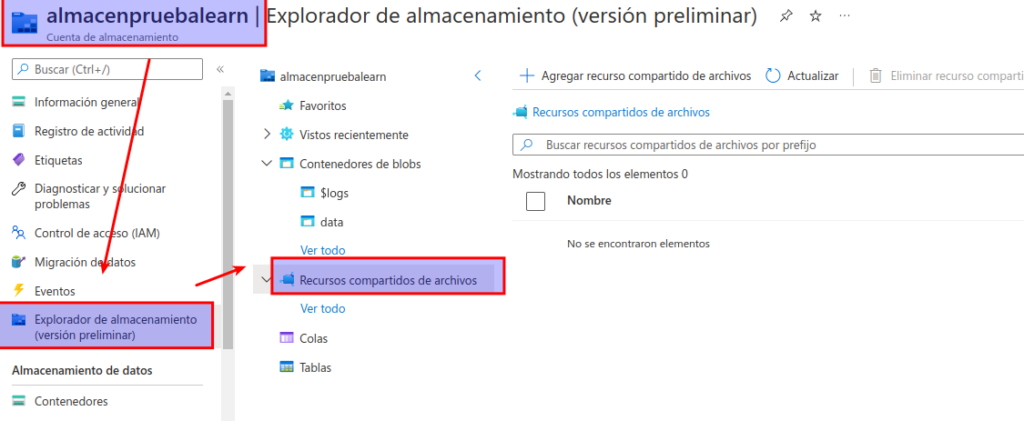
En la página Recursos compartidos de archivos, seleccione + Recurso compartido de archivos y agregue un recurso compartido de archivos nuevo denominado files mediante el nivel Optimizado para transacciones.
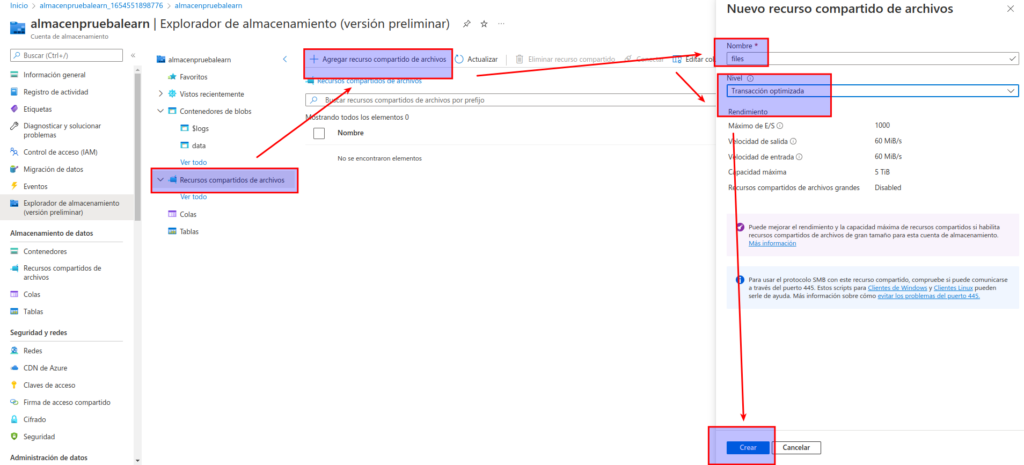
En los Recursos compartidos de archivos, abra el recurso compartido de archivos files nuevo.
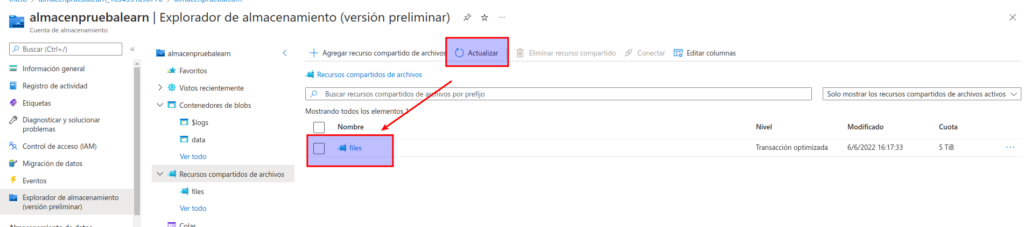
En la parte superior de la página, seleccione Conectar. Luego, en el panel Conectar, observe que hay pestañas para los sistemas operativos comunes (Windows, Linux y macOS) que contienen scripts que puede ejecutar para conectarse a la carpeta compartida desde un equipo cliente. (NO EXISTE)
Cierre el panel Conectar y, luego, cierre la página files para volver a la página Recursos compartidos de archivos de la cuenta de Azure Storage.
