https://docs.microsoft.com/es-mx/learn/modules/examine-components-of-modern-data-warehouse/
Unidad 1: Introducción
El almacenamiento de datos moderno es un término genérico que describe la infraestructura y los procesos que se usan para admitir el análisis de datos a gran escala. Las soluciones modernas de almacenamiento de datos combinan el almacenamiento de datos convencional que se usa para admitir inteligencia empresarial (BI), que normalmente implica copiar datos de almacenes de datos transaccionales en una base de datos relacional con un esquema optimizado para consultar y crear modelos multidimensionales; esto se realiza con técnicas usadas para los denominados análisis de «macrodatos», donde grandes volúmenes de datos en varios formatos se cargan o capturan por lotes en flujos en tiempo real y se almacenan en un lago de datos desde el que se usan motores de procesamiento distribuido como Apache Spark para procesar los datos a escala.
Unidad 2: Descripción del almacenamiento de datos moderno
La arquitectura moderna de almacenamiento de datos puede variar, al igual que las tecnologías específicas que se usan para implementarla; de todos modos, en general, se incluyen los siguientes elementos:
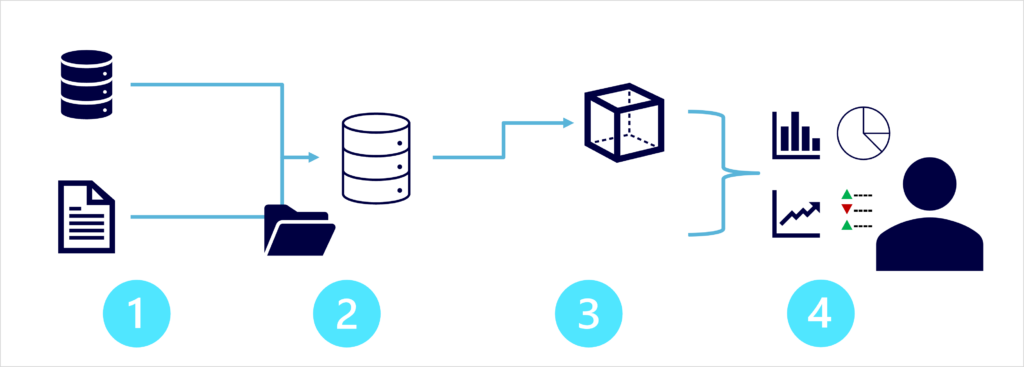
- Ingesta y procesamiento de datos: los datos de uno o varios almacenes de datos transaccionales, archivos, flujos en tiempo real u otros orígenes se cargan en un lago de datos o en un almacenamiento de datos relacional. Normalmente, la operación de carga implica un proceso de extracción, transformación y carga (ETL) o de extracción, carga y transformación (ELT) en el que los datos se limpian, filtran y reestructuran para su análisis. En los procesos de ETL, los datos se transforman antes de cargarse en un almacén analítico, mientras que en un proceso de ELT los datos se copian en el almacén y, posteriormente, se transforman. En cualquier caso, la estructura de datos resultante está optimizada para las consultas analíticas. El procesamiento de datos suele realizarse mediante sistemas distribuidos que pueden procesar grandes volúmenes de datos en paralelo mediante clústeres de varios nodos. La ingesta de datos incluye el procesamiento por lotes de datos estáticos y el procesamiento en tiempo real de los datos de streaming.
- Almacén de datos analíticos: los almacenes de datos para análisis a gran escala incluyen almacenamientos de datos relacionales, lagos de datos basados en sistema de archivos y arquitecturas híbridas que combinan características de almacenes de datos y lagos de datos (a veces bajo la denominación de lagos de almacenamiento de datos o bases de datos de lago). Los trataremos con más detalle más adelante.
- Modelo de datos analíticos: aunque los analistas de datos y los científicos de datos pueden trabajar con los datos directamente en el almacén de datos analíticos, es habitual crear uno o varios modelos de datos que agreguen previamente los datos para facilitar la generación de informes, paneles y visualizaciones interactivas. A menudo, estos modelos de datos se describen como cubos, en los que los valores de datos numéricos se agregan en una o varias dimensiones (por ejemplo, para determinar las ventas totales por producto y región). El modelo encapsula las relaciones entre los valores de datos y las entidades dimensionales para admitir el análisis de tipo «rastrear agrupando datos/explorar en profundidad».
- Visualización de datos: los analistas de datos consumen datos de modelos analíticos y directamente de almacenes analíticos para crear informes, paneles y otras visualizaciones. Además, los usuarios de una organización, que pueden no ser profesionales de la tecnología, pueden realizar informes y análisis de datos de autoservicio. Las visualizaciones de los datos muestran tendencias, comparaciones e indicadores clave de rendimiento (KPI) para una empresa u otra organización, y pueden tomar la forma de informes impresos, diagramas y gráficos en documentos o presentaciones de PowerPoint, paneles basados en web y entornos interactivos en los que los usuarios pueden explorar los datos visualmente.
MCT: Video 4.1.1 Descripción de la arquitectura moderna y los flujos de data warehousing
Descripción del almacenamiento de datos moderno
- Un almacenamiento de datos recopila datos de muchos orígenes que se utilizan para el análisis de informes y el procesamiento analítico en línea
- Los almacenamiento de datos tienen que administrar macrodatos
- macrodatos:
- son grandes cantidades de datos recopilados
- En volúmenes escalables
- A velocidades muy altas
- Y una variedad de formatos
- Pueden ser datos históricos: es decir datos almacenados
- O puede ser en tiempo real: es decir que se transmiten desde un orígen
Características de la arquitectura moderna
Modular
- Se añaden componentes
- No hay limite de componentes que se pueden añadir
- Permite crecer junto al negocio, es decir se pueden quitar o agregar nuevos componentes según la necesidad

Elástica
- Como ejemplo una bola de ligas se pueden manipular lo componentes escalandolos o quitandolos como sea necesario
- Incluso pausar servicios que no se estén utilizando

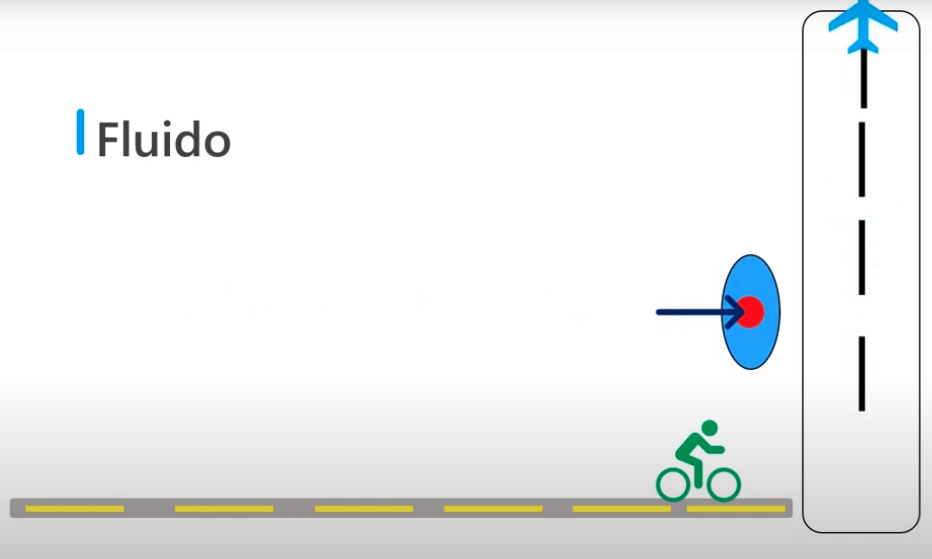
Fluida
- Quiere decir que cualquier tipo de datos se puede añadir
- Los datos se añaden de forma fluida
- Y sin representar ningún tipo de problema ya que es en tiempo real o almacenamiento
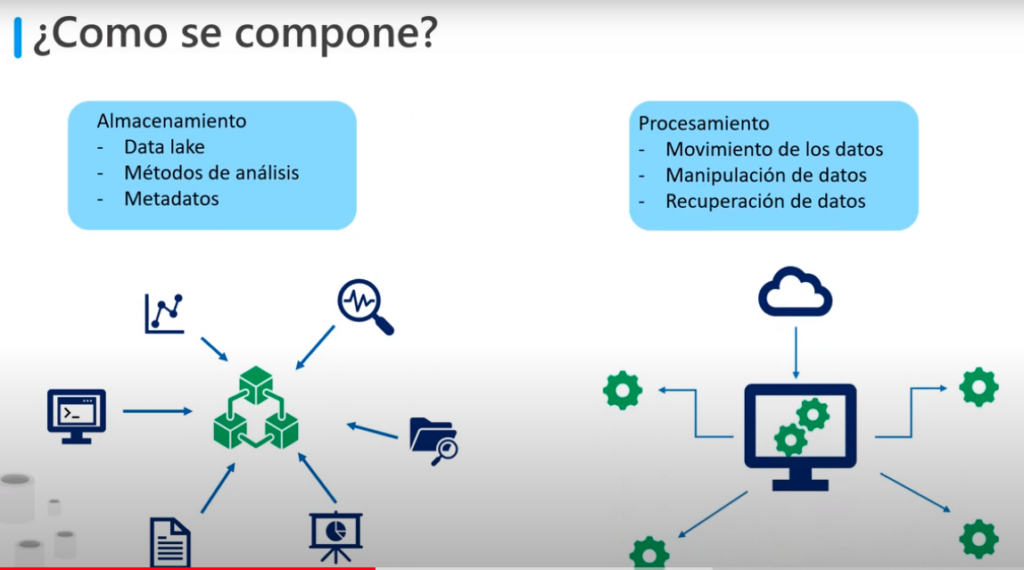
Cómo se compone esta arquitectura moderna?
Se compone de 2 características
- Almacenamiento:
- Cuanta con el data Lake
- Métodos de análisis
- Metadatos
- Procesamiento
- Movimiento de datos
- Manipulación de datos
- Recuperación de datos
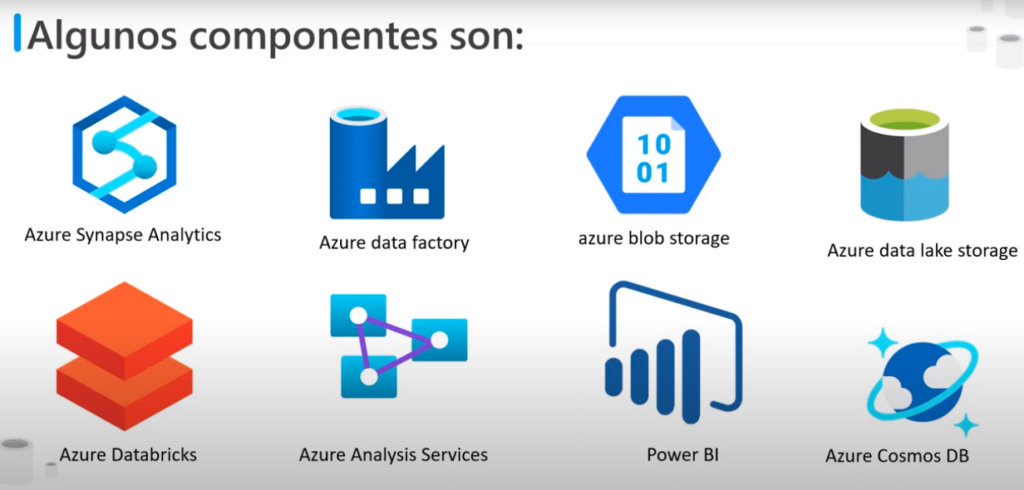
Componentes en Azure
Azure Synapse Analytics:
- Es la base de datos en la nube
- Rápida, flexible y de confianza
- Permite escalar, procesar y almacenar de forma elástica e independiente
- Con una arquitectura de procesamiento paralelo y masivo
Azure Data Factory:
- Es un servicio de integración de datos híbrido
- Permite crear, programar y orquestar flujos de trabajo
Azure Blob Storage:
- Es un almacenamiento de objetos escalable, de forma masiva para cualquier tipo de datos e imágenes
- Principalmente se usa para datos no estructurados, como imágenes, vídeos, audios y documentos
- Estos datos se almacenan de manera más sencilla y rentable
Azure Data Lake Storage:
- Incluye toda la funcionalidad necesaria para facilitar a los desarrolladores, científicos de datos y analistas el almacenamiento de datos de cualquier tamaño y forma
- Cuenta con la velocidad para llevar a cabo cualquier tipo de procesamiento y análisis en diferentes plataformas y lenguajes
Azure Databricks:
- Es una plataforma de análisis rápida, sencilla y colaborativa
- Basada en Apache Spark
Azure Analysis Services:
- Es una análisis de nivel empresarial como servicios
- Permite: gobernar, implementar, probar y proporcionar una solución de Business Intelligence (BI) con confianza
Power BI
- Es un conjunto de herramientas de análisis empresarial, que proporciona información detallada hacer de toda la organización
- Conectar cientos de orígenes de datos
- Simplifica la preparación de los datos
- realiza análisis
- Permite crear informes atractivos y se pueden publicar en la organización para que se usen en la Web y dispositivos móviles
Azure Cosmos DB
- Servicio de BD, múltimodelo
- Distribuido globalmente
- Que permite la réplica de los datos
- Y permite escalamiento independientes de los almacenamientos
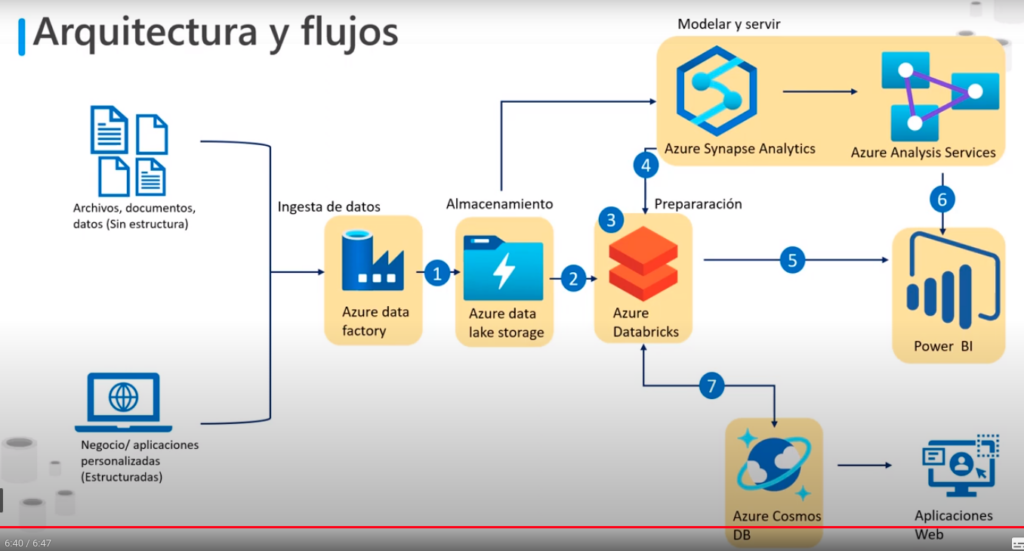
Arquitectura y Flujos
- Datos: principalmente se dividen en dos:
- Los datos de los servicios relacionales (con estructura)
- Y los datos No relacionales (sin estructura)
- Ingesta de datos:
- Los datos primero se recuperan mediante Azure Data Factory
- Sirve también para darle formato a los datos, a este proceso se le denomina ingesta de datos
- Almacenamiento:
- Los datos con formato de almacenan en Azure Data Lake Storage:
- Permite almacenar grandes volúmenes de datos de forma muy rápida y sencilla antes de analizarlos
- A partir de aquí los datos pueden seguir dos caminos
- Modelar y servir
- Los datos se convierten a un formato normalizado, adecuado para su análisis
- Y se almacenan mediante Azure Synapse Analytic
- Preparación:
- Los datos también se pueden almacenar con Azure Databrick, para aplicar otra forma de preparación de datos
- Por ejemplo es posible que se requiera transformaciones de datos adicionales o limpiar
- Se pueden almacenar los datos limpios con Azure Synapse Analytic si es necesario, este funciona como un centro contenedor de datos empresariales ya limpios
- Este puede puede revisar de manera exhaustiva los datos analíticos mediante Azure Analysis Services
- Power BI:
- Puede tomar esta información y utilizarla
- También puede ejecutar consultas, sobre los datos procesados por Azure Databrick
- Azure Cosmos DB:
- Es un opción que no siempre es utilizada para facilitar el almacenamiento de aplicaciones Web
- Modelar y servir
- NOTA: Este es un flujo propuesto sin embargo este puede cambiar según nuestras necesidades
Unidad 3: Exploración de canalizaciones de ingesta de datos
Ahora que comprende un poco la arquitectura de una solución de almacenamiento de datos moderna y algunas de las tecnologías de procesamiento distribuido que se pueden usar para controlar grandes volúmenes de datos, es el momento de explorar cómo se ingieren los datos en un almacén de datos analíticos de uno o varios orígenes.
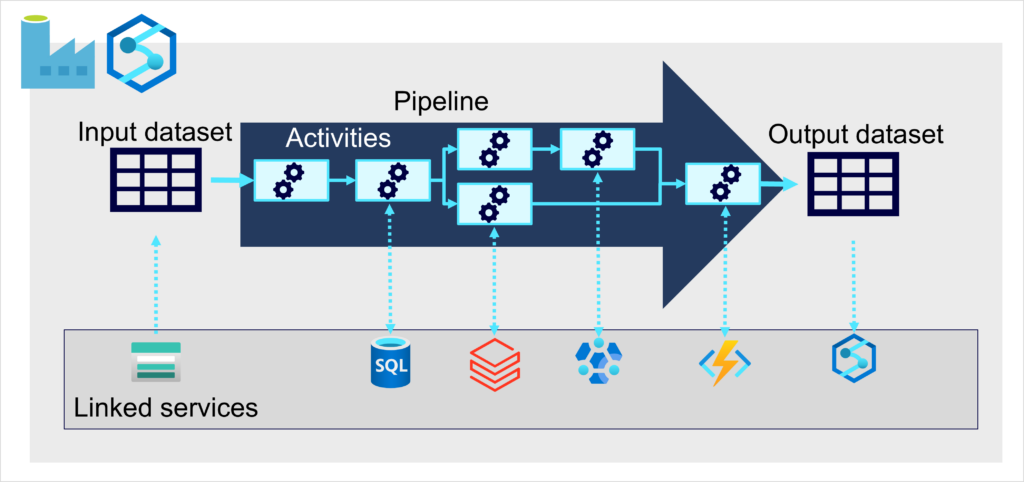
En Azure, la ingesta de datos a gran escala se implementa mejor mediante la creación de canalizaciones que organicen procesos de ETL. Puede crear y ejecutar canalizaciones mediante Azure Data Factory, o puede usar el mismo motor de canalización en Azure Synapse Analytics si quiere administrar todos los componentes de la solución de almacenamiento de datos en un área de trabajo unificada.
En cualquier caso, las canalizaciones constan de una o varias actividades que operan en los datos. Un conjunto de datos de entrada proporciona los datos de origen y las actividades se pueden definir como un flujo de datos que manipula incrementalmente los datos hasta que se genera un conjunto de datos de salida. Las canalizaciones utilizan servicios vinculados para cargar y procesar datos, y esto le permite usar la tecnología adecuada para cada paso del flujo de trabajo. Por ejemplo, puede usar un servicio vinculado de Azure Blob Store para ingerir el conjunto de datos de entrada y, posteriormente, usar servicios como Azure SQL Database para ejecutar un procedimiento almacenado que busque valores de datos relacionados, antes de ejecutar una tarea de procesamiento de datos en Azure Databricks o Azure HDInsight, o aplicar lógica personalizada mediante una función de Azure. Por último, puede guardar el conjunto de datos de salida en un servicio vinculado, como Azure Synapse Analytics. Las canalizaciones también pueden incluir algunas actividades integradas, que no requieren un servicio vinculado.
Unidad 4: Exploración de almacenes de datos analíticos
Hay dos tipos comunes de almacén de datos analíticos.
Almacenamientos de datos
Un almacenamiento de datos es una base de datos relacional en la que los datos se almacenan en un esquema optimizado para el análisis de datos en lugar de en cargas de trabajo transaccionales. Normalmente, los datos de un almacén transaccional se organizan en un esquema en el que los valores numéricos se almacenan en tablas de hechos centrales, que están relacionadas con una o varias tablas de dimensiones que representan entidades por las que se pueden agregar los datos. Por ejemplo, una tabla de hechos podría contener datos de pedidos de ventas, que se pueden agregar por las dimensiones de cliente, producto, tienda y tiempo (lo que le permite, por ejemplo, encontrar fácilmente los ingresos totales mensuales de ventas por producto para cada tienda). Este tipo de esquema de tabla de hechos y dimensiones se denomina esquema de estrella; aunque a menudo se extiende a un esquema de copo de nieve mediante la adición de tablas adicionales relacionadas con las tablas de dimensiones para representar jerarquías dimensionales (por ejemplo, el producto puede estar relacionado con categorías de productos). Un almacenamiento de datos es una excelente opción si tiene datos transaccionales que se pueden organizar en un esquema estructurado de tablas y quiere usar SQL para consultarlos.
Lagos de datos

