https://docs.microsoft.com/es-mx/learn/modules/explore-fundamentals-stream-processing/
Unidad 1: Introducción
Un mayor uso de la tecnología por parte de personas, empresas y otras organizaciones, junto con la proliferación de dispositivos inteligentes y acceso a Internet, ha generado un crecimiento masivo del volumen de datos que se pueden generar, capturar y analizar. Gran parte de estos datos se pueden procesar en tiempo real (o al menos, casi en tiempo real) como un flujo perpetuo de datos, lo que permite la creación de sistemas que revelan conclusiones y tendencias instantáneas, o toman medidas inmediatas de respuesta a los eventos a medida que se producen.
Unidad 2: Comprensión del procesamiento de flujos y por lotes
El procesamiento de datos es simplemente la conversión de datos sin procesar en información significativa a través de un proceso. Existen dos métodos generales para procesar los datos:
- Procesamiento por lotes, en el que se recopilan y almacenan varios registros de datos antes de procesarse juntos en una sola operación.
- Procesamiento de flujos, en el que un origen de datos se supervisa y procesa constantemente en tiempo real a medida que se producen nuevos eventos de datos.
Procesamiento por lotes
En el procesamiento por lotes, los elementos de datos recién llegados se recopilan y se almacenan y todo el grupo se procesa de forma conjunta, como un lote. El momento en el que se procesa cada grupo se puede determinar de varias maneras. Por ejemplo, los datos se pueden procesar según un intervalo de tiempo programado (por ejemplo, cada hora), o bien el procesamiento puede desencadenarse cuando se alcance una determinada cantidad de datos o como resultado de algún otro evento.
Por ejemplo, supongamos que quiere analizar el tráfico de carreteras contando el número de automóviles en un tramo de carretera. Un enfoque de procesamiento por lotes requeriría recopilar los automóviles de un aparcamiento y, a continuación, contarlos en una sola operación mientras están en reposo.
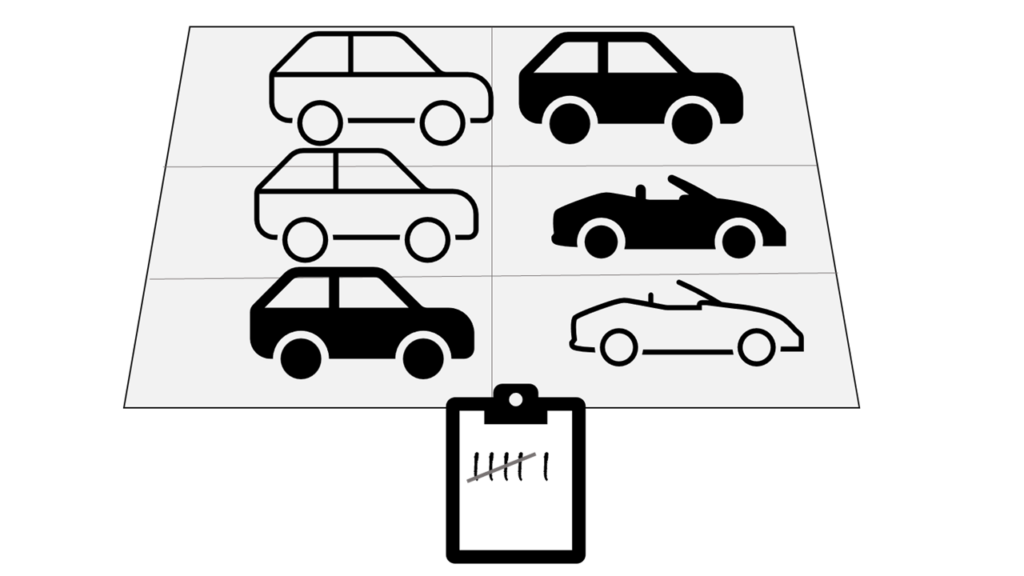
Si la carretera está ocupada, con un gran número de automóviles que conducen a intervalos frecuentes, este enfoque puede ser poco práctico. Tenga en cuenta que no obtiene ningún resultado hasta que haya estacionado un lote de automóviles y los haya contado.
Un ejemplo real de procesamiento por lotes es la forma en que las empresas de tarjetas de crédito controlan la facturación. El cliente no recibe una factura por cada compra que hace con su tarjeta de crédito, sino una factura mensual para todas las compras de ese mes.
Entre las ventajas del procesamiento por lotes se incluyen las siguientes:
- Se pueden procesar grandes volúmenes de datos en un momento especificado.
- Se puede programar para ejecutarse mientras los equipos o sistemas están inactivos, como por la noche o en horas de poca actividad.
Entre las desventajas del procesamiento por lotes están las siguientes:
- El tiempo de retardo entre la ingesta de los datos y la obtención de los resultados.
- Todos los datos de entrada de un trabajo por lotes deben estar listos para poder procesar un lote. Esto significa que los datos deben comprobarse con cuidado. Los problemas con los datos, los errores y los bloqueos de los programas que se producen durante los trabajos por lotes provocan la detención de todo el proceso. Los datos de entrada deben comprobarse cuidadosamente antes de volver a ejecutar el trabajo. Incluso los errores de datos menores pueden impedir la ejecución de un trabajo por lotes.
Información sobre el procesamiento de flujos
En el procesamiento en streaming, cada nuevo fragmento de datos se procesa cuando llega. A diferencia del procesamiento por lotes, no hay ningún tiempo de espera hasta el siguiente intervalo de procesamiento por lotes y los datos se procesan como unidades individuales en tiempo real en lugar de procesarse de lote en lote. El procesamiento de datos de flujos es beneficioso en los escenarios donde se generan datos dinámicos nuevos de forma continua.
Por ejemplo, un enfoque mejor para nuestro hipotético problema de recuento de automóviles podría ser aplicar un enfoque de flujo de datos, contando los automóviles en tiempo real a medida que pasan:
En este enfoque, no es necesario esperar hasta que todos los automóviles hayan estacionado para comenzar a procesarlos, y puede sumar los datos a lo largo de intervalos de tiempo. Por ejemplo, contando el número de automóviles que pasan cada minuto.
Entre los ejemplos reales de datos de flujos se incluyen:
- Una institución financiera realiza un seguimiento de los cambios en el mercado de valores en tiempo real, calcula el valor en riesgo y reequilibra automáticamente las carteras en función de los movimientos de precio de las acciones.
- Una empresa de juegos en línea recopila datos en tiempo real sobre las interacciones de los jugadores con los juegos y los incorpora en su plataforma de juegos. Después, analiza los datos en tiempo real y ofrece incentivos y experiencias dinámicas para atraer a los jugadores.
- Un sitio web inmobiliario hace un seguimiento de un subconjunto de datos de dispositivos móviles y ofrece recomendaciones en tiempo real de las propiedades que pueden visitar los clientes en función de su ubicación geográfica.