Exploración de tablas de Azure
Las tablas de Azure proporcionan un almacén de clave-valor para las aplicaciones que necesitan almacenar valores de datos, pero que no necesitan la funcionalidad y la estructura completas de una base de datos relacional.
En la página del contenedor de almacenamiento en Azure Portal, en la sección Almacenamiento de datos que aparece al lado izquierdo, seleccione Tablas.
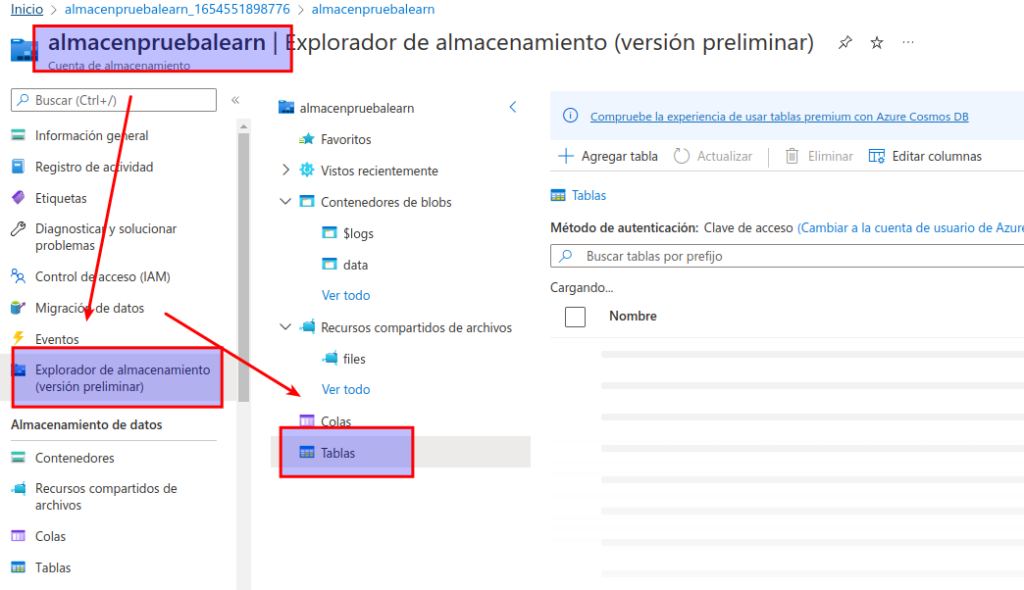
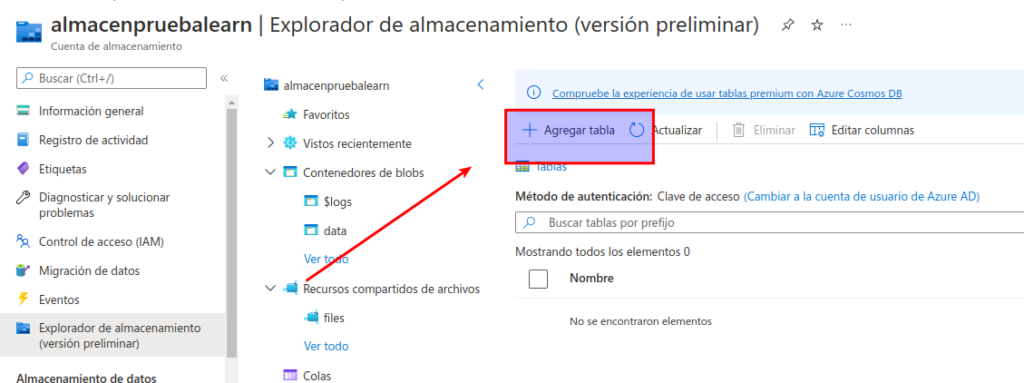