Un lago de datos es un almacén de archivos, normalmente en un sistema de archivos distribuido para el acceso a datos de alto rendimiento. A menudo se usan tecnologías como Spark o Hadoop para procesar consultas en los archivos almacenados y devolver datos para informes y análisis. Estos sistemas suelen aplicar un enfoque de esquema en lectura para definir esquemas tabulares en archivos de datos semiestructurados en el punto donde se leen los datos para su análisis, sin aplicar restricciones cuando se almacenan. Los lagos de datos son excelentes para admitir una combinación de datos estructurados, semiestructurados e incluso no estructurados que quiere analizar sin necesidad de aplicar el esquema cuando los datos se escriben en el almacén.
Enfoques híbridos
Puede usar un enfoque híbrido que combine características de lagos de datos y almacenamientos de datos en una base de datos de lago o un lago de almacenamiento de datos. Los datos sin procesar se almacenan como archivos en un lago de datos y una capa de almacenamiento relacional abstrae los archivos subyacentes y los expone como tablas, que se pueden consultar mediante SQL. Los grupos de SQL de Azure Synapse Analytics incluyen PolyBase, que permite definir tablas externas basadas en archivos de un lago de datos (y otros orígenes) y consultarlas mediante SQL. Synapse Analytics también admite un enfoque de base de datos de lago en el que puede usar plantillas de base de datos para definir el esquema relacional del almacenamiento de datos, al tiempo que almacena los datos subyacentes en un almacenamiento de lago de datos, separando el almacenamiento y el proceso de la solución de almacenamiento de datos. Los lagos de almacenamiento de datos son un enfoque relativamente nuevo en los sistemas basados en Spark y se habilitan mediante tecnologías como Delta Lake, que agrega funcionalidades de almacenamiento relacional a Spark, por lo que se pueden definir tablas que exijan esquemas y coherencia transaccional, admitan orígenes de datos de streaming y cargados por lotes y proporcionen una API de SQL para realizar consultas.
Servicios de Azure para almacenes analíticos
En Azure, hay tres servicios principales que puede usar para implementar un almacén analítico a gran escala
Azure Synapse Analytic
Azure Synapse Analytics es una solución de un extremo a otro unificada para el análisis de datos a gran escala. Reúne varias tecnologías y funcionalidades, y esto permite combinar la integridad y la confiabilidad de los datos de un almacenamiento de datos relacional basado en SQL Server escalable y de alto rendimiento con la flexibilidad de una solución Apache Spark de código abierto y lago de datos. También incluye compatibilidad nativa para el análisis de registros y telemetría con grupos del Explorador de datos de Azure Synapse, así como canalizaciones de datos integradas para la ingesta y la transformación de datos. Todos los servicios de Azure Synapse Analytics se pueden administrar a través de una única interfaz de usuario interactiva denominada Azure Synapse Studio, que incluye la capacidad de crear cuadernos interactivos en los que se pueden combinar código de Spark y contenido de Markdown. Synapse Analytics es una excelente opción cuando se quiere crear una única solución de análisis unificada en Azure.
Azure Databrick
Azure Databricks es una implementación de Azure de la popular plataforma Databricks. Databricks es una completa solución de análisis de datos integrada en Apache Spark y ofrece funcionalidades nativas de SQL, así como clústeres de Spark optimizados para cargas de trabajo para el análisis de datos y la ciencia de datos. Databricks proporciona una interfaz de usuario interactiva a través de la cual se puede administrar el sistema y se pueden explorar los datos en cuadernos interactivos. Debido a su uso común en varias plataformas en la nube, es posible que quiera considerar el uso de Azure Databricks como almacén analítico si quiere usar la experiencia existente con la plataforma o si necesita operar en un entorno de varias nubes o admitir una solución portátil en la nube.
Azure HDInsight
Azure HDInsight es un servicio de Azure que admite varios tipos de clústeres de análisis de datos de código abierto. Aunque no es tan fácil de usar como Azure Synapse Analytics y Azure Databricks, puede ser una opción adecuada si la solución de análisis se basa en varios marcos de código abierto o si necesita migrar una solución local existente basada en Hadoop a la nube.
Nota
Cada uno de estos servicios puede considerarse como un almacén de datos analíticos, en el sentido de que proporcionan un esquema y una interfaz a través de los cuales se pueden consultar los datos. Sin embargo, en muchos casos, los datos se almacenan realmente en un lago de datos y el servicio se usa para procesar los datos y ejecutar consultas. Algunas soluciones pueden incluso combinar el uso de estos servicios. Un proceso de ingesta de extracción, carga y transformación (ELT) puede copiar datos en el lago de datos y, posteriormente, usar uno de estos servicios para transformar los datos y otro para consultarlos. Por ejemplo, una canalización puede usar un trabajo de MapReduce que se ejecuta en HDInsight o un cuaderno que se ejecuta en Azure Databricks para procesar un gran volumen de datos en el lago de datos y, posteriormente, cargarlo en tablas de un grupo de SQL en Azure Synapse Analytics.
MCT: Video 4.1.2 Descripción de los servicios para el procesamiento de datos moderno
¿Qué es Azure Data Factory?
- Es un servicio de integración de datos
- Su propósito es recuperar datos de uno o más orígenes de datos
- Y convertirlos a una formato que se procese
- Los orígenes de datos pueden presentar datos de formas distintas y contener ruido que se necesita filtrar
- Además permite extraer los datos interesantes y descartar el resto
- Es posible que los datos interesantes no estén en un formato adecuado para que el resto de los servicios de la solución de almacenamiento los procesen, así que se pueden transformar
- Ejemplo:
- Los datos pueden contener fechas y horas con distintos formatos en distintos orígenes de datos
- Se puede utilizar Azure Data Factory para transformar estos datos en una única estructura uniforme
- Posteriormente Azure data Factory puede escribir los datos ingeridos en un almacén de datos para su posterior procesamiento
- El trabajo que realiza Azure Data Factory se define como una canalización de operaciones
- Una canalización se puede ejecutar continuamente ya que los datos se reciben desde los distintos orígenes de datos
- Se pueden crear las canalizaciones mediante la interfaz gráfica de usuario que proporciona Azure o escribiendo su propio código
¿Qué es Azure Data Lake Storage?
- Un lago de datos es un repositorio para una gran cantidad de datos sin procesar
- Como los datos están sin procesar es muy rápido cargarlos y actualizarlos
- Pero los datos no tienen una estructura adecuada para realizar un análisis eficaz
- Una lago de datos se puede considerar como un punto de almacenamiento provisional para los datos ingeridos, antes que se acomoden y se conviertan en un formato adecuado para realizar el análisis
- Combina la semántica jerárquica del sistema de archivos y la estructura de directorios de un sistema de archivos tradicional con la seguridad y la escalabilidad que ofrece Azure
- Básicamente es una extensión de Azure Blob Storage que se organiza como un sistema de archivos casi infinito
- Las características son:
- La mejor organización de los archivos: organiza los archivos en directorios y subdirectorios para mejorar la organización de los archivos. Blob Storage solo puede limitar una estructura de directorio
- Permisos de POSIX: admite los permisos del archivo y directorio Portable Operating System Interface para habilitar el control de acceso basado en roles RBAC
- Compatible con HDFS: es compatible con el sistema de archivos distribuido de Hadoop
- Hadoop es un servicio de análisis muy flexible y programable que utilizan muchas organizaciones para examinar grandes cantidades de datos. Todos los entornos de Apache Hadoop pueden acceder a los datos de Azurer Data Lake Storage a partir de la generación 2
¿Qué es Azure Databrick?
- Es un entorno de Apache Spark que se ejecuta en Azure
- Proporciona procesamiento de macrodatos, streaming y aprendizaje automático

- Es un motor de procesamiento de datos muy eficaz que puede consumir grandes cantidades de datos y procesarlos con mucha rapidez
- Existe una considerable cantidad de bibliotecas de Spark que se pueden utilizar para realizar tareas como el procesamiento de SQL, las agregaciones, así como compilar y entrenar modelos de Machine Learning

- Proporciona una interfaz gráfica de usuario en la cual se puede definir y probar el procesamiento paso a paso, antes de enviarlo como un conjunto de tareas por lotes
- Se puede crear script’s de DataBricks y consultar datos mediante lenguajes como R, python, XXX
- El código de spark se escribe mediante cuadernos un cuaderno contiene celdas y cada una de estas incluye un bloque de código independiente
- Al ejecutar un cuaderno el código de cada celda se pasa por Spark uno a uno para su ejecución
¿Qué es Azure Synapse Analytic?
- Es un motor de análisis que esta diseño para procesar grandes cantidades de datos con mucha rapidez

- Se pueden ingerir datos de orígenes externos como archivos planos, Azure Data Lake u otros sistema de Administración de bases de datos
- Y después se pueden transformar estos datos y agregarlos a un formato adecuado para el procesamiento de análisis
- Se pueden realizar consultas complejas sobre estos datos y generar informes, grafos y gráficos
- La lectura y transformación de datos de un origen externo puede consumir bastantes recursos
- Azure Synapse Analytic permite almacenar los datos que ha leído y procesado localmente dentro del servicio
- Este enfoque permite consultar repetidamente los mismos datos sin la sobre carga que supone capturarlos y convertirlos
- también se pueden utilizar estos datos como la entrada para realizar un procesamiento analítico adicional mediante Azure Analytic Service
- Azure Synapse Analytic utiliza una arquitectura de procesamiento paralelo masivo
- Esta arquitectura incluye un nodo de control y un grupo de nodos de ejecución
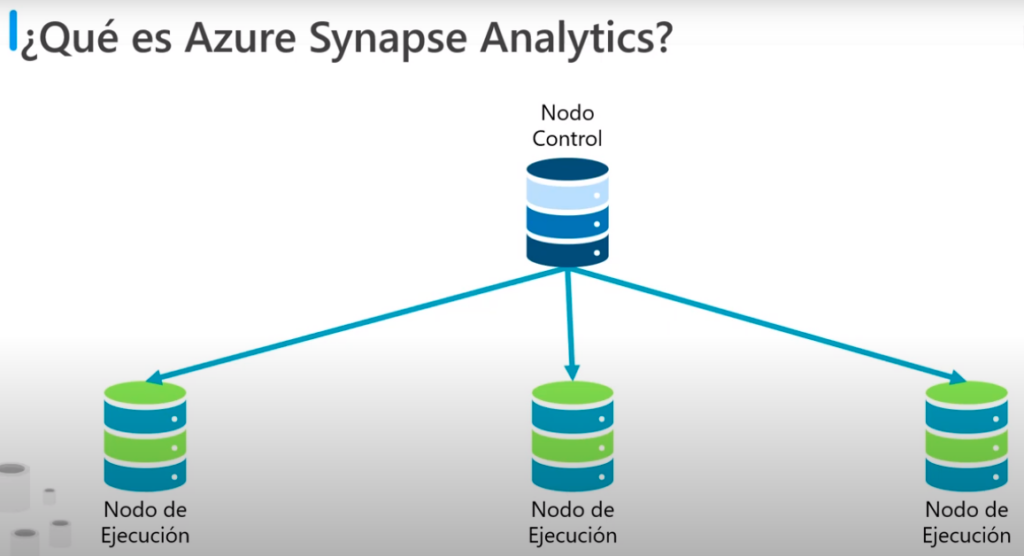
- El nodo de control es el cerebro de la arquitectura, es el front end que interactuá con las aplicaciones
- El motor se ejecuta con el nodo de control para optimizar y coordinar las consultas en paralelo
- Cuando se envía una solicitud de procesamiento el nodo de control la transforma en solicitudes más pequeñas que se ejecutan en distintos sub-conjuntos de datos en paralelo
- Los nodos de ejecución proporcionan la potencia computacional
- Los datos que se van a procesar se distribuyen uniformemente entre los nodos
- Los usuarios y las aplicaciones que envían solicitudes de procesamiento al nodo de control, este envían las solicitudes a los nodos de ejecución que las ejecutan las en la porción de datos que ellos contienen
- Cuando todos los nodos finalizan el procesamiento los resultados se devuelven al nodo de control, donde se combinan en un resultado global
¿Qué es Azure Analysis Services?
- Permite compilar modelos tabulares para admitir consultas de procesamiento analítico en linea
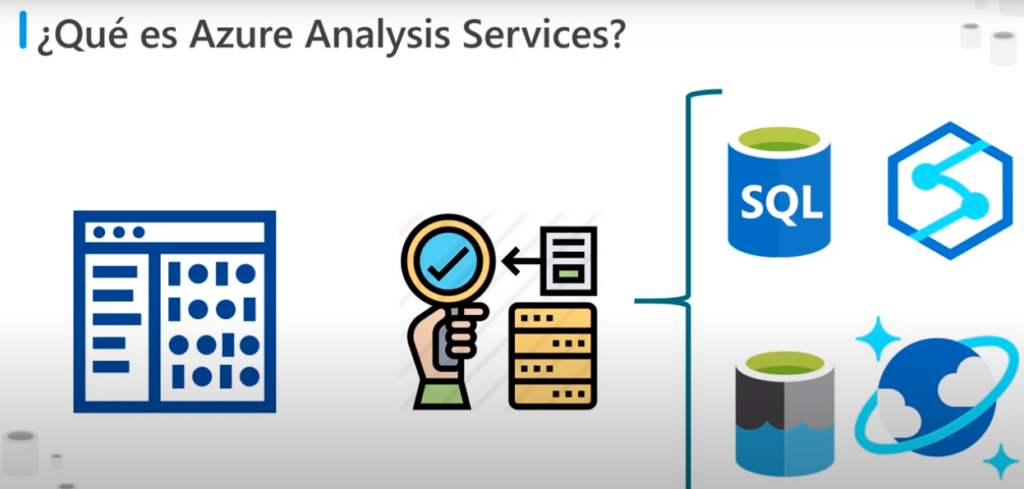
- Puede combinar datos de varios orígenes como: Azure SQL Data Base, Azure Synapse Analytic, Azure Data Lake Storage ; Azure Cosmos DB y muchos otros
- Estos orígenes de datos utilizan para compilar modelos que incorporan su conocimiento empresarial
- Un modelo es un conjunto de consultas y expresiones que recuperan datos de los distintos orígenes datos y generan resultados
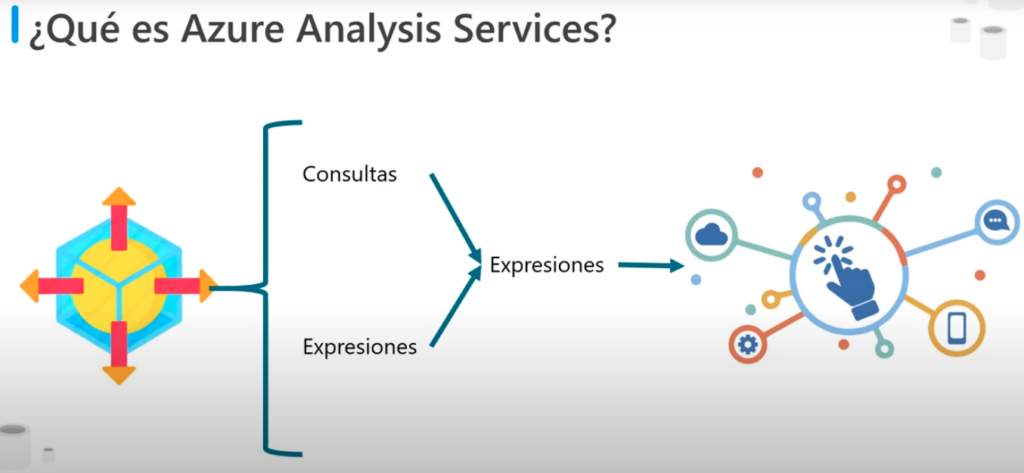
- Los resultados se pueden copiar en la caché, en la memoria para su uso posterior
- o se pueden calcular dinámicamente a partir de os orígenes de datos subyacentes