El procesamiento en streaming es idóneo para las operaciones en las que la velocidad de ejecución es importante y que requieren una respuesta instantánea en tiempo real. Por ejemplo, un sistema que supervisa la presencia de humo y altas temperaturas en un edificio necesita activar alarmas y desbloquear puertas para permitir que los residentes puedan salir inmediatamente en caso de que se produzca un incendio.
Diferencias entre los datos de streaming y por lotes
Además de las diferencias en la forma en que el procesamiento por lotes y en streaming controlan los datos, hay otras diferencias:
- Ámbito de los datos: el procesamiento por lotes puede procesar todos los datos del conjunto de datos. Normalmente, el procesamiento en streaming solo tiene acceso a los datos recibidos más recientemente recibidos o dentro de un período de tiempo cambiante (los últimos 30 segundos, por ejemplo).
- Tamaño de los datos: el procesamiento por lotes es adecuado para administrar grandes conjuntos de datos de forma eficaz. El procesamiento en streaming está diseñado para registros individuales o microlotes que constan de pocos registros.
- Rendimiento: la latencia es el tiempo que se tarda en recibir y procesar los datos. la latencia del procesamiento por lotes suele ser de unas horas. Normalmente, el procesamiento en streaming se produce inmediatamente, con la latencia en segundos o milisegundos.
- Análisis: normalmente se usa el procesamiento por lotes para realizar análisis complejos. El procesamiento en streaming se usa para funciones de respuesta simples, agregaciones o cálculos, como el cálculo de la media acumulada.
Combinación del procesamiento por lotes y por flujos
Muchas soluciones de análisis a gran escala incluyen una combinación de procesamiento por lotes y de flujos, lo que permite el análisis de datos históricos y en tiempo real. Es habitual que las soluciones de procesamiento de flujos capturen datos en tiempo real, los filtren o agreguen para procesarlos y los presenten a través de paneles y visualizaciones en tiempo real (por ejemplo, muestran el total de automóviles que han pasado por una carretera durante la hora actual), al tiempo que también se conservan los resultados procesados en un almacén de datos para el análisis histórico junto con los datos procesados por lotes (por ejemplo, para habilitar el análisis de los volúmenes de tráfico durante el último año).
Incluso cuando no se requiere el análisis o la visualización en tiempo real de los datos, las tecnologías de flujos a menudo se usan para capturar datos en tiempo real y almacenarlos en un almacén de datos para su posterior procesamiento por lotes (esto equivale a redirigir todos los automóviles que viajan por una carretera a un aparcamiento antes de contarlos).
En el diagrama siguiente se muestran algunos métodos para combinar el procesamiento por lotes y de flujos en una arquitectura de análisis de datos a gran escala.
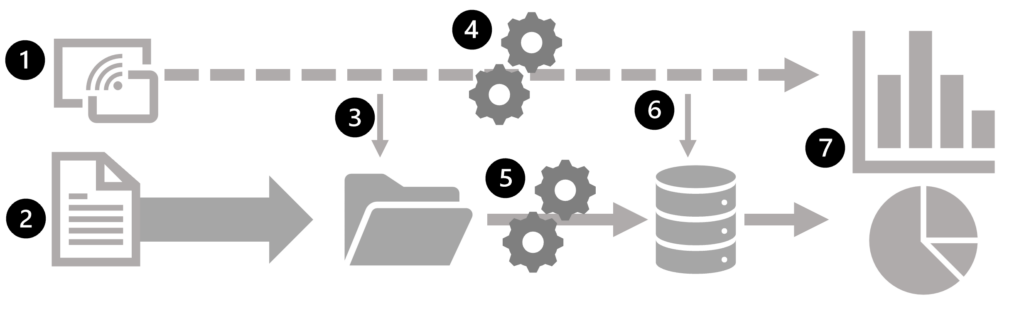
- Los eventos de datos de un origen de datos de flujos se capturan en tiempo real.
- Los datos de otros orígenes se ingieren en un almacén de datos (a menudo, un lago de datos) para el procesamiento por lotes.
- Si no es necesario llevar a cabo análisis en tiempo real, los datos de flujos capturados se escriben en el almacén de datos para su posterior procesamiento por lotes.
- Cuando se requiere un análisis en tiempo real, se usa una tecnología de procesamiento de flujos para preparar los datos de flujos para el análisis o visualización en tiempo real. A menudo, se filtran o suman los datos por periodos de tiempo.
- Los datos que no son de flujos se procesan por lotes periódicamente para prepararlos para el análisis y los resultados se conservan en un almacén de datos analíticos (a menudo denominado almacén de datos) para el análisis histórico.
- Los resultados del procesamiento de flujos también se pueden conservar en el almacén de datos analíticos para admitir el análisis histórico.
- Las herramientas analíticas y de visualización se usan para presentar y explorar los datos históricos y en tiempo real.
Nota
Entre las arquitecturas de soluciones usadas con más frecuencia para un procesamiento de datos de flujos y por lotes de manera combinada, se encuentran arquitecturaslambda y delta. Los detalles de estas arquitecturas están fuera del ámbito de este curso, pero incorporan tecnologías tanto para el procesamiento de datos por lotes a gran escala como el procesamiento de flujos en tiempo real para crear una solución analítica de un extremo a otro.
Unidad 3: Exploración de elementos comunes de la arquitectura de procesamiento de flujos
Existen muchas tecnologías que puede usar para implementar una solución de procesamiento de flujos, pero, aunque los detalles de implementación específicos pueden variar, existen elementos comunes para la mayoría de las arquitecturas de flujos.
Una arquitectura general para el procesamiento de flujos
En su forma más simple, una arquitectura de alto nivel para el procesamiento de flujos tiene el siguiente aspecto:
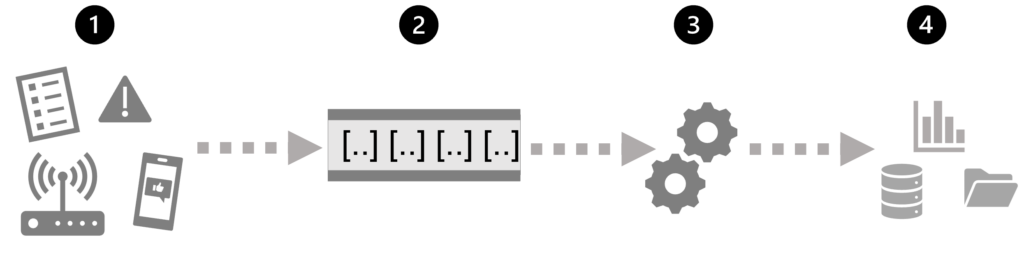
- Un evento genera algunos datos. Podría ser una señal que emite un sensor, un mensaje de redes sociales que se publica, una entrada de archivo de registro que se escribe o cualquier otro evento que da como resultado algunos datos digitales.