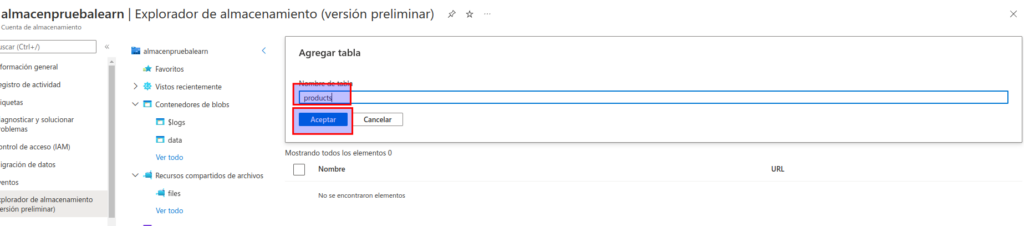
En la página Tablas, seleccione + Tabla y cree una tabla denominada products.
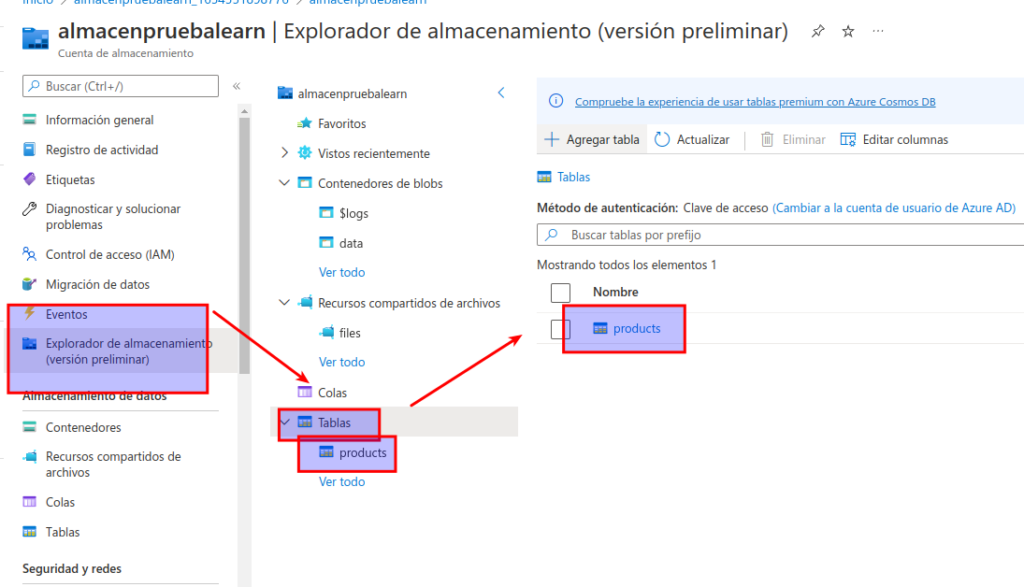
Una vez que se crea la tabla products, en la sección superior del panel de la izquierda, seleccione Explorador de almacenamiento (versión preliminar).
En el explorador de almacenamiento, seleccione Tablas y compruebe que aparece la tabla products.
Seleccione la tabla products.
En la página product, seleccione + Agregar entidad.