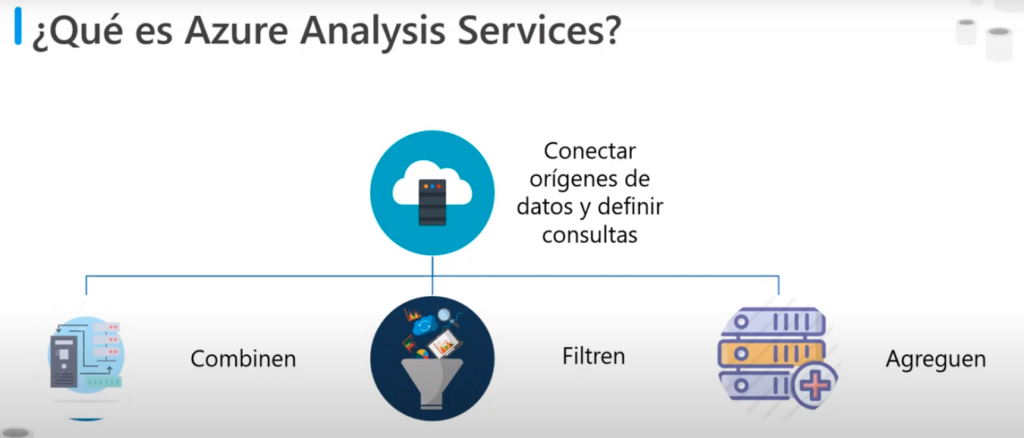
- Incluye un diseño gráfico para ayudar a conectar orígenes de datos y definir consultar que Combinen, Filtren y Agreguen datos
- Se pueden explorar estos datos desde Azure Analytic Services o se puede utilizar una herramienta como Microsoft Power BI
Comparación de Analytics Services vs Synapse Analytic
Azure Analysis Services
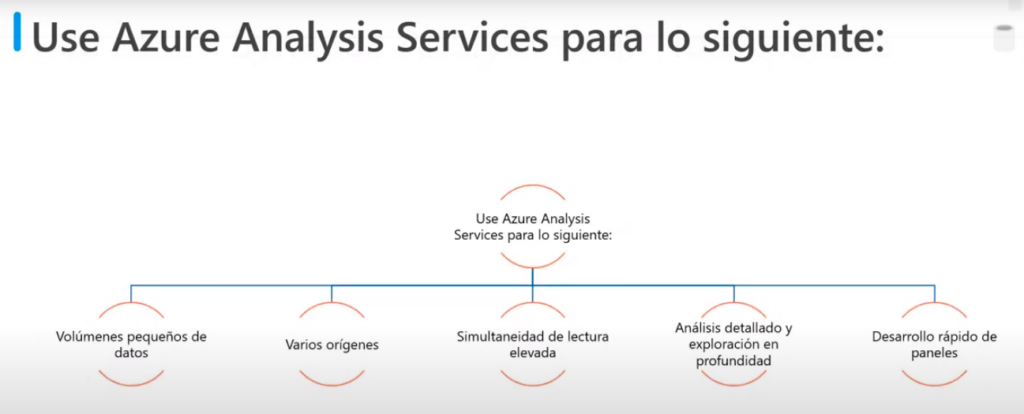
- Tiene una superposición funcional considerable con Azure Synpase Analytic, pero es más adecuado para realizar un procesamiento a una escala menor
- Se utiliza para:
- Volúmenes pequeños de datos (pocos TB)
- varios orígenes
- Simultaneidad de lectura elevada (miles de usuarios)
- Análisis detallado y exploración en profundidad de los datos mediante las funciones de Power BI
- Desarrollo rápido de paneles a partir de datos tabulares
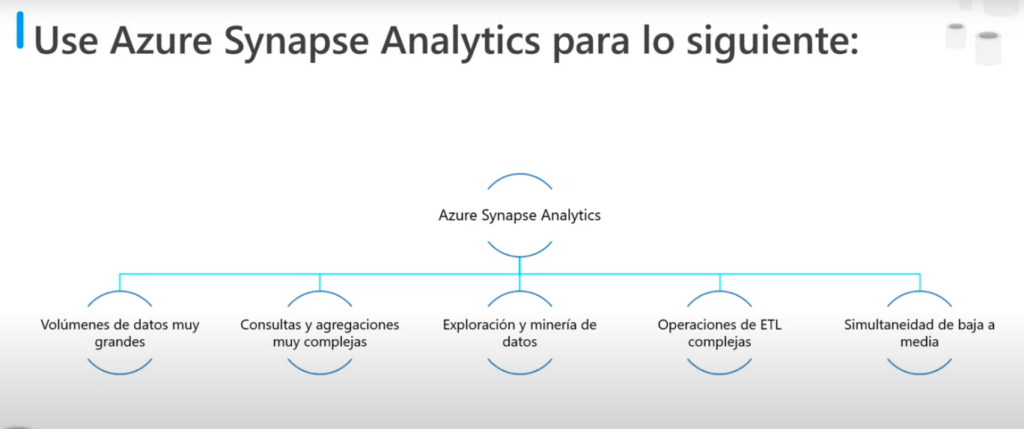
Azure Synpase Analytics
- Se utiliza para
- Volúmenes de datos muy grandes desde TB a pentabytes
- Consultas y agregaciones muy complejas
- Exploración y minería de datos
- Operaciones de WTL complejas
- Simultaneidad de baja a media
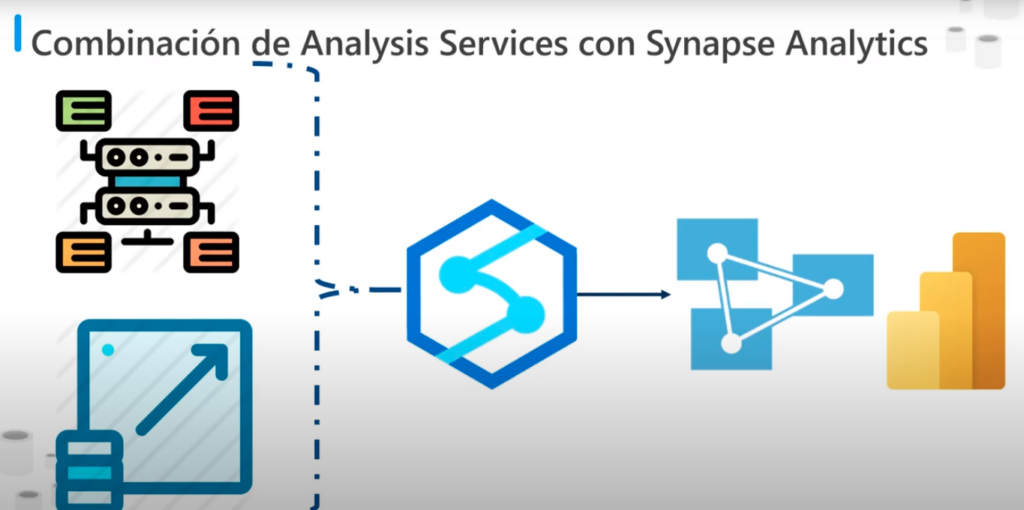
Combinación de Analytics Services con Synapse Analytic
- Si se tiene grandes cantidades de datos ingeridos que requieren procesamiento se puede utilizar Azure Synapse Analytic para leer estos datos y manipularlos en un modelo que incluya información empresarial en lugar de una gran cantidad de datos sin procesar
- Azure Synapse Analytic permite procesar y reducir muchos TB’s de datos en un conjunto de datos concisos y más pequeño que resumen y agrega gran parte de estos datos
- Posteriormente se puede utilizar Azure Analysis Service para realizar el interrogatorio detallado de esta información y visualizar los resultados de estas consultas con Power BI
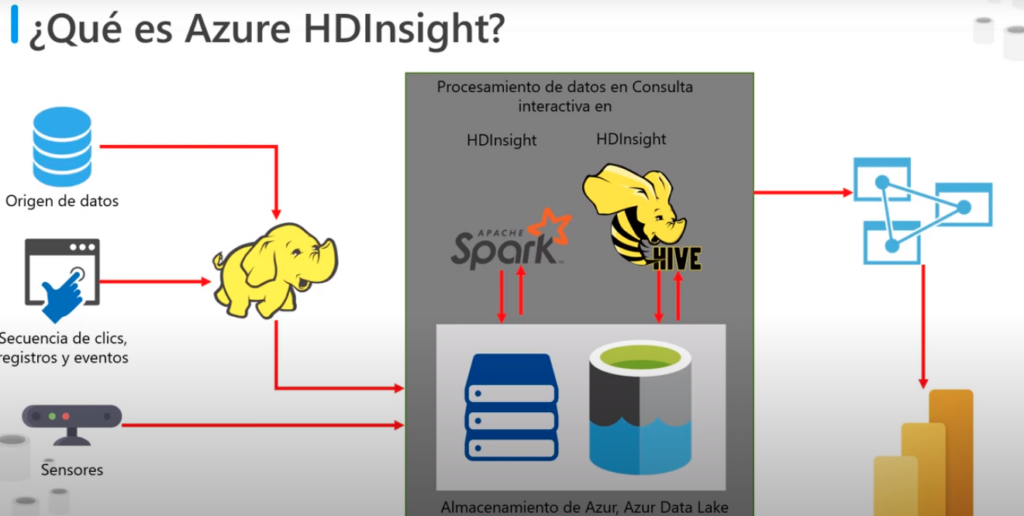
¿Qué es Azure HDInsight?
- Es un modelo de servicio de procesamiento de macrodatos
- Que proporciona la plataforma para tecnologías como Spark en un entrono de Azure
- Implementa un modelo de cluster que distribuye el procesamiento en un conjunto de equipos
- Este modelo es similar al que utiliza Azure Synapse Analytic
- Pero los nodos ejecutan el modelo de procesamiento de spark en lugar de Azure SQL Database
- Se puede utilizar Azure HDInsight junto a Azure Synapse Analytic
- Ademas de Spark también permite tecnologías de streaming como apache o el modelo de procesamiento de Haddop
Unidad 5: Ejercicio: exploración de Azure Synapse Analytics
En este ejercicio, creará un área de trabajo de Azure Synapse Analytics y la usará para ingerir y analizar algunos datos.
El ejercicio está diseñado para que pueda familiarizarse con algunos elementos clave de una solución moderna de almacenamiento de datos, no como una guía completa para realizar análisis avanzados de datos con Azure Synapse Analytics. El ejercicio debe tardar unos 30 minutos en completarse.
Nota
Para completar este ejercicio, necesitará una suscripción a Microsoft Azure. Si aún no tiene una, puede solicitar una prueba gratuita en https://azure.microsoft.com/free. No puede usar una suscripción de espacio aislado de Microsoft Learn para este ejercicio.
Aprovisionar un área de trabajo de Azure Synapse Analytics
Para usar Azure Synapse Analytics, debe aprovisionar un recurso en el área de trabajo de Azure Synapse Analytics en la suscripción de Azure.
Abra Azure Portal en https://portal.azure.com e inicie sesión con las credenciales asociadas con su suscripción de Azure.

En Azure Portal, en la página Inicio, use el icono + Crear para recurso para crear un nuevo recurso.
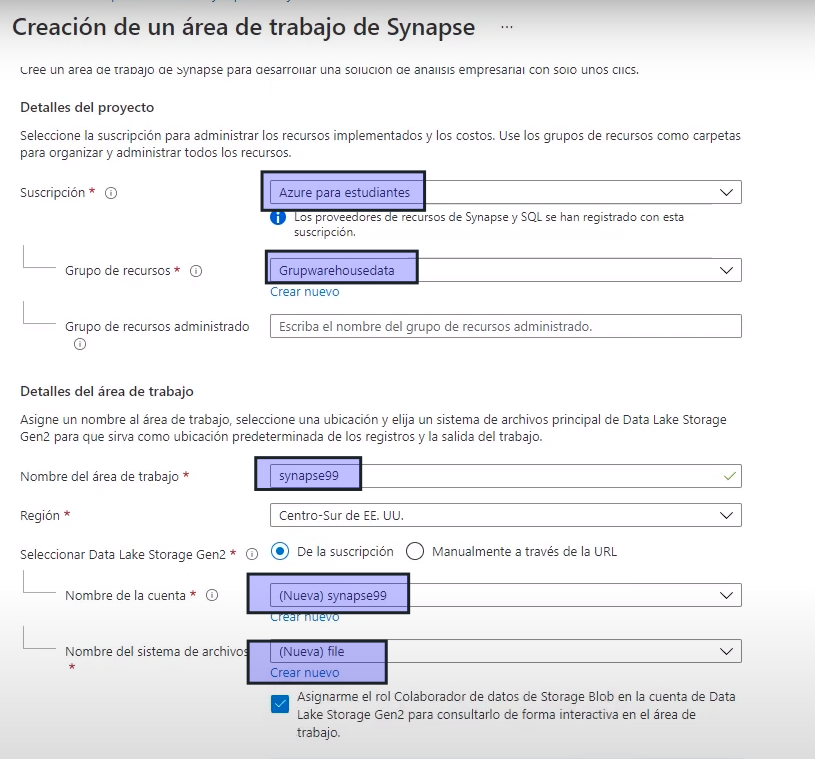
Busque Azure Synapse Analytics, y cree un recurso de Azure Synapse Analytics con la siguiente configuración:
- Suscripción: suscripción de Azure
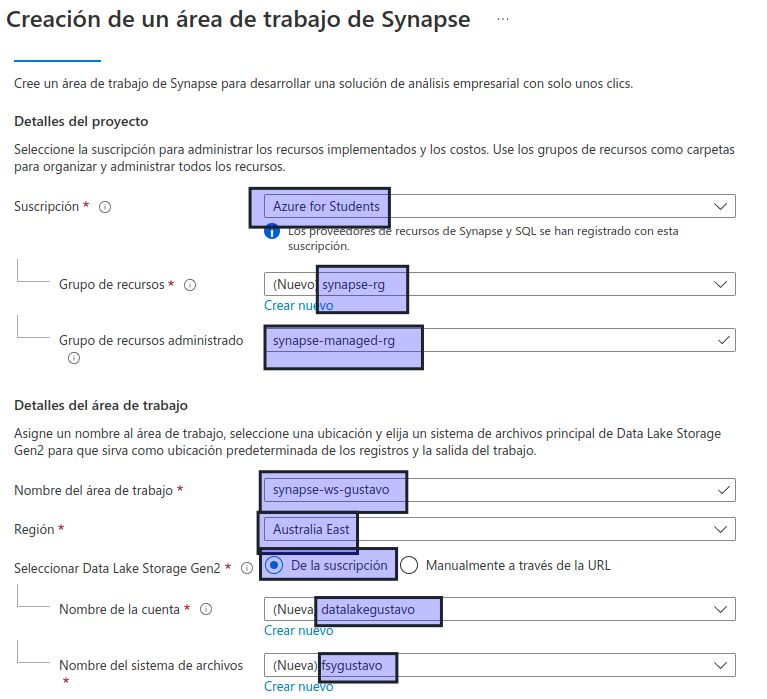
- Grupo de recursos: cree un grupo de recursos con un nombre apropiado, como «synapse-rg».
- Grupo de recursos administrado: escriba un nombre adecuado, por ejemplo, «synapse-managed-rg».
- Nombre del área de trabajo: escriba un nombre único para el área de trabajo, por ejemplo, «synapse-ws-su_nombre».
- Región: seleccione cualquiera de las siguientes regiones:
- Este de Australia
- Centro de EE. UU.
- Este de EE. UU. 2
- Norte de Europa
- Centro-sur de EE. UU.
- Sudeste de Asia
- Sur de Reino Unido
- Oeste de Europa
- Oeste de EE. UU.
- WestUS 2
- Seleccionar Data Lake Storage Gen 2: en la suscripción.
- Nombre de cuenta: cree una cuenta con un nombre único, por ejemplo, «datalakeyour_name».
- Nombre del sistema de archivos: cree un sistema de archivos con un nombre único, por ejemplo, «fsyour_name».
Nota
Un área de trabajo de Synapse Analytics requiere dos grupos de recursos en la suscripción de Azure; uno para los recursos creados explícitamente y otro para los recursos administrados utilizados por el servicio. También requiere una cuenta de almacenamiento de Data Lake en la que almacenar datos, scripts y otros artefactos.