- Los datos generados se capturan en un origen de streaming para su procesamiento. En casos simples, el origen puede ser una carpeta de un almacén de datos en la nube o una tabla de una base de datos. En soluciones de flujos más sólidas, el origen puede ser una «cola» que encapsula la lógica para asegurarse de que los datos del evento se procesan en orden y que cada evento se procesa una sola vez.
- Los datos del evento se procesan, a menudo mediante una consulta perpetua que opera en los datos del evento para seleccionar datos para tipos específicos de eventos, valores de datos de proyectos o valores de datos sumados durante periodos de tiempo (basados en tiempo real, o plazos de tiempo), por ejemplo, mediante el recuento del número de emisiones de sensores por minuto.
- Los resultados de la operación de procesamiento de flujos se escriben en una salida (o receptor), que puede ser un archivo, una tabla de base de datos, un panel visual en tiempo real u otra cola para su posterior procesamiento mediante una consulta de bajada posterior.
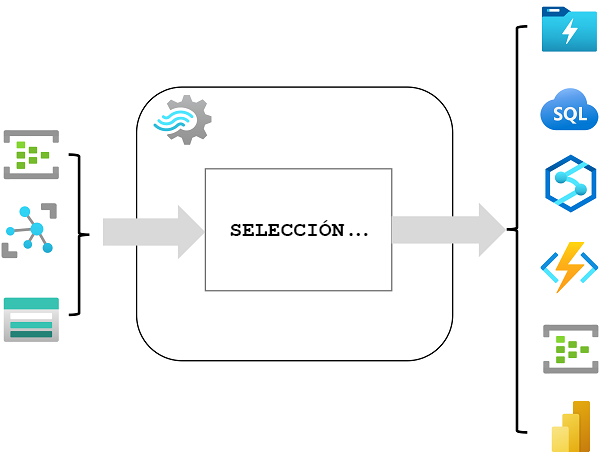
Análisis en tiempo real en Azure
Microsoft Azure es compatible con numerosas tecnologías que puede usar para implementar el análisis en tiempo real de los datos de streaming, entre las que se incluyen:
- Azure Stream Analytics: solución de plataforma como servicio (PaaS) que puede usar para definir trabajos de flujos que ingieren datos de un origen de flujos, aplican una consulta perpetua y escriben los resultados en una salida.
- Spark Structured Streaming: biblioteca de código abierto que le permite desarrollar soluciones de flujos complejos en servicios basados en Apache Spark, como Azure Synapse Analytics, Azure Databricks, y Azure HDInsight.
- Azure Data Explorer: un servicio de análisis y bases de datos de alto rendimiento, optimizado para la ingesta y consulta de datos por lotes o en streaming con un elemento de serie temporal y que se puede usar como servicio de Azure independiente o como entorno de ejecución de Azure Synapse Data Explorer en un área de trabajo de Azure Synapse Analytics.
Orígenes para el procesamiento de flujos
Los siguientes servicios se usan normalmente para ingerir datos para el procesamiento de flujos en Azure:
- Azure Event Hubs: servicio de ingesta de datos que puede usar para administrar colas de datos de eventos, lo que garantiza que cada evento se procese en orden, exactamente una vez.
- Azure IoT Hub: servicio de ingesta de datos similar a Azure Event Hubs, pero optimizado para administrar datos de eventos de dispositivos de Internet de las cosas (IoT).
- Azure Data Lake Store Gen 2: servicio de almacenamiento altamente escalable que se usa a menudo en escenarios de procesamiento por lotes, pero que también se puede usar como origen de datos de flujos.
- Apache Kafka: solución de ingesta de datos de código abierto que se usa a menudo junto con Apache Spark. Puede usar Azure HDInsight para crear un clúster de Kafka.
Receptores para el procesamiento de flujos
La salida del procesamiento de flujos a menudo se envía a los siguientes servicios:
- Azure Event Hubs: se usa para poner en cola los datos procesados para su posterior procesamiento de bajada.
- Azure Data Lake Store Gen 2 o Azure Blob Storage: se usan para conservar los resultados procesados como un archivo.
- Azure SQL Database, Azure Synapse Analytics o Azure Databricks: se usan para conservar los resultados procesados en una tabla de base de datos para consultas y análisis.
- Microsoft Power BI: se usa para generar visualizaciones de datos en tiempo real en informes y paneles.
Unidad 4: Exploración de Azure Stream Analytics
Azure Stream Analytics es un servicio para el procesamiento de eventos complejos y el análisis de datos de flujos. Stream Analytics se usa para:
- Ingerir datos de una entrada, como Azure Event Hubs, Azure IoT Hub o un contenedor de blobs de Azure Storage.
- Procesar los datos con una consulta para seleccionar, proyectar y sumar valores de datos.
- Escribir los resultados en una salida, como Azure Data Lake Gen 2, Azure SQL Database, Azure Synapse Analytics, Azure Functions, Azure Event Hubs, Microsoft Power BI u otros.
Una vez iniciada, se ejecutará una consulta de Stream Analytics de forma perpetua para procesar nuevos datos a medida que llegan a la entrada y almacenar los resultados en la salida.
Azure Stream Analytics es una opción tecnológica excelente cuando necesita capturar continuamente datos de un origen de streaming, filtrar o agregar esos datos y enviar los resultados a un almacén de datos o proceso de bajada para su análisis e informes.
Trabajos y clústeres de Azure Stream Analytics
La manera más fácil de usar Azure Stream Analytics es crear un trabajo de Stream Analytics en una suscripción de Azure, configurar sus entradas y salidas, y definir la consulta que usará el trabajo para procesar los datos. La consulta se expresa mediante la sintaxis del lenguaje de consulta estructurado (SQL) y puede incorporar datos de referencia estáticos de varios orígenes de datos para proporcionar valores de búsqueda que se pueden combinar con los datos de flujos ingeridos desde una entrada.
Si los requisitos del proceso de flujos son complejos o consumen muchos recursos, puede crear un clúster de Stream Analysis, que usa el mismo motor de procesamiento subyacente que un trabajo de Stream Analytics, pero en un inquilino dedicado (por lo que el procesamiento no se ve afectado por otros clientes) y con escalabilidad configurable que le permite definir el equilibrio adecuado entre rendimiento y costo para su escenario específico.
Nota
Para obtener más información sobre las funciones de Azure Stream Analytics, consulte la documentación de Azure Stream Analytics.