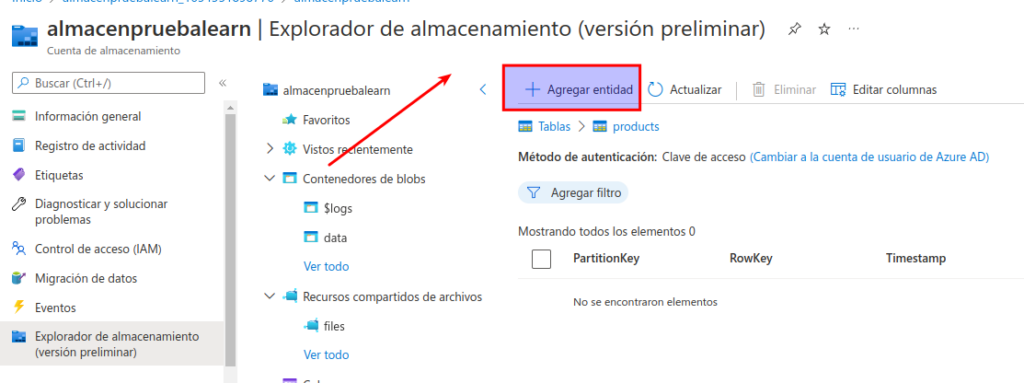
- En el panel Agregar entidad, escriba estos valores de clave:
- PartitionKey: 1
- RowKey: 1
Seleccione Agregar propiedad y cree una propiedad con estos valores:

Agregue una segunda propiedad con estos valores:

Seleccione Insertar para insertar en la tabla una fila para la entidad nueva en la tabla.
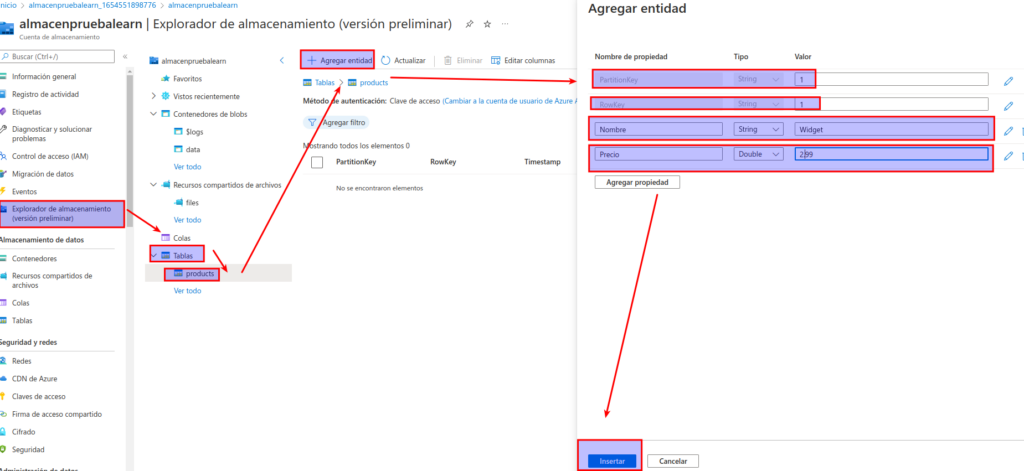
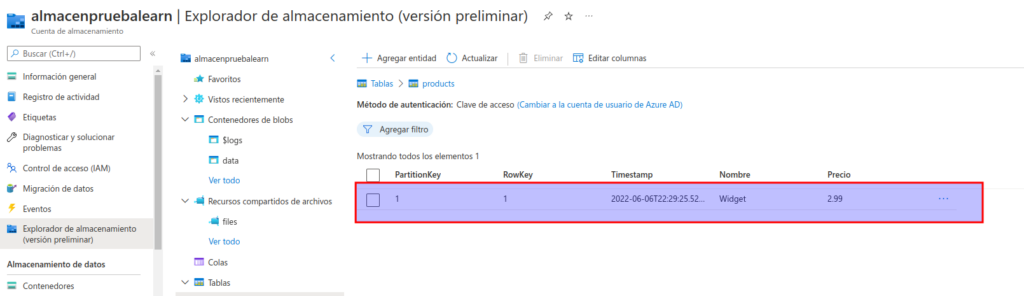
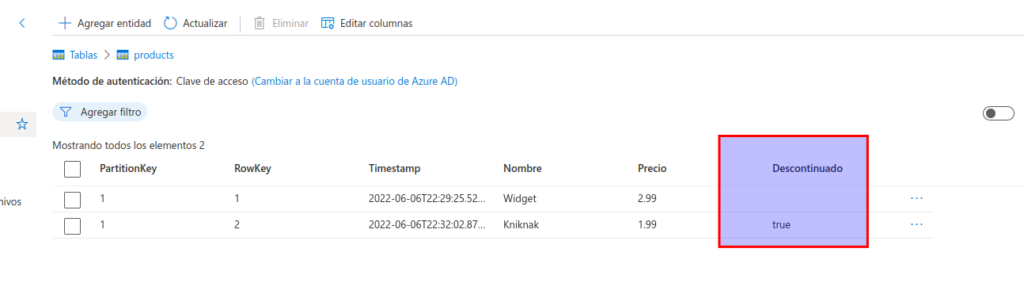
En el explorador de almacenamiento, compruebe que se agregó una fila a la tabla products y que se creó una columna Timestamp para indicar la fecha de última modificación de la fila.