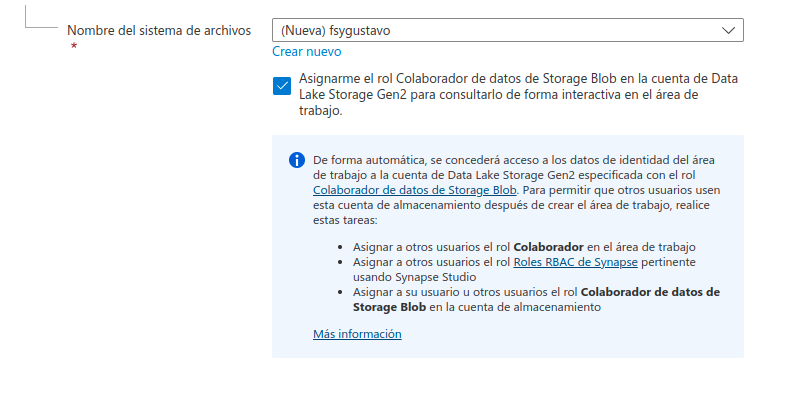
Cuando haya especificado estos detalles, seleccione Revisar y crear y, a continuación, seleccione Crear para crear el área de trabajo.
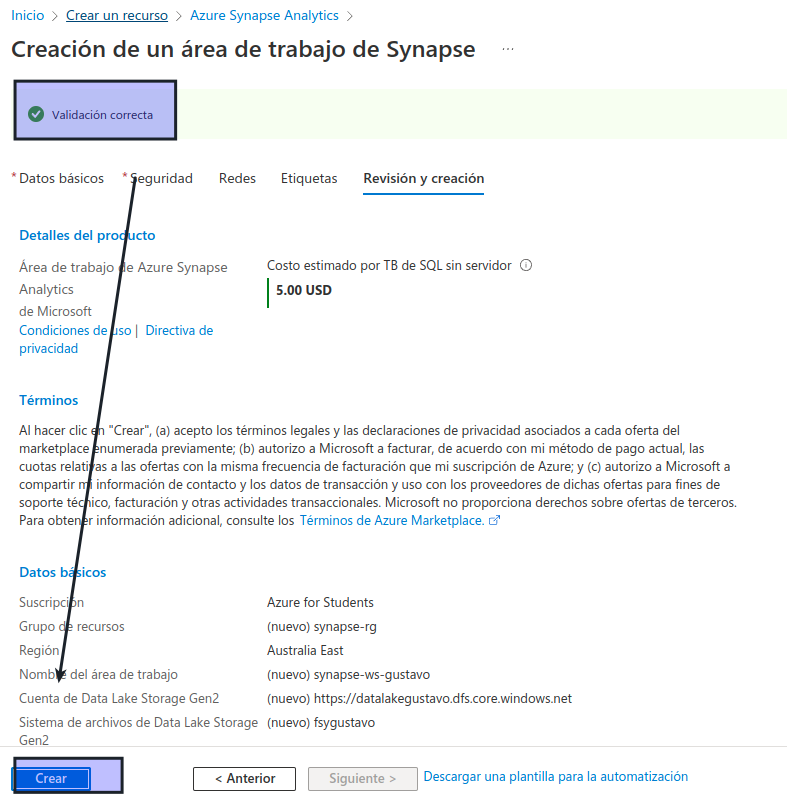
Espere a que se cree el área de trabajo; puede tardar unos cinco minutos.
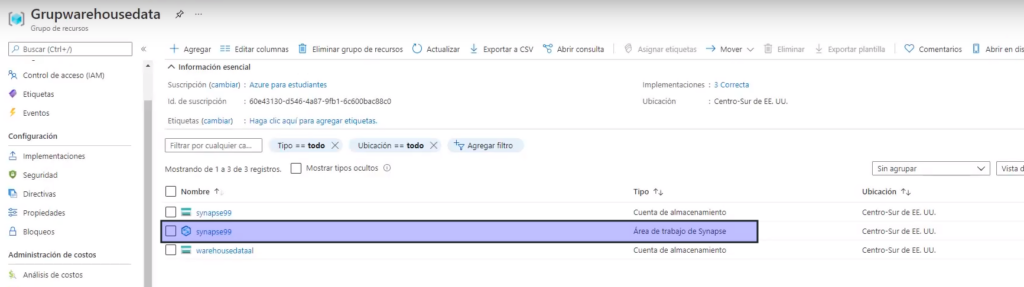
Una vez completada la implementación, vaya al grupo de recursos que se creó y observe que contiene el área de trabajo de Synapse Analytics y una cuenta de almacenamiento de Data Lake.
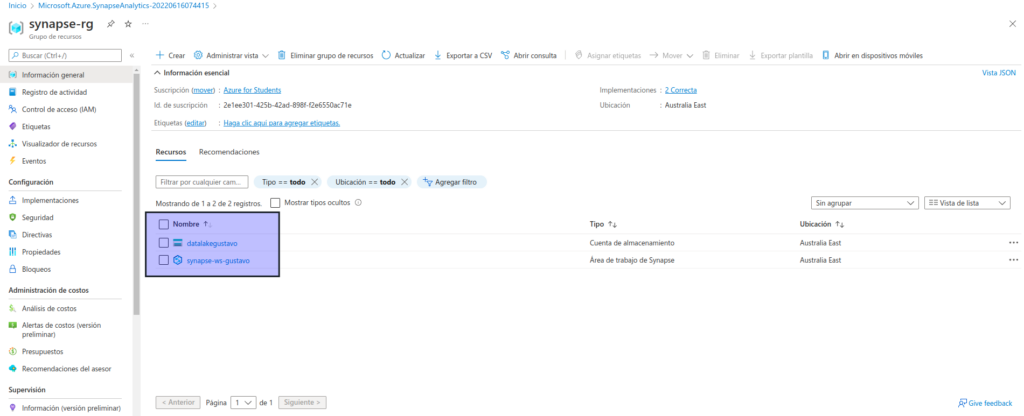
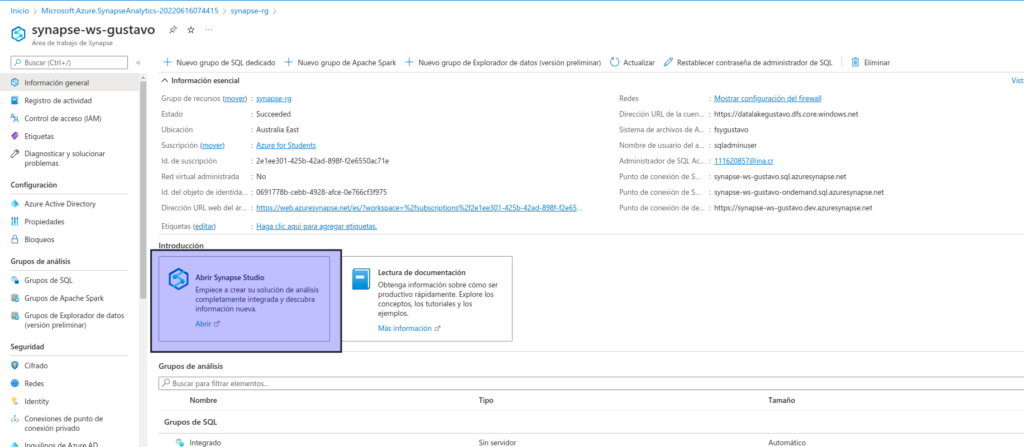
Seleccione el área de trabajo de Synapse y, en su página Información general, en la tarjeta Abrir Synapse Studio, seleccione Abrir para abrir Synapse Studio en una nueva pestaña del explorador. Synapse Studio es una interfaz basada en web que puede usar para trabajar con el área de trabajo de Synapse Analytics.
En el lado izquierdo de Synapse Studio, use el icono ›› para expandir el menú; esto muestra las distintas páginas de Synapse Studio que usará para administrar recursos y realizar tareas de análisis de datos, como se muestra aquí:
Ingerir datos
Una de las tareas clave que puede realizar con Azure Synapse Analytics es definir canalizaciones que transfieran (y, si es necesario, transformen) datos de una amplia variedad de orígenes al área de trabajo para su análisis.
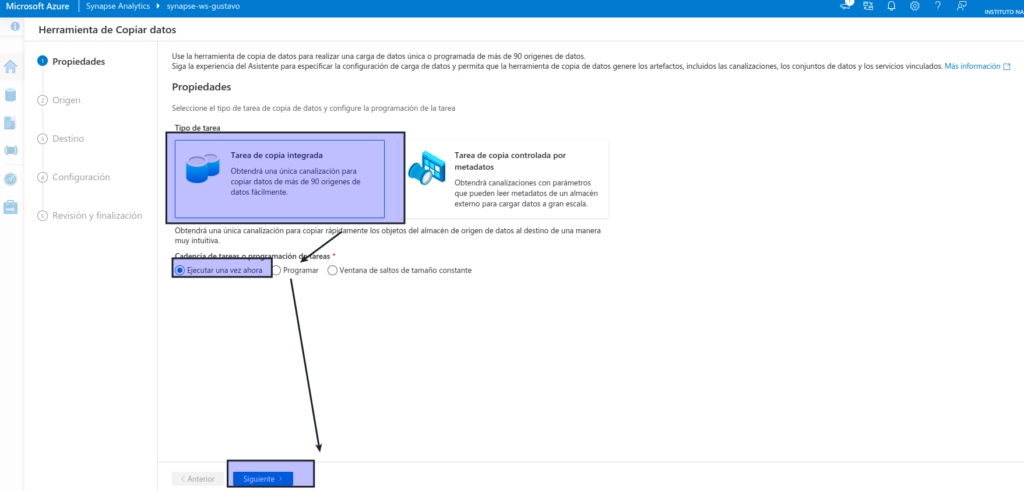
En la página Inicio de Synapse Studio, seleccione Ingerir y, después, haga clic en Built-in copy task (Tarea de copia integrada) para abrir la herramienta Copiar datos.
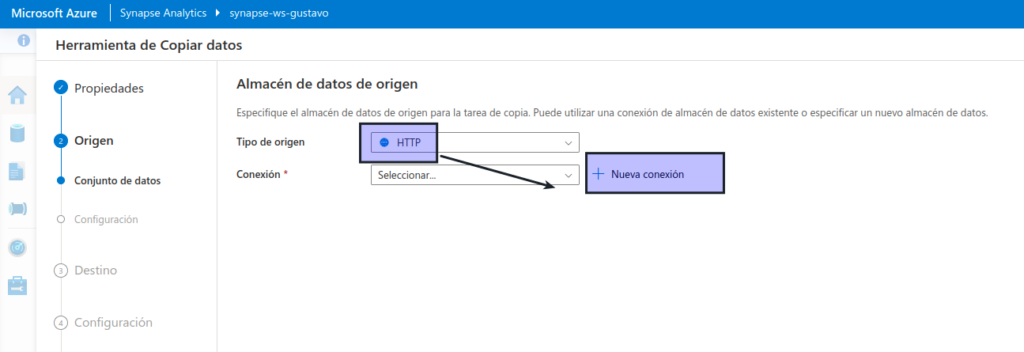
En el paso Origen, en el subpaso Conjunto de datos, seleccione la siguiente configuración:
- Tipo de origen: HTTP
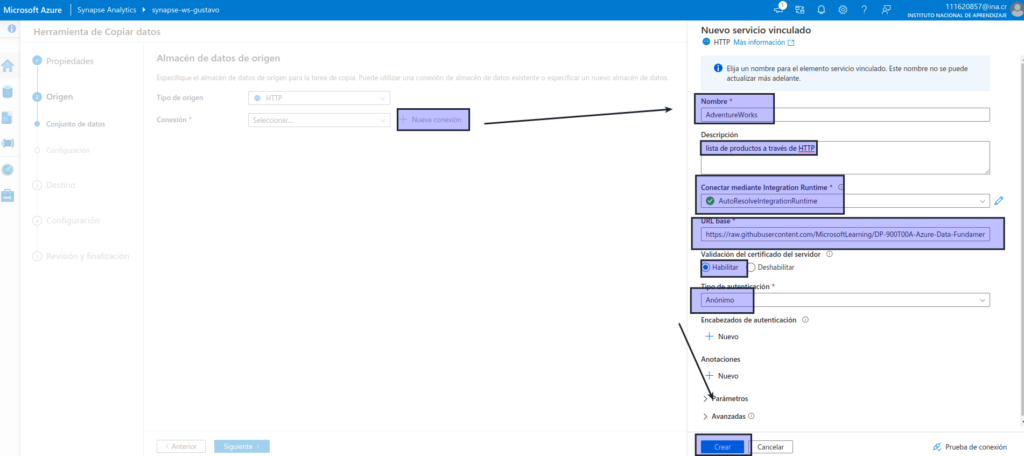
- Conexión: cree una conexión con las propiedades siguientes:
- Nombre: productos de AdventureWorks
- Descripción: lista de productos a través de HTTP
- Conectar mediante Integration Runtime: AutoResolveIntegrationRuntime
- Dirección URL base: https://raw.githubusercontent.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/master/Azure-Synapse/products.csv
- Validación del certificado de servidor: habilitar
- Tipo de autenticación: anónimo
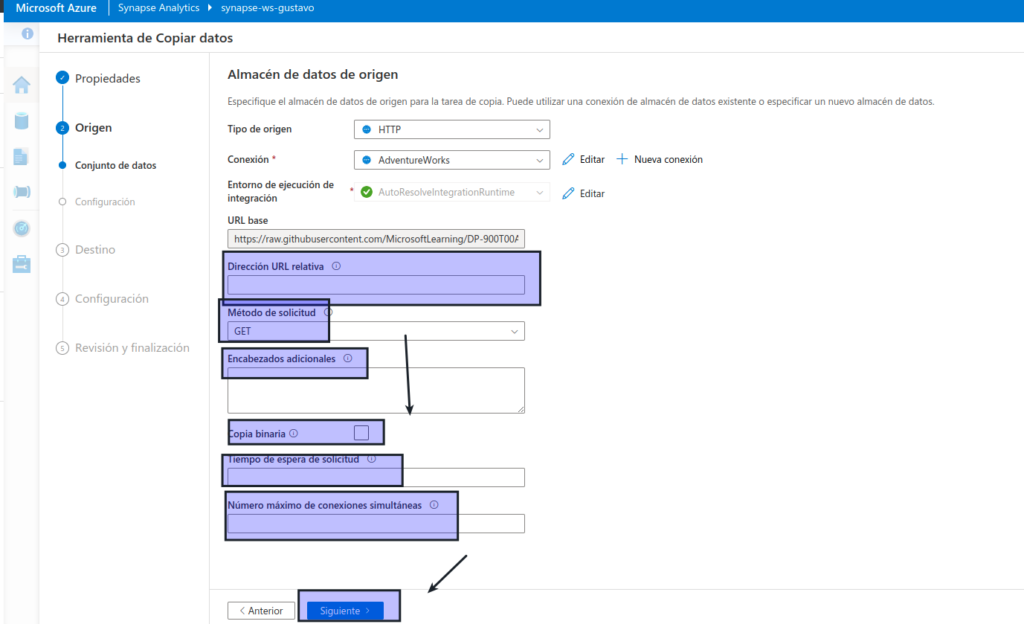
Después de crear la conexión, en el subpaso Origen/Conjunto de datos, asegúrese de que está seleccionada la siguiente configuración y, a continuación, seleccione Siguiente :
- Dirección URL relativa: dejar en blanco
- Request method (Método de solicitud): GET
- Encabezados adicionales: dejar en blanco
- Copia binaria: sin seleccionar
- Tiempo de espera de solicitud: dejar en blanco
- Número máximo de conexiones simultáneas: dejar en blanco
En el paso Origen, en el subpaso Configuración, seleccione Vista previa de los datos para obtener una vista previa de los datos del producto que la canalización va a ingerir y, a continuación, cierre la vista previa.
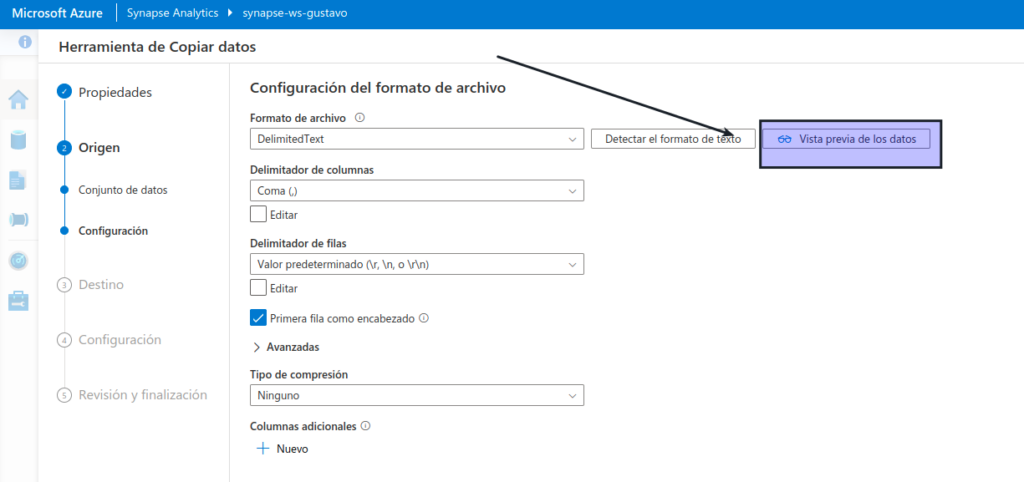
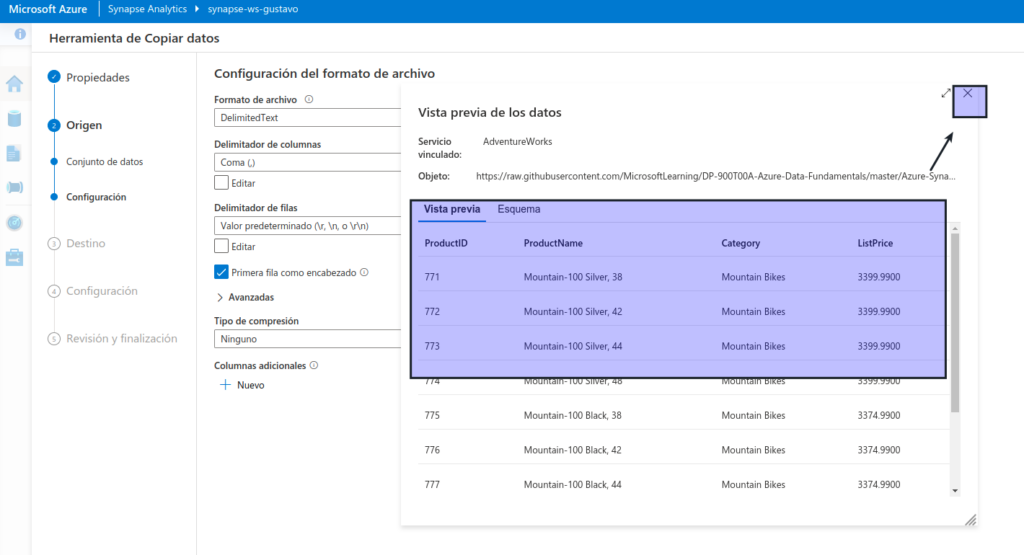
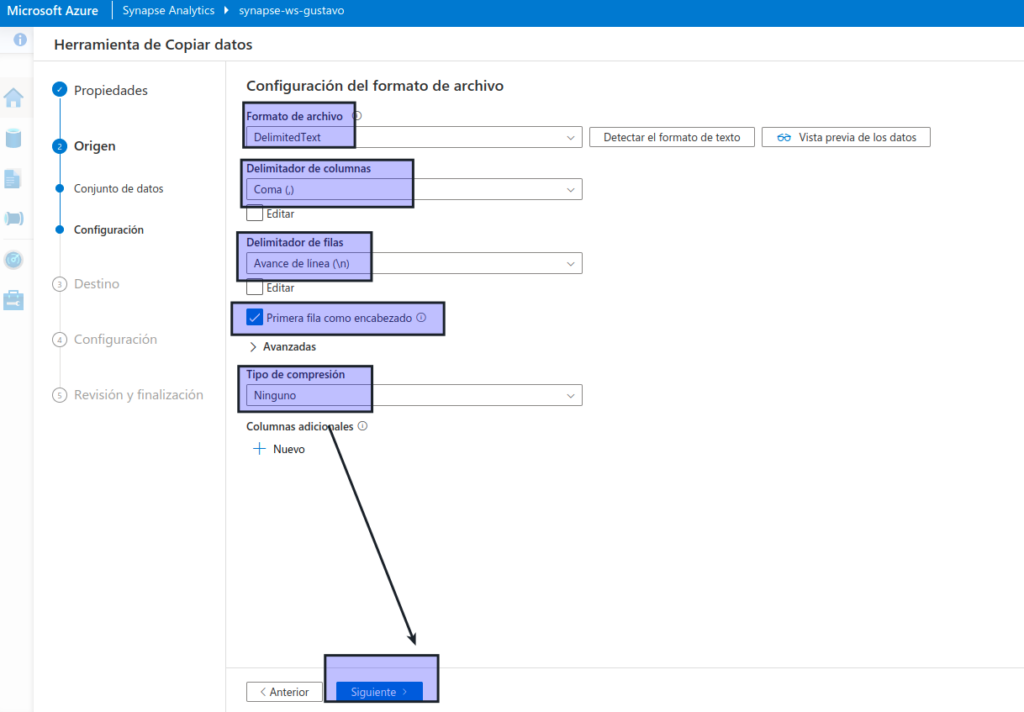
Después de previsualizar los datos, en el paso Origen/Configuración, asegúrese de que está seleccionada la siguiente configuración y, a continuación, seleccione Siguiente :
- Formato de archivo: DelimitedText
- Delimitador de columna: coma (,)
- Delimitador de fila: avance de línea (\n)
- Primera fila como encabezado: seleccionada
- Tipo de compresión: ninguno
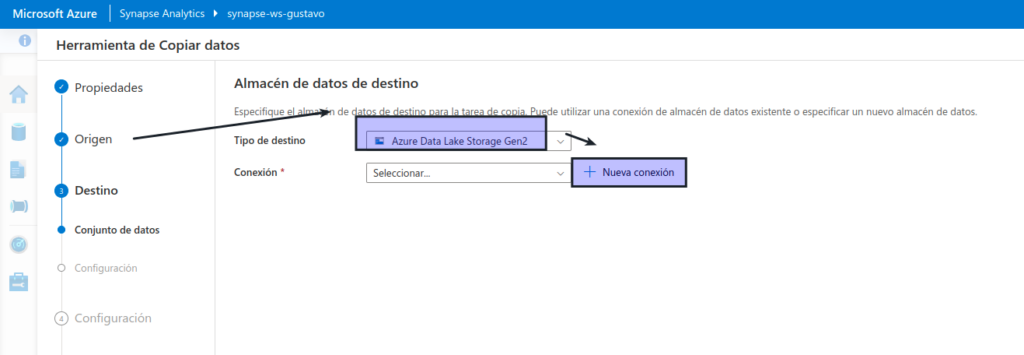
En el paso Destino, en el subpaso Conjunto de datos, seleccione la siguiente configuración:
- Tipo de destino: Azure Data Lake Storage Gen 2
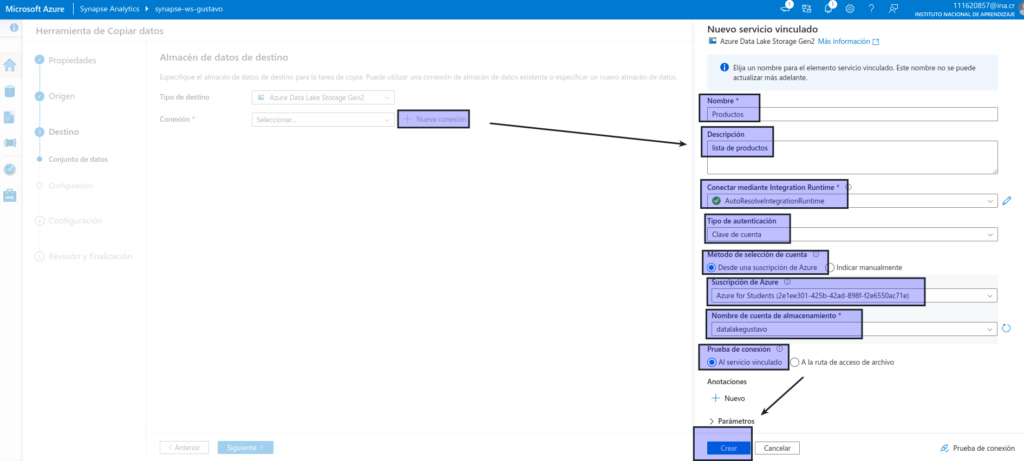
- Conexión: cree una conexión con las siguientes propiedades:
- Nombre: Productos
- Descripción: lista de productos
- Conectar mediante Integration Runtime: AutoResolveIntegrationRuntime
- Método de autenticación: clave de cuenta
- Método de selección de cuenta: desde la suscripción
- Suscripción de Azure: seleccione su suscripción
- Nombre de la cuenta de almacenamiento: seleccione su cuenta de almacenamiento
- Prueba de conexión: al servicio vinculado
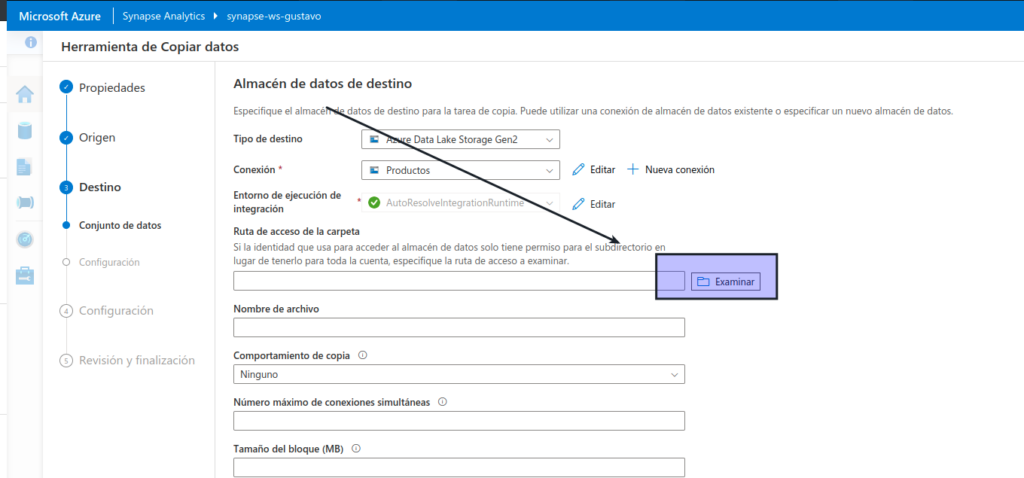
Después de crear la conexión, en el paso Destino/Conjunto de datos, asegúrese de que está seleccionada la siguiente configuración y, a continuación, seleccione Siguiente :
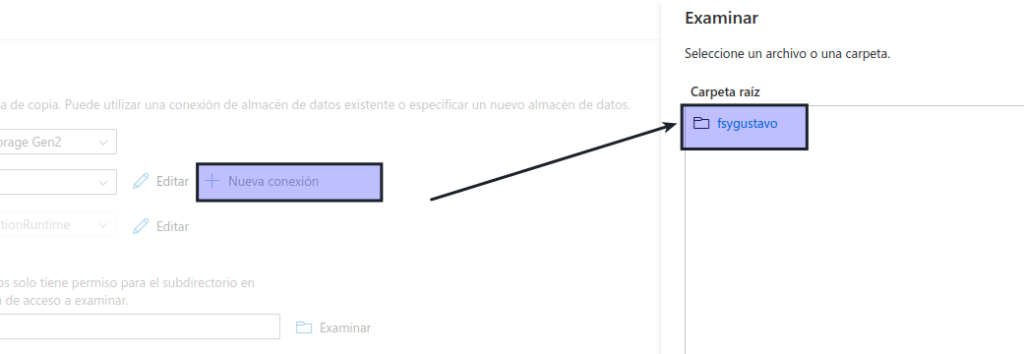
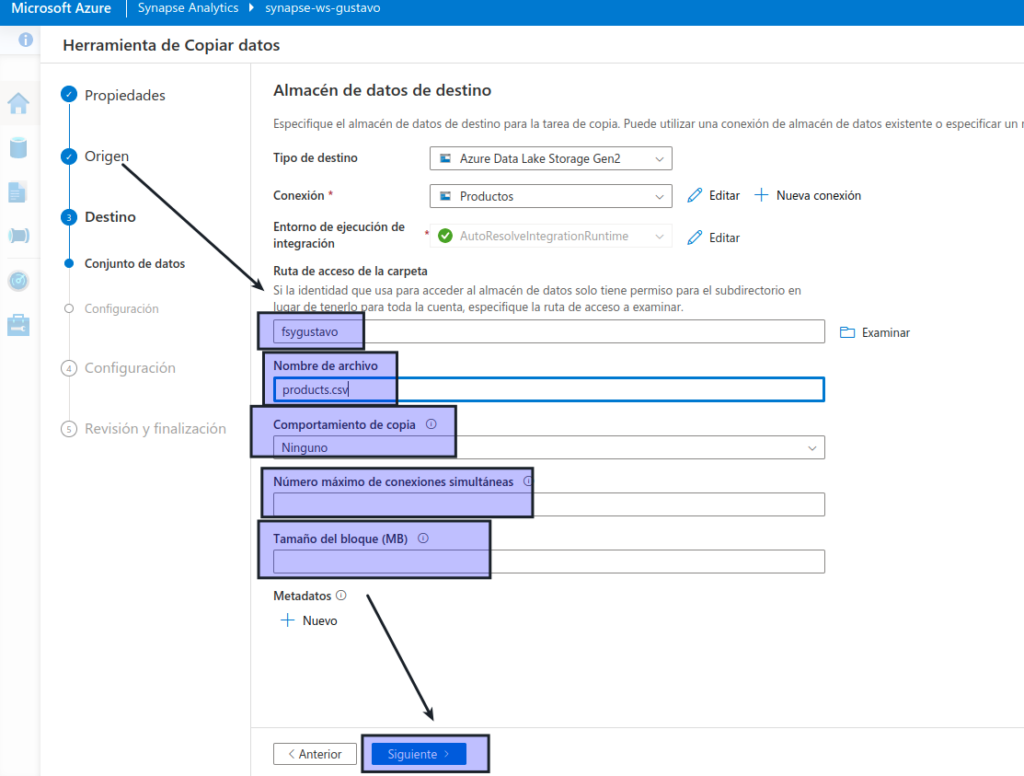
- Ruta de acceso de la carpeta: vaya a la carpeta del sistema de archivos
- Nombre de archivo: products.csv
- Comportamiento de copia: ninguno
- Número máximo de conexiones simultáneas: dejar en blanco
- Tamaño de bloque (MB): dejar en blanco
En el paso Destino, en el subpaso Configuración, asegúrese de que están seleccionadas las siguientes propiedades. Luego, seleccione Siguiente :
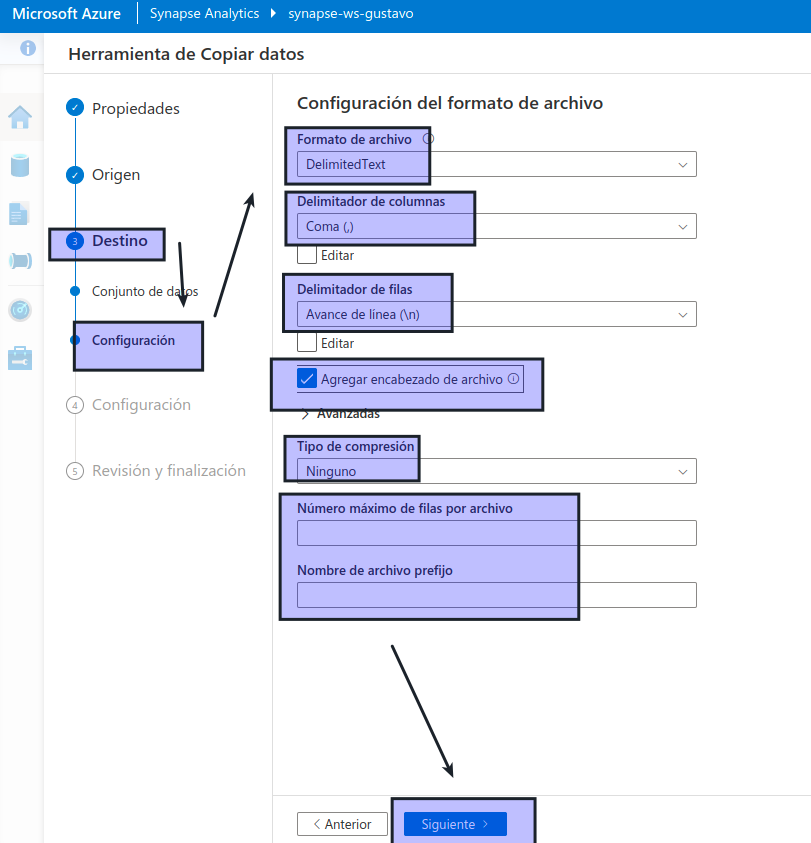
- Formato de archivo: DelimitedText
- Delimitador de columna: coma (,)
- Delimitador de fila: avance de línea (\n)
- Agregar encabezado al archivo: seleccionado
- Tipo de compresión: ninguno
- Número máximo de filas por archivo: dejar en blanco
- Prefijo de nombre de archivo: dejar en blanco
En el paso Configuración, configure las opciones siguientes y, a continuación, haga clic en Siguiente :
- Nombre de tarea: copiar productos
- Descripción de la tarea: copia de datos de productos
- Tolerancia a errores: dejar en blanco
- Habilitar registro: sin seleccionar
- Habilitar almacenamiento provisional: sin seleccionar
En el paso Revisar y finalizar, en el subpaso Revisar, lea el resumen y, a continuación, haga clic en Siguiente .
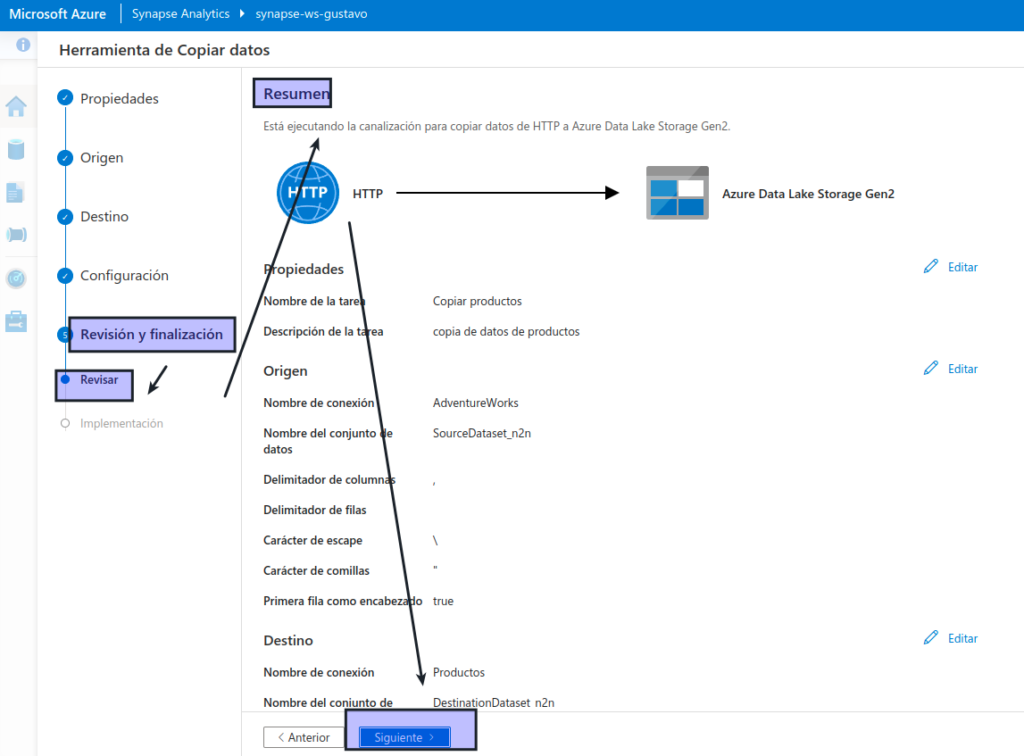
En el paso Implementación, espere a que se implemente la canalización y, a continuación, haga clic en Finalizar.
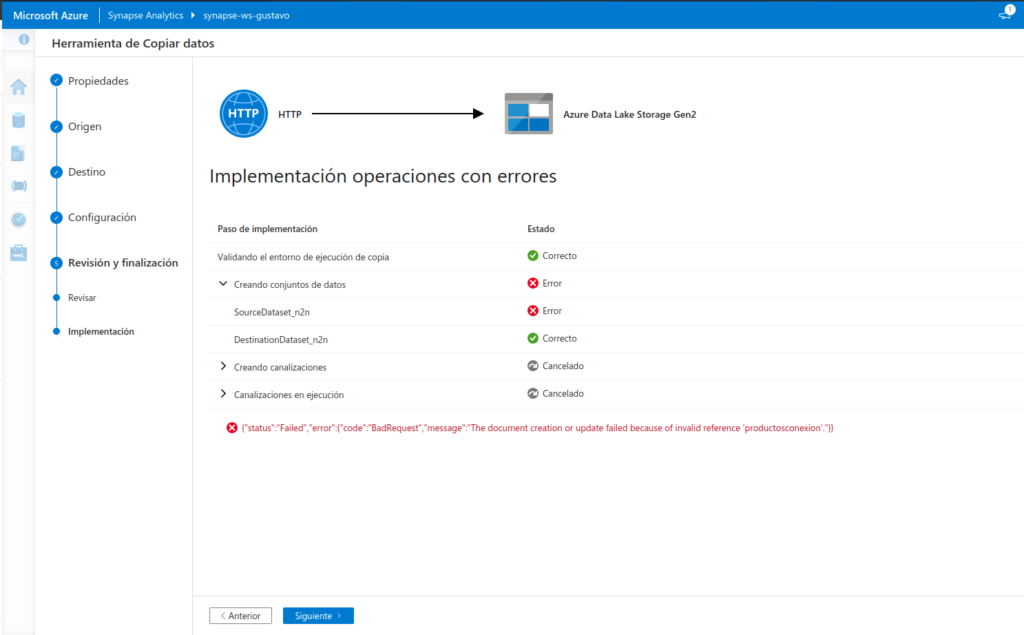
- En Synapse Studio, seleccione la página Supervisar y, en la pestaña Ejecuciones de canalizaciones, espere a que la canalización Copy products se complete con el estado Correcto (puede usar el botón ↻ Actualizar de la página Ejecuciones de canalizaciones para actualizar el estado).
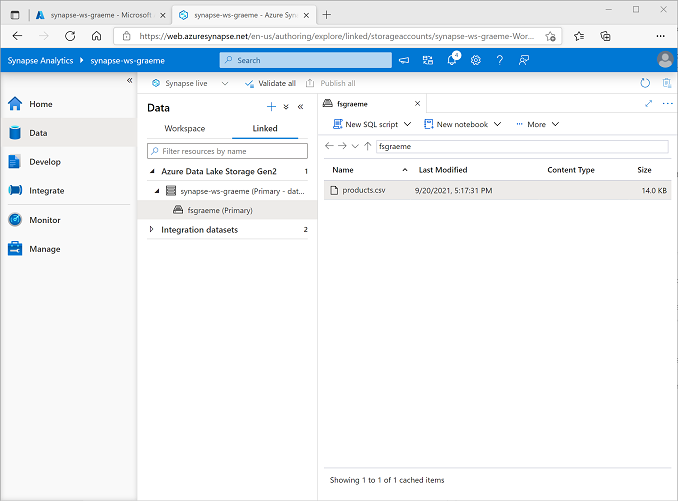
- En la página Datos, seleccione la pestaña Vinculado y expanda la jerarquía de Azure Data Lake Storage Gen 2 hasta que vea el almacenamiento de archivos para el área de trabajo de Synapse. A continuación, seleccione el almacenamiento de archivos para comprobar que un archivo llamado products.csv se ha copiado en esta ubicación, como se muestra aquí:
Usar un grupo de SQL para analizar datos
Ahora que ha ingerido algunos datos en el área de trabajo, puede usar Synapse Analytics para consultarlos y analizarlos. Una de las formas más comunes de consultar datos es usar SQL y, en Synapse Analytics, puede usar un grupo de SQL para ejecutar código SQL.
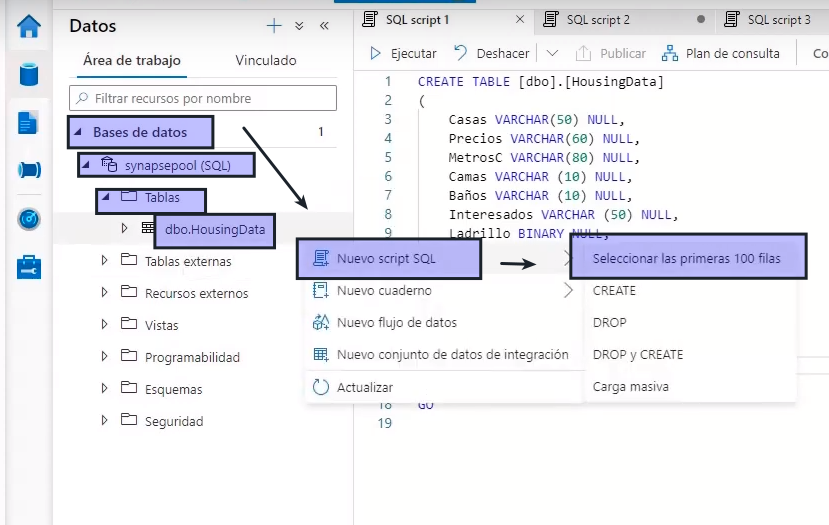
En Synapse Studio, haga clic con el botón derecho en el archivo products.csv del almacenamiento de archivos del área de trabajo de Synapse, seleccione New SQL script (Nuevo script SQL) y seleccione Seleccionar las primeras 100 filas.
En el panel SQL Script 1 (Script SQL 1) que se abre, revise el código SQL que se ha generado, que debe ser similar al siguiente:
-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0'
) AS [result]Este código abre un conjunto de filas del archivo de texto que importó y recupera las primeras 100 filas de datos.
En la lista Conectar a, asegúrese de que Integrado está seleccionado: representa el grupo de SQL integrado que se creó con el área de trabajo.
En la barra de herramientas, use el botón ▷ Ejecutar para ejecutar el código SQL y revise los resultados, que deben tener un aspecto similar al siguiente:
| C1 | c2 | c3 | c4 |
|---|---|---|---|
| ProductID | ProductName | Category | ListPrice |
| 771 | Mountain-100 Silver, 38 | Bicicletas de montaña | 3399.9900 |
| 772 | Mountain-100 Silver, 42 | Bicicletas de montaña | 3399.9900 |
| … | … | … | … |
Tenga en cuenta que los resultados constan de cuatro columnas denominadas C1, C2, C3 y C4, y que la primera fila de los resultados contiene los nombres de los campos de datos. Para corregir este problema, agregue un parámetro HEADER_ROW = TRUE a la función OPENROWSET tal como se muestra aquí (reemplace datalakexx y fsxx por los nombres de la cuenta de almacenamiento del lago de datos y el sistema de archivos) y, luego, vuelva a ejecutar la consulta:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
) AS [result]Ahora los resultados son similares a los siguientes:
| ProductID | ProductName | Category | ListPrice |
|---|---|---|---|
| 771 | Mountain-100 Silver, 38 | Bicicletas de montaña | 3399.9900 |
| 772 | Mountain-100 Silver, 42 | Bicicletas de montaña | 3399.9900 |
| … | … | … | … |
Modifique la consulta como se muestra a continuación (reemplazando datalakexx y fsxx por los nombres de la cuenta de almacenamiento de Data Lake y del sistema de archivos):
SELECT
Category, COUNT(*) AS ProductCount
FROM
OPENROWSET(
BULK 'https://datalakexx.dfs.core.windows.net/fsxx/products.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
HEADER_ROW = TRUE
) AS [result]
GROUP BY Category;Ejecute la consulta modificada, que debe devolver un conjunto de resultados que contenga el número de productos de cada categoría, de la siguiente forma:
| Category | ProductCount |
|---|---|
| Culotes | 3 |
| Bastidores de bicicletas | 1 |
| … | … |
En el panel Propiedades de SQL Script 1 (Script SQL 1), cambie el Nombre a Count Products by Category (Contar productos por categoría). A continuación, en la barra de herramientas, seleccione Publicar para guardar el script.
Cierre el panel de scripts Count Products by Category (Contar productos por categoría).
En Synapse Studio, seleccione la página Desarrollar y observe que el script SQL publicado Count Products by Category (Contar productos por categoría) se ha guardado allí.
Seleccione el script SQL Count Products by Category (Contar productos por categoría) para volver a abrirlo. A continuación, asegúrese de que el script está conectado al grupo de SQL Integrado y ejecútelo para obtener el recuento de productos.
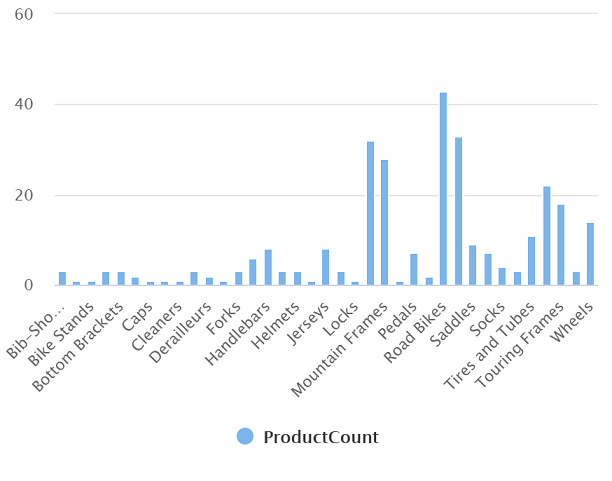
En el panel Resultados, seleccione la vista Gráfico y, a continuación, seleccione la siguiente configuración para el gráfico:
- Tipo de gráfico: columna
- Columna de categoría: categoría
- Columnas de leyenda (serie): ProductCount
- Posición de la leyenda: inferior central
- Etiqueta de leyenda (serie): dejar en blanco
- Valor mínimo de leyenda (serie): dejar en blanco
- Valor máximo de leyenda (serie): dejar en blanco
- Etiqueta de categoría: dejar en blanco
El gráfico resultante debe ser similar al siguiente:
Usar un grupo de Spark para analizar datos
Aunque SQL es un lenguaje común para consultar conjuntos de datos estructurados, muchos analistas de datos consideran que lenguajes como Python son útiles para explorar y preparar los datos para su análisis. En Azure Synapse Analytics, puede ejecutar código de Python (y otro) en un Grupo de Spark, que usa un motor de procesamiento de datos distribuido basado en Apache Spark.
En Synapse Studio, seleccione la página Administrar.
Seleccione la pestaña Grupos de Apache Spark y, a continuación, use el icono + Nuevo para crear un nuevo grupo de Spark con la siguiente configuración:
- Nombre del grupo de Apache Spark: spark
- Familia de tamaños de nodo: optimizada para memoria
- Tamaño del nodo: pequeño (4 núcleos virtuales/32 GB)
- Escalabilidad automática: habilitada
- Número de nodos: 3—-3
Revise y cree el grupo de Spark y espere a que se implemente (puede tardar unos minutos).
Cuando se haya implementado el grupo de Spark, en Synapse Studio, en la página Datos, vaya al sistema de archivos del área de trabajo de Synapse. A continuación, haga clic con el botón derecho en products.csv, seleccione Nuevo cuaderno y seleccione Cargar en DataFrame.
En el panel Notebook 1 (Cuaderno 1) que se abre, en la lista Adjuntar a, seleccione el grupo de Spark spark creado previamente y asegúrese de que la opción Lenguaje está establecida en PySpark (Python).
Revise solo el código de la primera celda del cuaderno, que debe tener este aspecto:
%%pyspark
df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv'
## If header exists uncomment line below
##, header=True
)
display(df.limit(10))Use el icono ▷ situado a la izquierda de la celda de código para ejecutarlo y espere a obtener los resultados. La primera vez que ejecuta una celda en un cuaderno, se inicia el grupo de Spark, por lo que puede tardar más o menos un minuto en devolver los resultados.
Nota
Si se produce un error porque el kernel de Python aún no está disponible, vuelva a ejecutar la celda
Finalmente, los resultados deben aparecer debajo de la celda y deben ser similares a estos:
| c0 | c1 | c2 | c3 |
|---|---|---|---|
| ProductID | ProductName | Category | ListPrice |
| 771 | Mountain-100 Silver, 38 | Bicicletas de montaña | 3399.9900 |
| 772 | Mountain-100 Silver, 42 | Bicicletas de montaña | 3399.9900 |
| … | … | … | … |
Quite la marca de comentario de la línea ,header=True (porque el archivo products.csv tiene los encabezados de columna en la primera línea), por lo que el código tiene el siguiente aspecto:
%%pyspark
df = spark.read.load('abfss://fsxx@datalakexx.dfs.core.windows.net/products.csv', format='csv'
## If header exists uncomment line below
, header=True
)
display(df.limit(10))Vuelva a ejecutar la celda y compruebe que los resultados son similares a los siguientes:
| ProductID | ProductName | Category | ListPrice |
|---|---|---|---|
| 771 | Mountain-100 Silver, 38 | Bicicletas de montaña | 3399.9900 |
| 772 | Mountain-100 Silver, 42 | Bicicletas de montaña | 3399.9900 |
| … | … | … | … |
Tenga en cuenta que volver a ejecutar la celda tarda menos tiempo, porque el grupo de Spark ya se ha iniciado.
En los resultados, use el icono +Código para agregar una nueva celda de código al cuaderno.
En la nueva celda de código vacía, agregue el código siguiente:
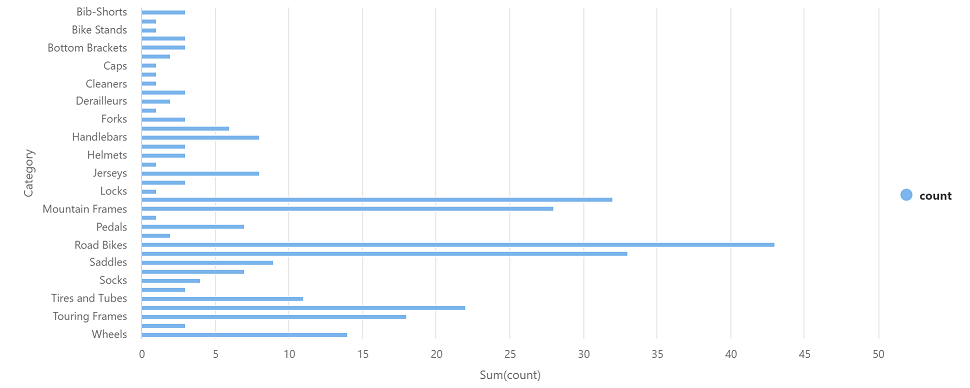
df_counts = df.groupby(df.Category).count()
display(df_counts)Ejecute la nueva celda de código haciendo clic en su icono ▷ y revise los resultados, que deben tener un aspecto similar al siguiente:
| Category | count |
|---|---|
| Tubos de dirección | 3 |
| Ruedas | 14 |
| … | … |
En la salida de resultados de la celda, seleccione la vista Gráfico. El gráfico resultante debe ser similar al siguiente:
Cierre el panel Notebook 1 (Cuaderno 1) y descarte los cambios.
Eliminación de recursos de Azure
Si ha terminado de explorar Azure Synapse Analytics, debe eliminar los recursos que ha creado para evitar costos innecesarios de Azure.
- Cierre la pestaña del explorador de Synapse Studio y vuelva a Azure Portal.
- En Azure Portal, en la página Inicio, seleccione Grupos de recursos.
- Seleccione el grupo de recursos del área de trabajo de Synapse Analytics (no el grupo de recursos administrado) y compruebe que contiene el área de trabajo de Synapse, la cuenta de almacenamiento y el grupo de Spark del área de trabajo.
- En la parte superior de la página Información general del grupo de recursos, seleccione Eliminar grupo de recursos.
- Escriba el nombre del grupo de recursos para confirmar que quiere eliminarlo y seleccione Eliminar.Después de unos minutos, se eliminarán el área de trabajo de Azure Synapse y el área de trabajo administrada asociada a ella.
MCT: Video 4.1.3 Descripción de Azure Synapse Analytics
¿Qué es Azure Synapse Analytic?
- Es un servicio que permite el almacenamiento de datos de análisis a gran escala
- Es una base de datos de procesamiento paralelo masivo
- La analítica empresarial debe funcionar a estala masiva con cualquier tipo de dato ya sea sin procesar, refinado o altamente curados
- Esto implica que las empresas combinen grandes datos y tecnologías de almacenamiento
- Este tipo de soluciones son difíciles de construir, mantener y asegurar
- Y esta complejidad retrasa la entrega de la información que requiere la empresa
- Azure Synapse Analytic es un servicio integrado que permite la obtención de la información de los almacenes de datos y en los sistemas de Big Data
- Reúne lo mejor de las tecnologías SQL utilizadas en los sistemas de almacenamientos empresariales
- Tecnologías Spark (para Big Data) / pipelines (para la integración de datos ) / ETL y ELT y una integración profunda con otros servicios como Power BI / MoseDB?? / Azure EndL??
Elementos clave y beneficios
- SQL tiene muchos servicios que ayudan a Azure Synapse Analytics
Synapse SQL
- Es un sistema de consultas distribuidas para T-SQL que permite escenarios de almacenamiento y virtualización de datos para abordar escenarios de transmisión y aprendizaje automático
- Ofrece modelos de recursos dedicados ofreciendo opciones de consumo y facturación que se adapten a las necesidades para obtener un rendimiento y costo predecibles se crean grupos SQL dedicados para reservar potencia de procesamiento para los datos almacenados en tablas SQL
- Se pueden utilizar las capacidades de transmisión , para transmitir datos de fuentes de datos en la nube a tablas SQL
- Se puede integrar inteligencia artificial con SQL, mediante el uso de modelos de aprendizaje automático para puntuar datos mediante la función de SQL Predict
Apache Spark
- Es el motor de Big Data de código abierto más popular utilizado para la preparación de datos, ingeniería de datos ETL y aprendizaje automático
- Existen modelos de aprendizaje automático con algoritmos Spark ML, integración con Azure ML, para Apache Spark 2.4 con compatibilidad integrada para Linux Fundation Data Lake
- Además contiene soporte integrado para .NET para Spark lo que permite utilizar la experiencia en C# y código .NET
- Hay dos forma dentro de Synapse para utilizar Spark
- Spark Notebooks: para hacer ciencia en ingeniería de datos usando Scala, pipeSpark, C#, SparKSQL
- Definición de trabajos Spark que utiliza lotes mediante archivos .jar