Unidad 5: Ejercicio: análisis de datos de flujos
Creación de recursos de Azure (no sirvió con learn se hace con cuenta student)
En Azure Cloud Shell, escriba el siguiente comando para descargar los archivos que necesitará para este ejercicio.
git clone https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals dp-900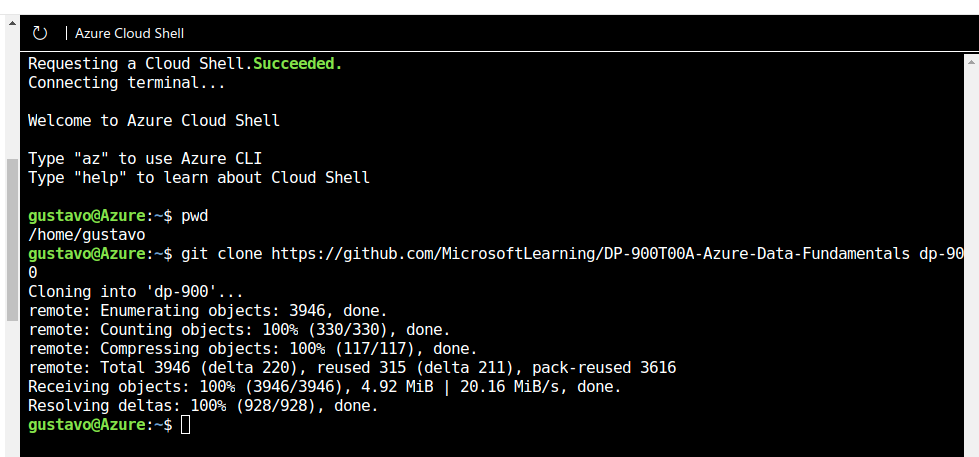
Espere a que se complete el comando y escriba el siguiente comando para cambiar el directorio actual a la carpeta que contiene los archivos de este ejercicio.
cd dp-900/streaming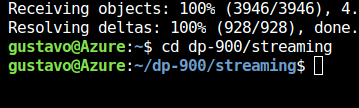
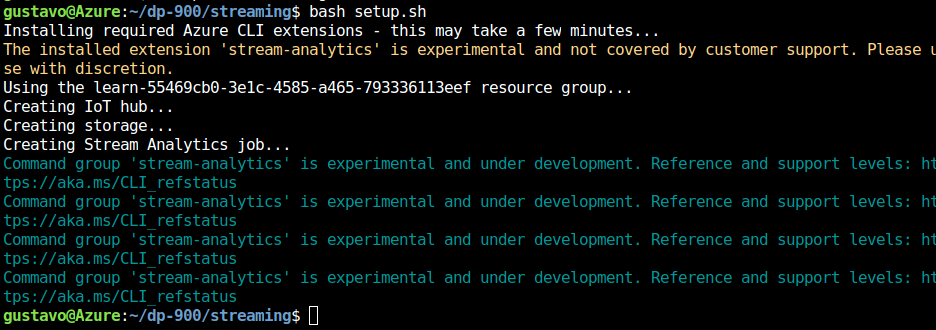
Escriba el siguiente comando para ejecutar un script que cree los recursos de Azure que necesitará en este ejercicio.
bash setup.shEspere mientras se ejecuta el script y este lleva a cabo las siguientes acciones:
- Instalar las extensiones de la CLI de Azure necesarias para crear recursos (puede omitir las advertencias sobre las extensiones experimentales)
- Identifica el grupo de recursos de Azure proporcionado para este ejercicio, que tendrá un nombre similar a learn-xxxxxxxxxxxxxxxxx….
- Crear un recurso de Azure IoT Hub, que se usará para recibir un flujo de datos de un dispositivo simulado.
- Crear una cuenta de Azure Storage, que se usará para almacenar datos procesados.
- Crear un trabajo de Azure Stream Analytics, que procesará los datos del dispositivo entrantes en tiempo real y escribir los resultados en la cuenta de almacenamiento.
Exploración de los recursos de Azure
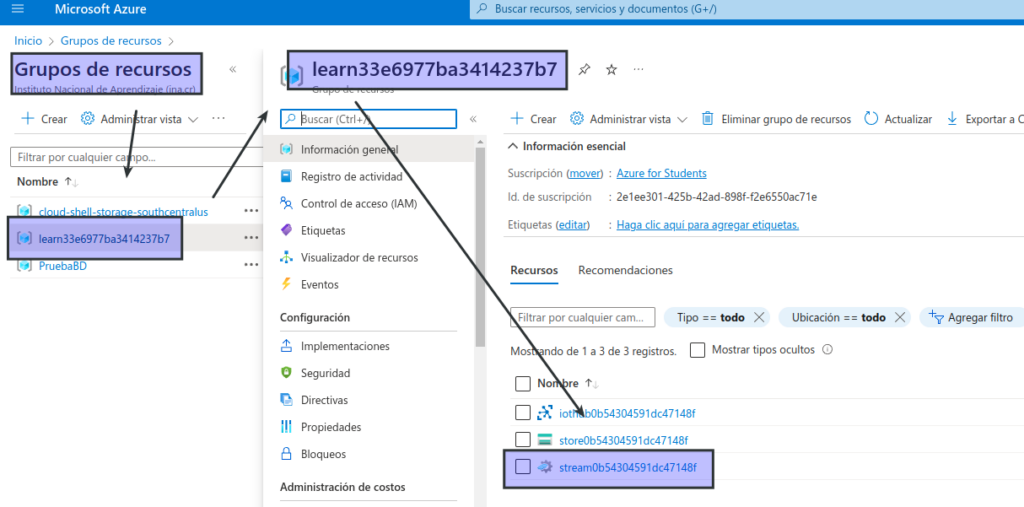
En la página principal de Azure Portal, seleccione Grupos de recursos para ver los grupos de recursos de la suscripción. Debería incluir el grupo de recursos learn-xxxxxxxxxxxxxxxxx… identificado por el script de configuración.
- En la página principal de Azure Portal, seleccione Grupos de recursos para ver los grupos de recursos de la suscripción. Debería incluir el grupo de recursos learn-xxxxxxxxxxxxxxxxx… identificado por el script de configuración.
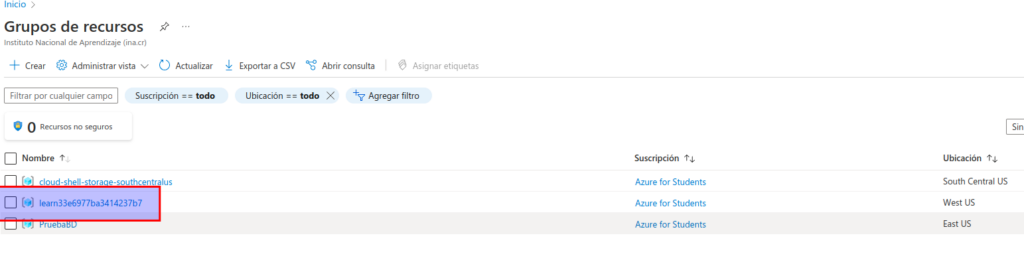
- Seleccione el grupo de recursos learn-xxxxxxxxxxxxxxxxx… y revise los recursos que contiene, que deberían incluir los siguientes:
- Una instancia de IoT Hub llamada iothubxxxxxxxxxxxxx, que se usa para recibir datos entrantes del dispositivo.