Agregue otra entidad a la tabla products con estas propiedades:
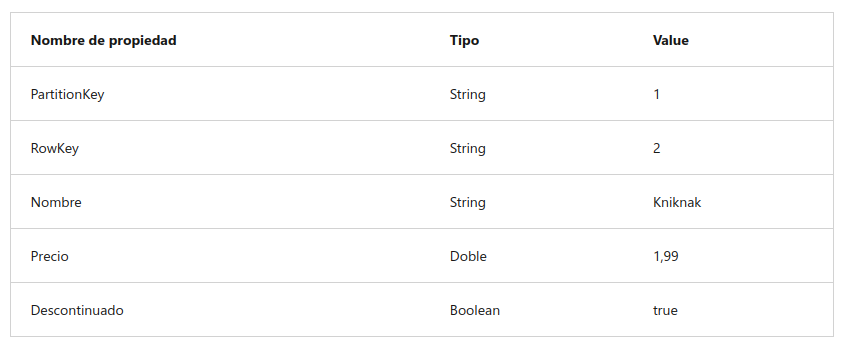
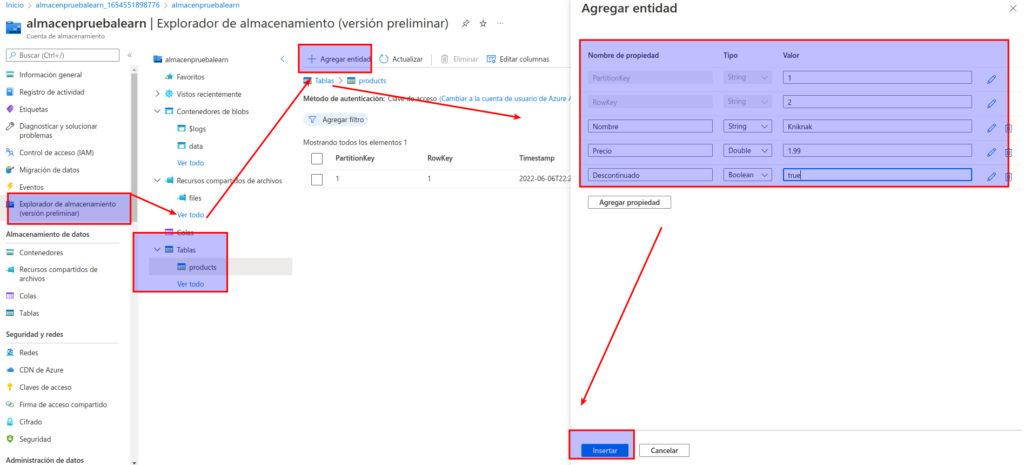
Después de insertar la entidad nueva, compruebe que en la tabla se muestra una fila que contiene el producto descontinuado.
Escribió los datos en la tabla con la interfaz del explorador de almacenamiento. En un escenario real, los desarrolladores de aplicaciones pueden la Azure Storage Table API para compilar aplicaciones que leen y escriben valores en tablas, lo que la hace una solución rentable y escalable para el almacenamiento NoSQL.