Interoperabilidad de SQL y Apache Spark en Data Lake
- Azure Synapse Analytics elimina las barreras tecnológicas tradicionales entre el uso conjunto de SQL y Spark
- Puede mezclar y combinar sin problemas según las necesidades y experiencias
- Sistema de metadatos que permite que las tablas definidas en un archivo de Data Lake sen consumidas sin problemas por Spark
- SQL y Spark pueden explorar y analizar directamente archivos Parked??? CVS, JSON y almacenamientos de Data Lake
- Carga y descarga rápida
- Escalable para datos que se trasladan entre bases de datos SQL y Spark
¿Qué son los pipelines?
- Son la forma como Azure Synapse proporciona integración de datos lo que le permite mover datos entre servicios y ordenar actividades
- Son agrupaciones lógicas de actividades que realizan una tarea en conjunto
- Se agrupan en 4 actividades lógicas
- Actividades: define acciones dentro de una canalización como copiar datos, ejecutar un cuaderno o script SQL
- Data Flow (Flujos): Proporciona una experiencia sin código para realizar la transformación de datos que utiliza Synapse-Spark
- Trigger: Ejecuta una canalización que se puede ejecutar de forma manual o automática
- Conjunto de datos de Integración: hacer referencia a los datos que se utilizan en una actividad como entrada y salida, pertenece a un servicio vinculado
Gestión, supervisión y Seguridad unificadas
- Azure Synapse proporciona una forma única para que las empresas administren los recursos de análisis, supervisen el uso, la actividad y apliquen la seguridad
- Para esto se le asignan usuarios a roles para simplificar el acceso a los recursos de análisis y también un control de acceso detallado sobre los datos y código
- Y un solo panel para monitorizar los recursos, el uso y los usuarios de SQL y Spark
Synapse Studio
- Es una interfaz Web que crea una solución de análisis de un extremo a otro en un solo lugar
- Con ayuda de la ingesta, exploración, preparación, organización y visualización
- ofrece productividad para ingenieros de datos que escriben código en SQL o Spark con ayuda de la creación, depuración y optimización del rendimiento
- Integración con los procesos de CI/CD empresariales