- Una cuenta de almacenamiento llamada storexxxxxxxxxxxx, en la que se escribirán los resultados del procesamiento de datos.
- Un trabajo de Stream Analytics llamado streamxxxxxxxxxxxxx, que se usará para procesar datos streaming.Si no se muestran los tres recursos, haga clic en el botón ↻ Actualizar hasta que aparezcan.
Nota
Si usa el espacio aislado de Learn, el grupo de recursos también puede contener una segunda cuenta de almacenamiento llamada cloudshellxxxxxxxx, que se usará a fin de almacenar datos para la instancia de Azure Cloud Shell que ha usado para ejecutar el script de configuración.
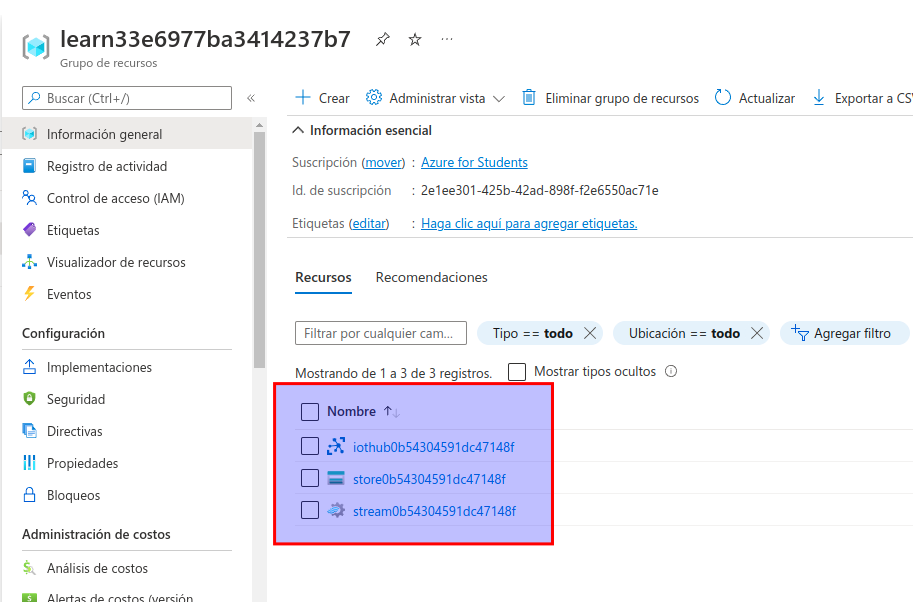
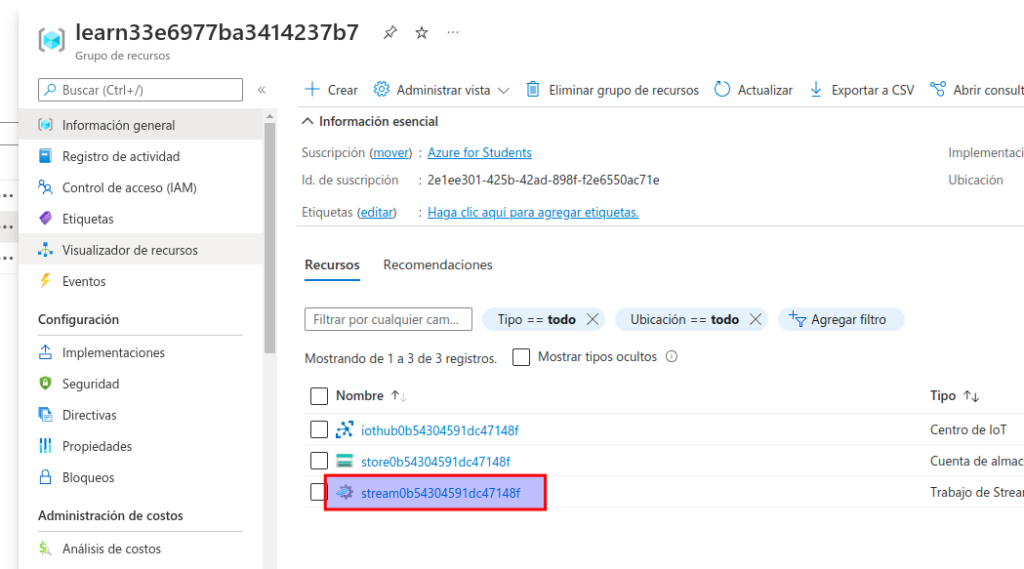
- Seleccione el trabajo de Stream Analytics streamxxxxxxxxxxxxx y vea la información en la página Información general y tenga en cuenta los detalles siguientes:
- El trabajo tiene una entrada llamada iotinput y una salida llamada bloboutput. Hacen referencia a la instancia de IoT Hub y a la cuenta de almacenamiento creada por el script de configuración.
- El trabajo tiene una consulta, que lee datos de la entrada iotinput, los suma al contar el número de mensajes procesados cada 10 segundos y escribe los resultados en la salida bloboutput.

Uso de los recursos para analizar datos de flujos
En la parte superior de la página Información general del trabajo de Stream Analytics, seleccione el botón ▷ Iniciar y, después, en el panel Iniciar trabajo, seleccione Iniciar para iniciar el trabajo.
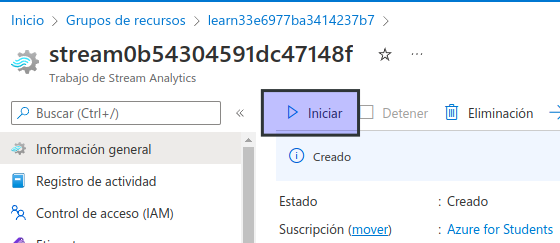
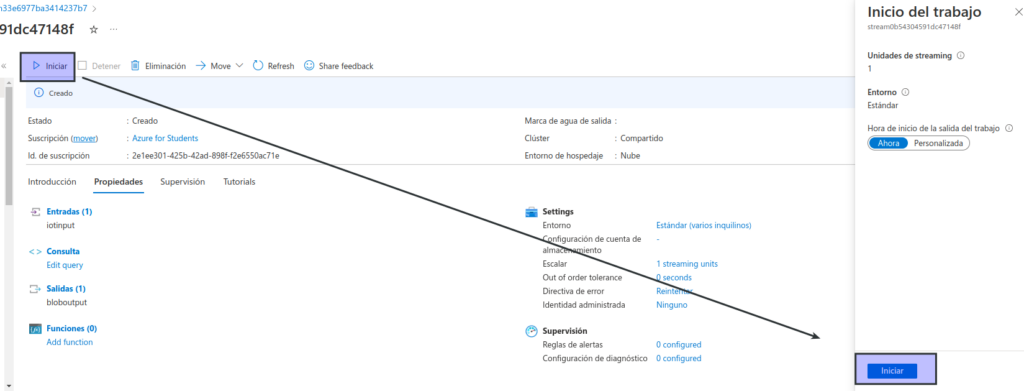
Espere a recibir la notificación de que el trabajo de flujo se inició correctamente.
Vuelva a Azure Cloud Shell y escriba el comando siguiente para simular un dispositivo que envía datos a IoT Hub.
bash iotdevice.sh
Espere a que se inicie la simulación, que se indicará mediante una salida como la siguiente:
Device simulation in progress: 6%|# | 7/120 [00:08<02:21, 1.26s/it]Mientras se ejecuta la simulación, en Azure Portal, vuelva a la página del grupo de recursos learn-xxxxxxxxxxxxxxxxx… y seleccione la cuenta de almacenamiento storexxxxxxxxxxxx.
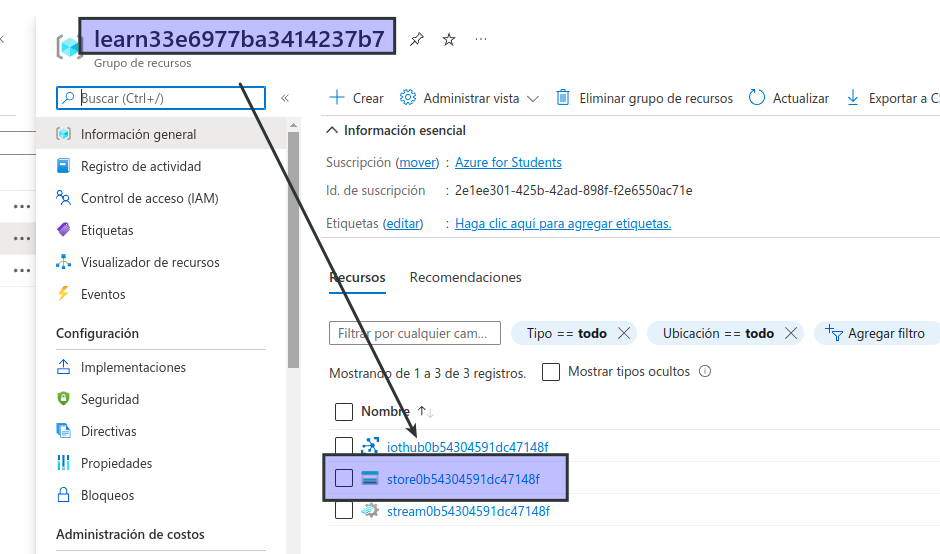
En el panel de la izquierda de la hoja de la cuenta de almacenamiento, seleccione la pestaña Contenedores.
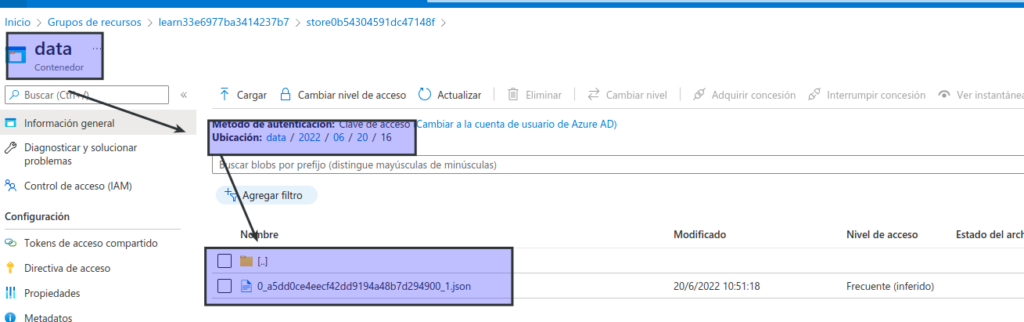
Abra el contenedor de datos.
En el contenedor de datos, navegue por la jerarquía de carpetas, que incluye una carpeta para el año actual, con subcarpetas para el mes, el día y la hora.
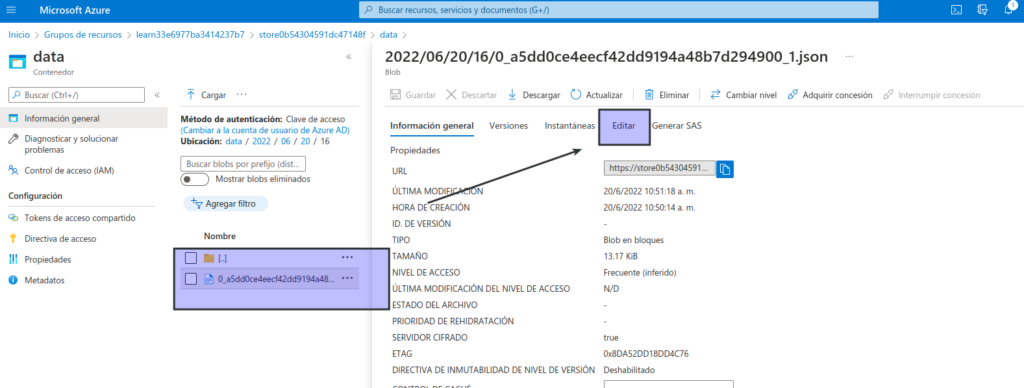
En la carpeta de la hora, seleccione el archivo creado, que debe tener un nombre similar a 0_xxxxxxxxxxxxxxxx.json.
En la página del archivo, seleccione Editar y revise el contenido del archivo, que debe constar de un registro JSON para cada periodo de 10 segundos, que muestra el número de mensajes recibidos de dispositivos IoT, como este:
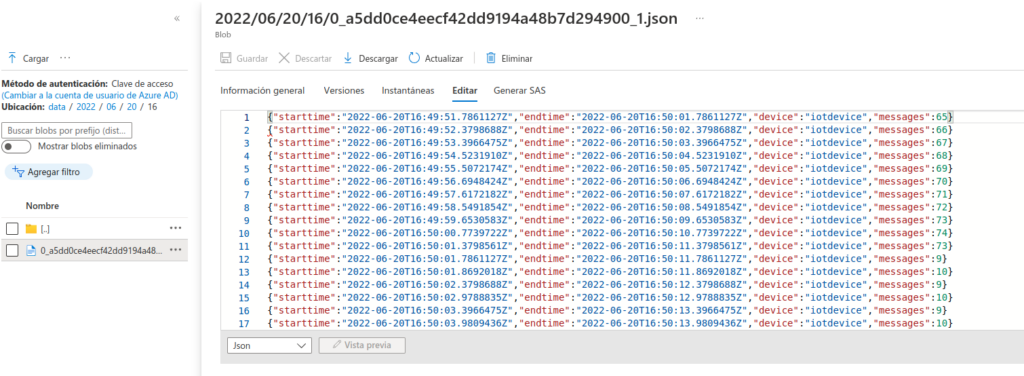
{"starttime":"2021-10-23T01:02:13.2221657Z","endtime":"2021-10-23T01:02:23.2221657Z","device":"iotdevice","messages":2}
{"starttime":"2021-10-23T01:02:14.5366678Z","endtime":"2021-10-23T01:02:24.5366678Z","device":"iotdevice","messages":3}
{"starttime":"2021-10-23T01:02:15.7413754Z","endtime":"2021-10-23T01:02:25.7413754Z","device":"iotdevice","messages":4}
...Use el botón ↻ Actualizar para actualizar el archivo. Tenga en cuenta que los resultados adicionales se escriben en el archivo cuando un trabajo de Stream Analytics procesa los datos del dispositivo en tiempo real a medida que se transmiten desde el dispositivo a IoT Hub.