MCT: Video 4.1.4 Carga de datos en Azure Synapse Analytics
¿Qué hace Azure Synapse Analytics?
- Es un servicio que permite el almacenamiento datos y análisis a gran escala
- Aquí se mostrar como puede usarse Azure data Factory para ingeriri datos de Azure Synapse Analytics
- tenemos un archivo housesproces.cvs separados por coma
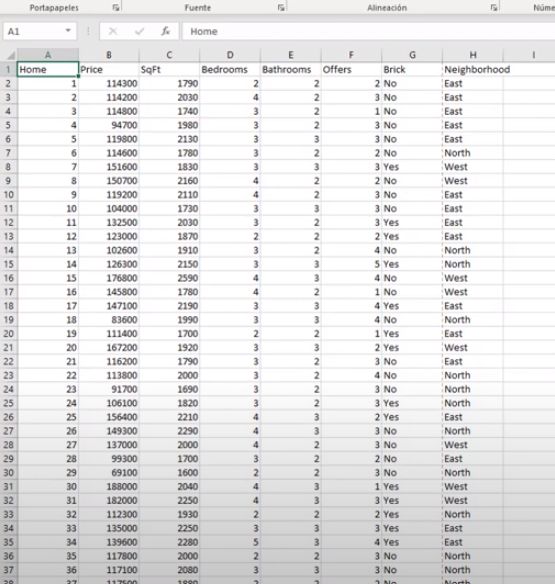
Paso 1: Crear cuenta de almacenamiento
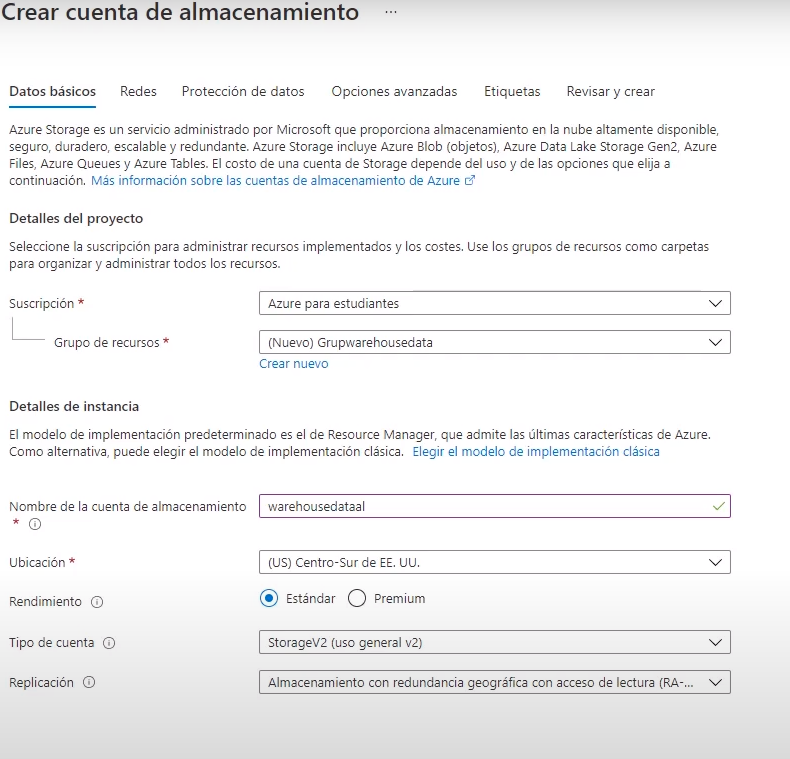
- El primer paso para cargar datos en Azure synapse Analytics es crear la cuenta de almacenamiento
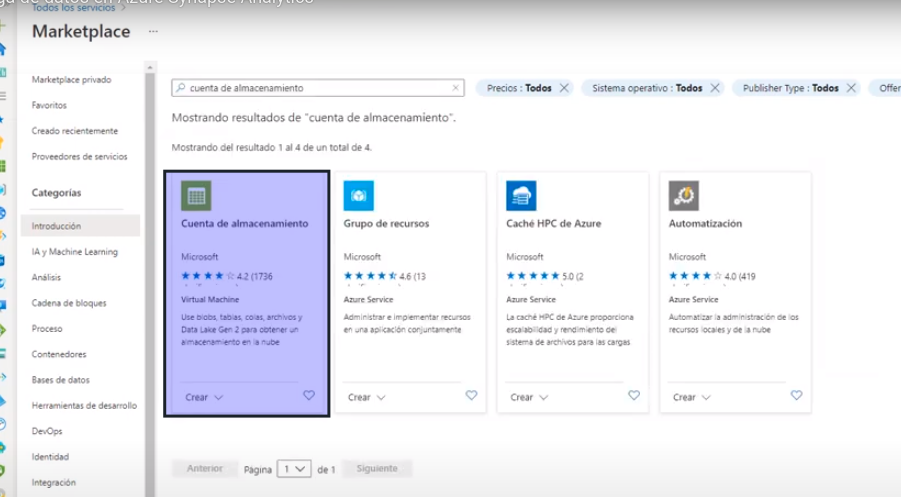
- Mas Recursos->Makert Place -> Cuenta de Alamcenamiento
- Agregamos los datos
- Creamos el servicio
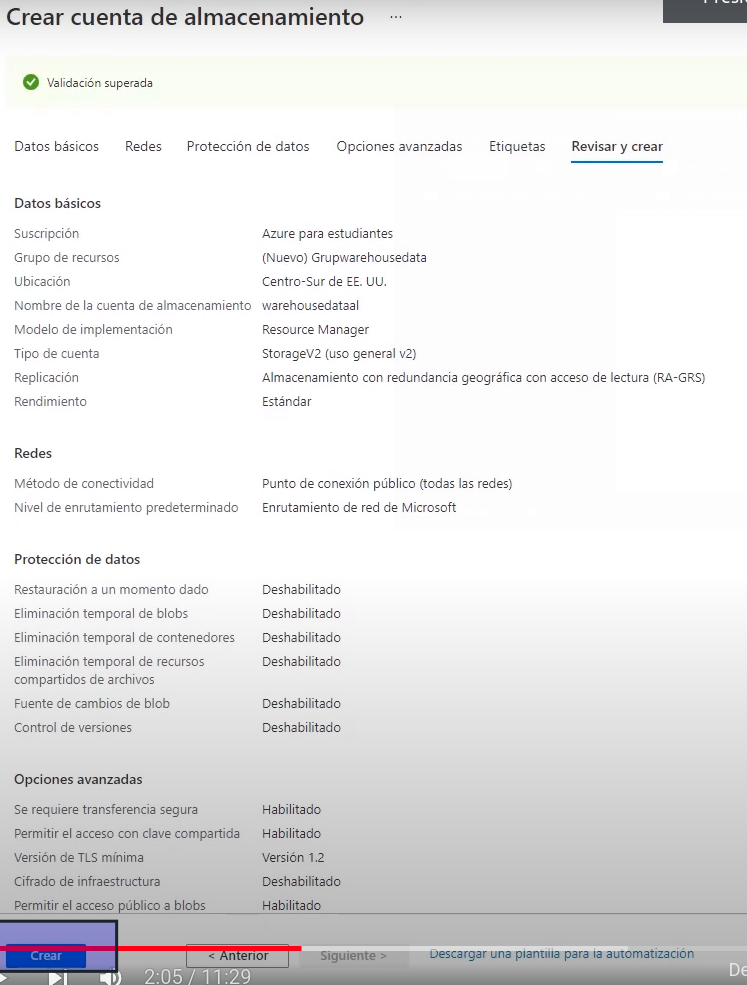
- Ingresamos al servicio -> Servicio Archivo -> Recursos compartidos de archivos->Agregar Recursos compartido de archivos
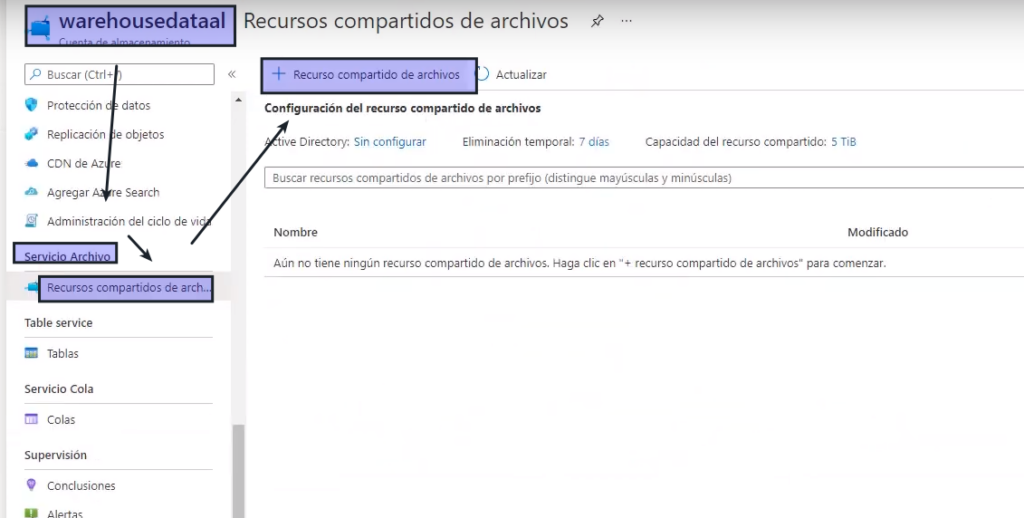
- Le asignamos un nombre – > Crear
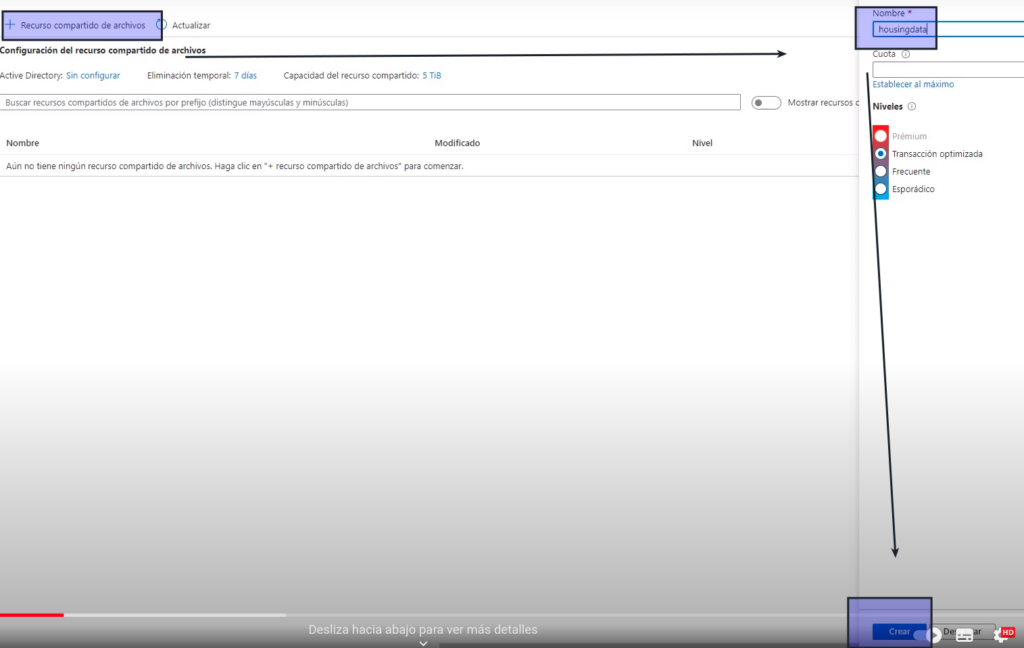
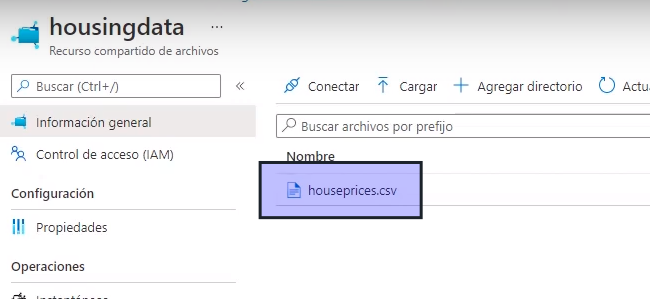
- vamos al recurso que se acaba de crear
- Le damos cargar -> Buscamos el archivo -> Cargar