Vuelva a Azure Cloud Shell y espere a que finalice la simulación del dispositivo (debería ejecutarse durante unos 3 minutos).
De nuevo en Azure Portal, actualice el archivo una vez más para ver el conjunto completo de resultados que se produjeron durante la simulación.
Vuelva al grupo de recursos learn-xxxxxxxxxxxxxxxxx… y vuelva a abrir el trabajo de Stream Analytics streamxxxxxxxxxxxxx.
En la parte superior de la página del trabajo de Stream Analytics, use el botón ⬜ Detener para detener el trabajo; confírmelo cuando se lo solicite.

MCT: Diapositiva: Azure Stream Analitytics
Azure Stream Analytics
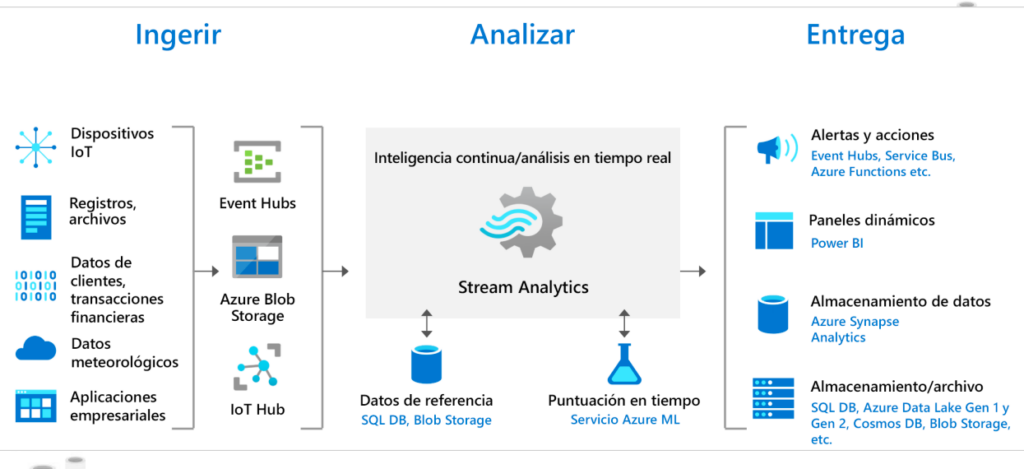
Es un motor de procesamiento de eventos complejo y de análisis en tiempo real que está diseñado para analizar y procesar grandes volúmenes de datos de streaming rápido para varios orígenes de manera simultánea.
Escenarios de aplicación

Ingerir
Es fácil empezar a usar Azure Stream Analytics, es posible conectarse a varios orígenes y receptores, creando una canalización integral.
Stream Analytics puede conectarse directamente a Azure Event Hubs y Azure IoT Hub para la ingesta de datos de streaming, y con el servicio Azure Blob Storage para la ingesta de datos históricos o SQL Database que puede unir a los datos de streaming para realizar operaciones de búsqueda..
Entrega
Stream Analytics puede enrutar la salida del trabajo a muchos sistemas de almacenamiento como Azure Blob Storage, Azure SQL Database, Azure Data Lake Store y Azure Cosmos DB. También se pueden realizar análisis por lotes de los resultados de la transmisión con Azure Synapse Analytics o HDInsight, o bien enviar la salida a otro servicio, como a Event Hubs para su consumo, o a Power BI para la visualización en tiempo real.
Unidad 6: Exploración de Apache Spark en Microsoft Azure
Apache Spark es un marco de procesamiento distribuido para el análisis de datos a gran escala. Puede usar Spark en Microsoft Azure en los siguientes servicios:
- Azure Synapse Analytics
- Azure Databricks
- HDInsight de Azure
Spark se puede usar para ejecutar código (normalmente escrito en Python, Scala o Java) en paralelo en varios nodos de clúster, lo que permite procesar volúmenes de datos muy grandes de forma eficaz. Spark se puede usar tanto para el procesamiento por lotes como para el procesamiento de flujos.
Spark Structured Streaming
Para procesar los datos de flujos en Spark, puede usar la biblioteca de Spark Structured Streaming, que proporciona una interfaz de programación de aplicaciones (API) para ingerir, procesar y generar resultados de flujos de datos perpetuos.
Spark Structured Streaming se compila en una estructura ubicua en Spark denominada dataframe, que encapsula una tabla de datos. Puede usar la API de Spark Structured Streaming para leer datos de un origen de datos en tiempo real, como un centro de Kafka, un almacén de archivos o un puerto de red, a un objeto dataframe «sin límite» que se rellena continuamente con nuevos datos del flujo. A continuación, defina una consulta en el objeto dataframe que selecciona, proyecta o suma los datos, a menudo en ventanas temporales. Los resultados de la consulta generan otro objeto dataframe, que se puede conservar para su análisis o procesamiento posterior.

Structured Streaming de Spark es una excelente opción para el análisis en tiempo real cuando necesita incorporar datos de streaming en un almacén de datos analíticos o un lago de datos basado en Spark.
Nota
Para obtener más información sobre Spark Structured Streaming, consulte la guía de programación de Spark Structured Streaming.
Delta Lake
Delta Lake es una capa de almacenamiento de código abierto que agrega compatibilidad con la coherencia transaccional, el cumplimiento del esquema y otras características comunes de almacenamiento de datos a Data Lake Storage. También unifica el almacenamiento para datos por lotes y de flujos, y se puede usar en Spark para definir tablas relacionales para el procesamiento por lotes y de flujos. Cuando se usa para el procesamiento de flujos, una tabla de Delta Lake se puede usar como un origen de flujos para las consultas en datos en tiempo real o como un receptor en el que se escribe un flujo de datos.
Los entornos de ejecución de Spark de Azure Synapse Analytics y Azure Databricks incluyen compatibilidad con Delta Lake.