- Se añade el archivo
Paso 2: Crear el servicio de almacenamiento de datos
- MarketPlace -> Azure Synapse Analytics

- Completamos los datos
- Siguiente
- Creamos un usuario y contraseña
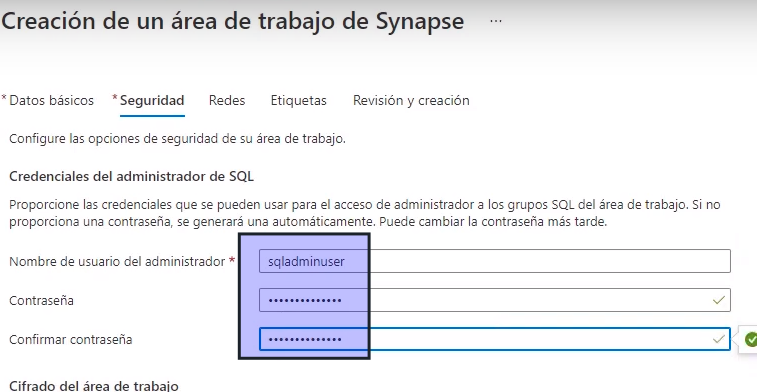
- Validamos y le damos Crear
Paso 3: Crear grupo de SQL para almacenar
- Dentro del recursos ingresamos a el «área de trabajo synapse»
- Vamos a «Nuevo grupo de SQL dedicado»
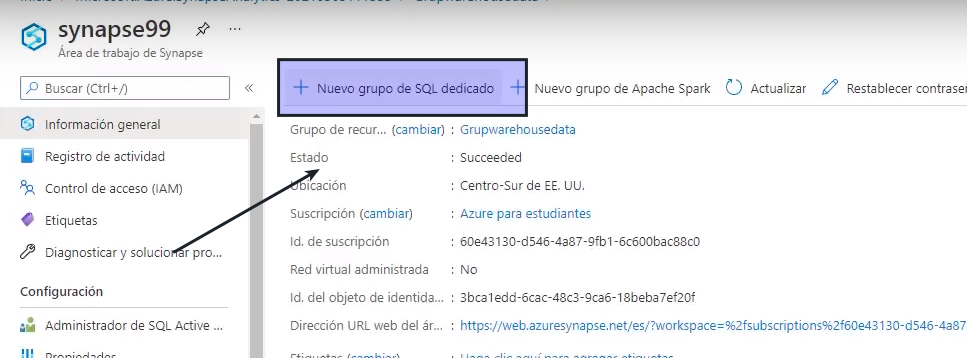
- Colocamos un nombre para el nombre de grupo de SQL dedicado y en nivel de rendimiento el más bajo
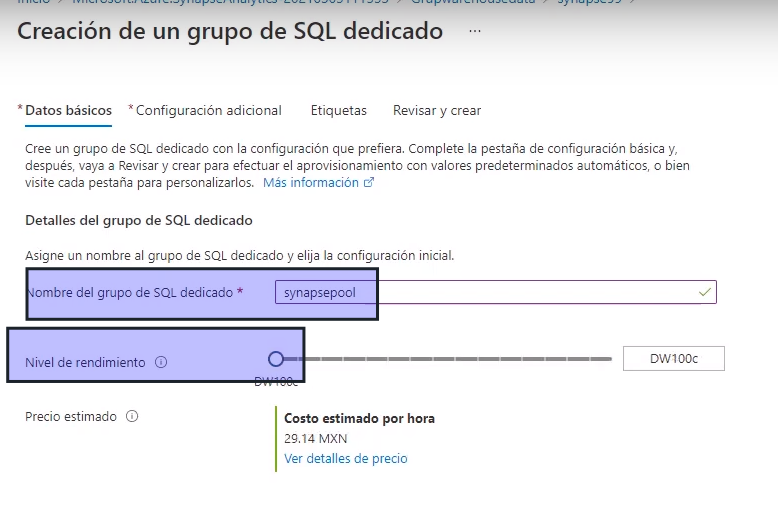
- Creamos el recurso
Paso 4: Crear instancia de Data Factory
- MarketPlace -> Data Factory
- Completamos los datos
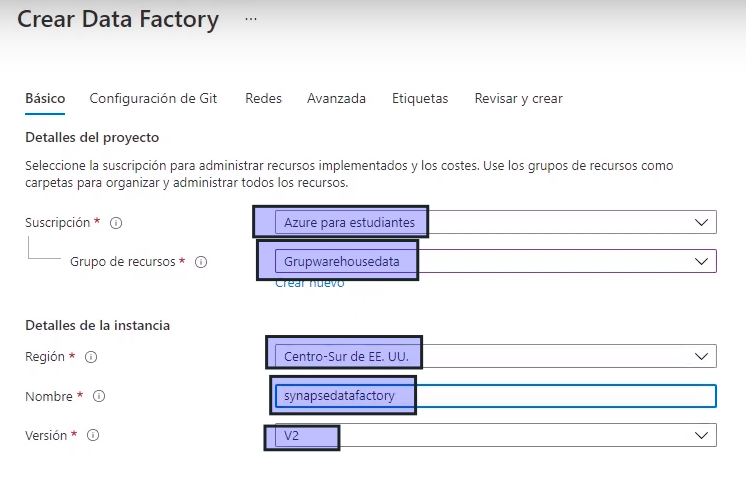
- Configuración Git -> Más tarde

- Revisar y Crear
Paso 5: Crear tabla en Synapse Analytics
- Creamos una tabla para almacenar la información
- Ingresamos al área de trabajo de synapse
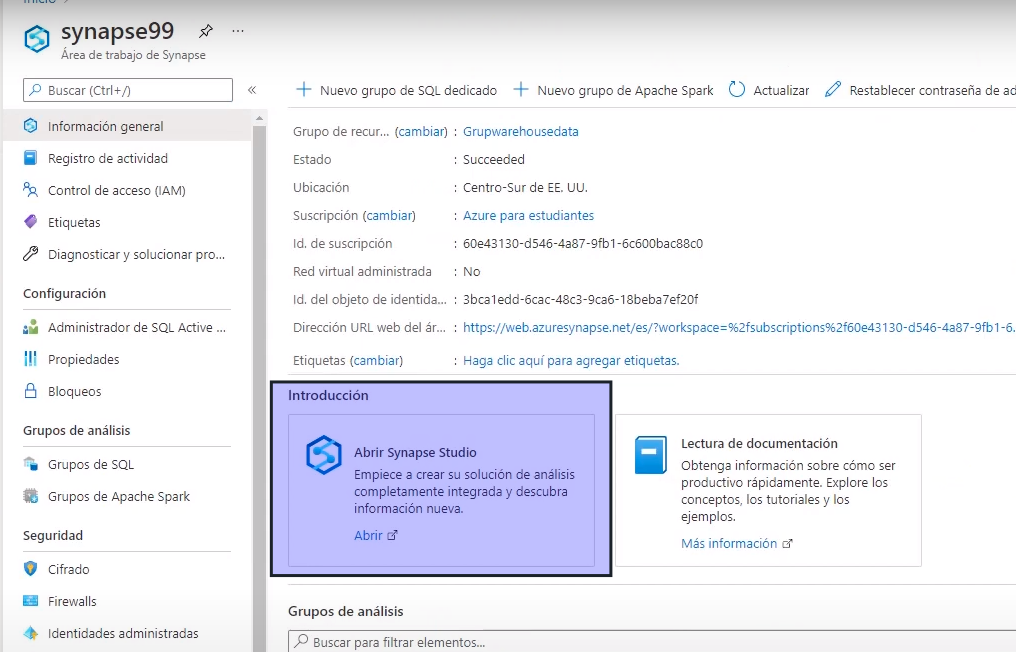
- Ingresamos a Synapse Studio
- Ingresamos a datos

- Bases de datos -> Tablas->Acciones
- Nuevo script -> Nueva Tabla
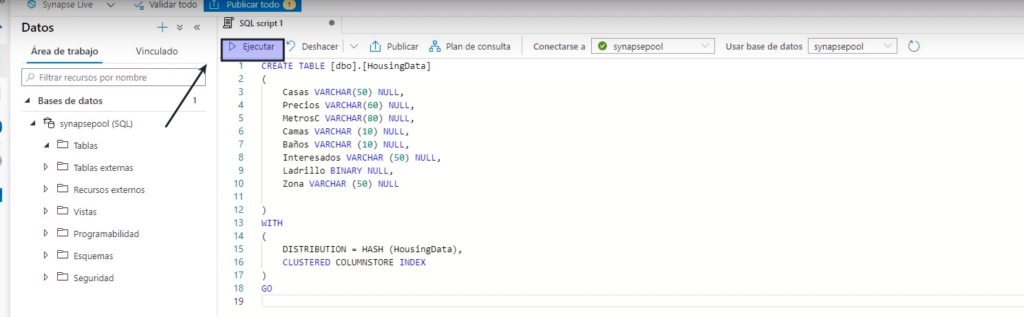
- Creamos un script que cree la tabla
- Y luego le damos publicar la tabla se publica para que sea accedida por Data Factory
Paso 6: data Factory
- Ingresamos al servicio de data factory
Le damos clic en crear y supervisar
- Podríamos crear una canalización pero data Factory tiene un asistente que lo hace automáticamente
- Seleccionamos «Copiar datos»
- Primero es determinar el nombre de la tarea
- En la conexión de origen -> Crear nueva conexión

- Esto crea un servicio vinculado
- Buscamos el servicio Azure File Storage
- Continuar
- Aquí solo buscamos el nombre de la cuenta de almacenamiento y el archivo que hemos creado
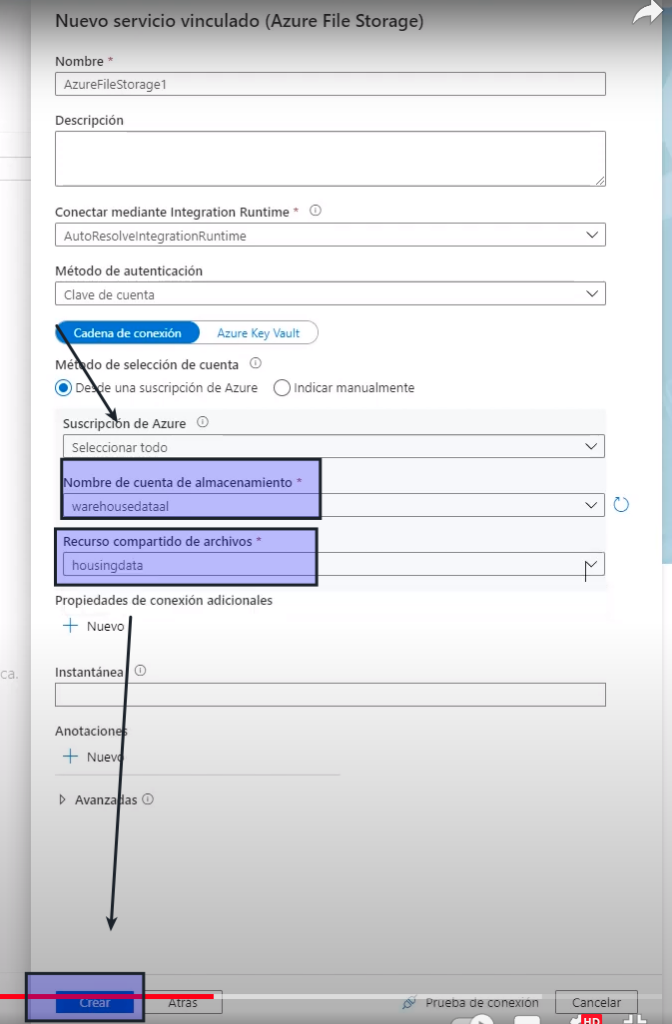
- Como origen seleccionamos el archivo
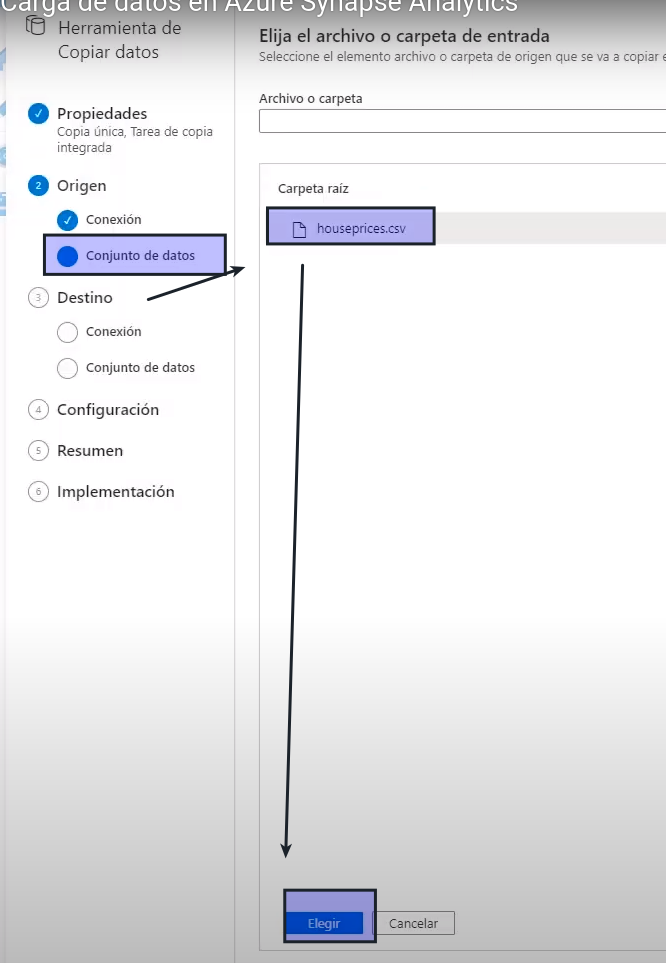
- Nos carga un avista previa
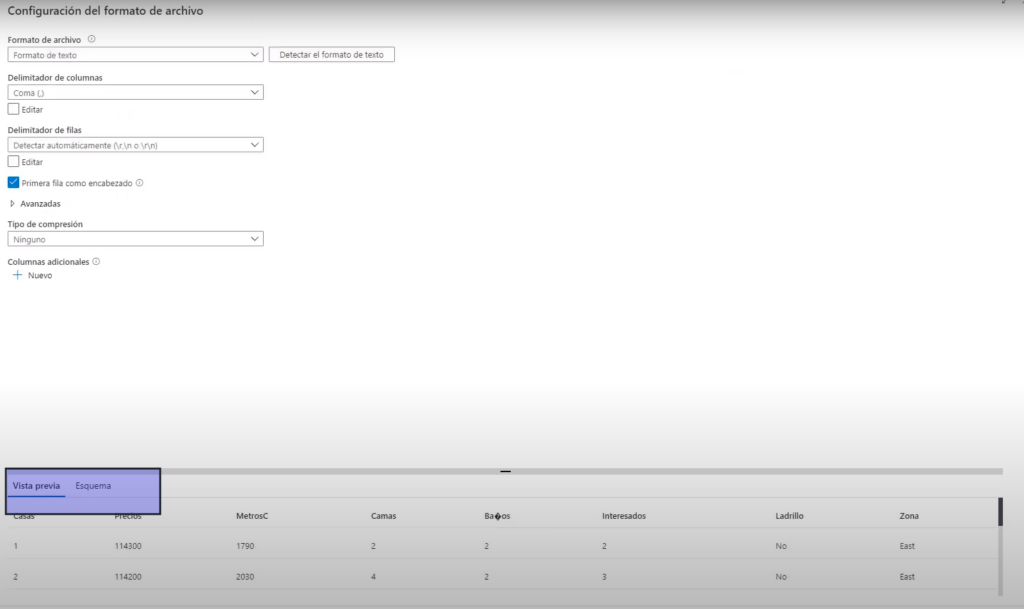
- Siguiente
- Ahora vamos a crear un servicio vinculado que se conecte con al áea de trabajo de synapse

- Buscamos synapse
- Seleccionamos el área de trabajo synapse que creamos
- La base de datos
- Y el método de conexión configurado / usuarios / conatraseña
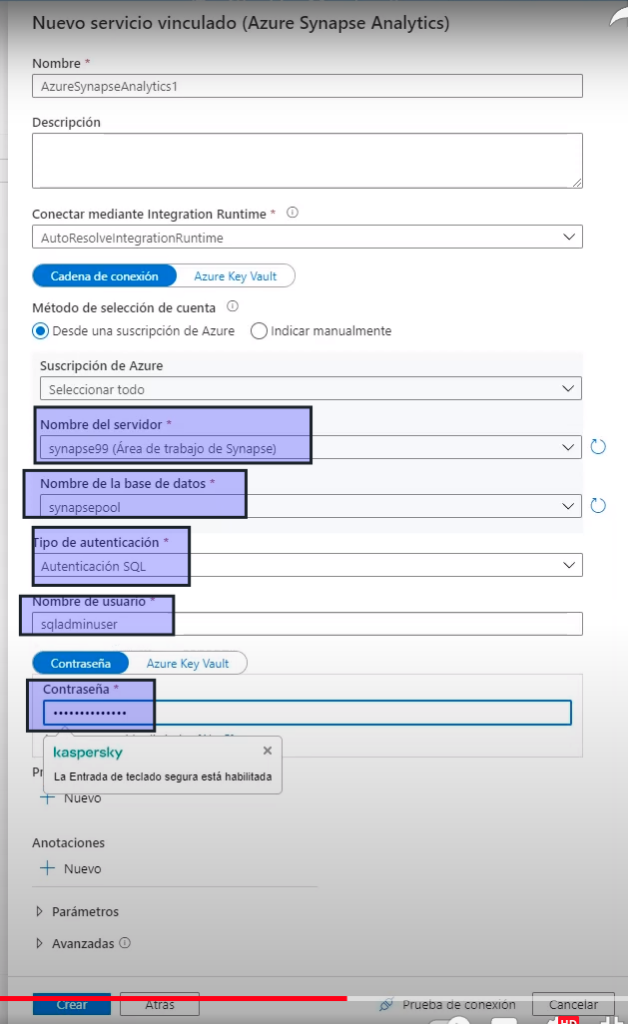
- Crear
- Siguiente
- Ahora vamos a pasar los datos del archivo a al base de datos de synapse
- Primero pide la tabla

- Siguiente
- Aquí debe definir como se asignarán los campos del archivo cvs a la tablas (usa inteligencia artificial para determinar los nombre de las columnas con los nombres dela BD y tipos de datos)
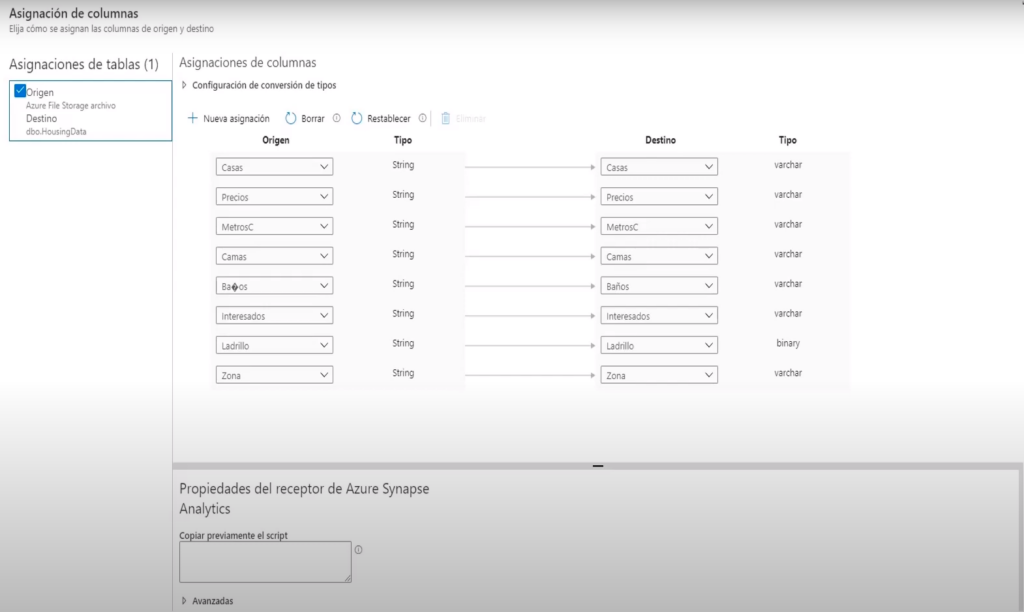
- Siguiente
- En este caso vamos a utilizar Inserción masiva
- Y vamos a cargar los datos directamente por lo que deshabilitamos «Habilitar almacenamiento provisional»
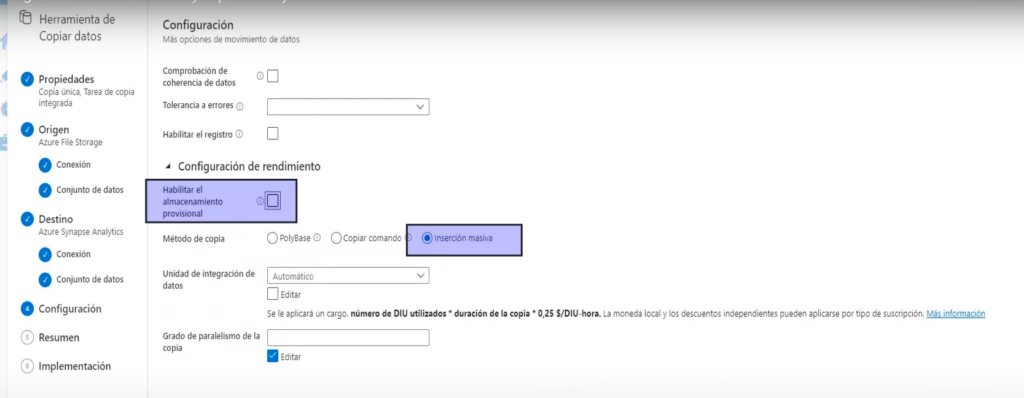
- Siguiente
- Validamos la tarea
- Verificamos
Paso 6: regresamos a Synapse para ver los datos
- Actualizamos
- Obtenemos la primeras 100 lineas