El uso de Delta Lake combinado con Structured Streaming de Spark es una solución óptima cuando es necesario abstraer los datos procesados por lotes y flujos en un lago de datos detrás de un esquema relacional para realizar consultas y análisis basados en SQL.
Nota
Para obtener más información sobre Delta Lake, consulte ¿Qué es Delta Lake?
Unidad 7: Ejercicio: procesamiento de datos de flujos con Spark
En este ejercicio, usará Spark Structured Streaming y tablas delta en Azure Synapse Analytics para procesar datos de flujos.
Para completar este ejercicio, necesitará una suscripción a Microsoft Azure. Si aún no tiene una, puede solicitar una prueba gratuita en https://azure.microsoft.com/free. No puede usar una suscripción de espacio aislado de Microsoft Learn para este ejercicio.
Aprovisionar un área de trabajo de Synapse Analytics
Para usar Synapse Analytics, debe aprovisionar un recurso en el área de trabajo de Synapse Analytics en la suscripción de Azure.
- Abra Azure Portal en Azure Portal e inicie sesión con las credenciales asociadas con su suscripción de Azure.
Asegúrese de que está trabajando en el directorio que contiene su propia suscripción, lo que se indica en la parte superior derecha, debajo del identificador de usuario. Si no es así, seleccione el icono de usuario y cambie el directorio. Tenga en cuenta que si anteriormente usó una suscripción de espacio aislado de Microsoft Learn, es posible que el portal haya usado de forma predeterminada el directorio Microsoft Learn Sandbox. Si es así, deberá cambiar a su propio directorio.
En Azure Portal, en la página Inicio, use el icono + Crear para recurso para crear un nuevo recurso.
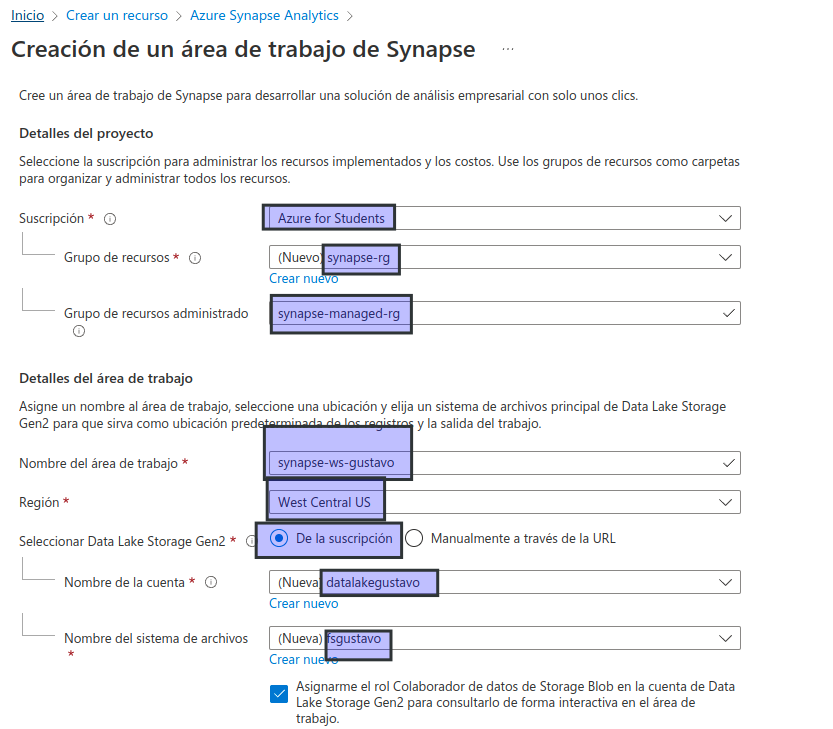
Busque Azure Synapse Analytics, y cree un recurso de Azure Synapse Analytics con la siguiente configuración:
- Suscripción: suscripción de Azure
- Grupo de recursos: cree un grupo de recursos con un nombre apropiado, como «synapse-rg».
- Grupo de recursos administrado: escriba un nombre adecuado, por ejemplo, «synapse-managed-rg».
- Nombre del área de trabajo: escriba un nombre único para el área de trabajo, por ejemplo, «synapse-ws-su_nombre.
- Región: seleccione cualquier región disponible. no West Central US
- Seleccionar Data Lake Storage Gen 2: en la suscripción.
- Nombre de cuenta: cree una cuenta con un nombre único, por ejemplo, «datalakeyour_name».
- Nombre del sistema de archivos: cree un sistema de archivos con un nombre único, por ejemplo, «fsyour_name».

Nota
Un área de trabajo de Synapse Analytics requiere dos grupos de recursos en la suscripción de Azure; uno para los recursos creados explícitamente y otro para los recursos administrados utilizados por el servicio. También requiere una cuenta de almacenamiento de Data Lake en la que almacenar datos, scripts y otros artefactos.
Cuando haya especificado estos detalles, seleccione Revisar y crear y, a continuación, seleccione Crear para crear el área de trabajo.
Espere a que se cree el área de trabajo; puede tardar unos cinco minutos.
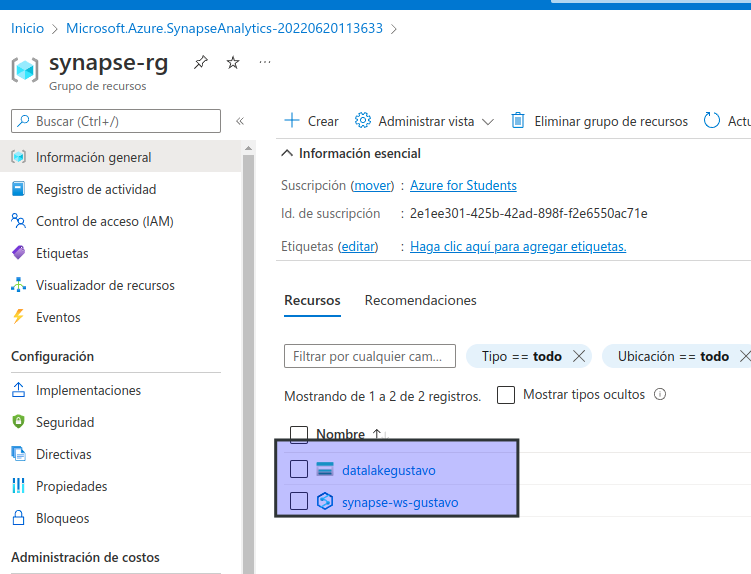
Una vez completada la implementación, vaya al grupo de recursos que se creó y observe que contiene el área de trabajo de Synapse Analytics y una cuenta de almacenamiento de Data Lake.
Seleccione el área de trabajo de Synapse y, en su página Información general, en la tarjeta Abrir Synapse Studio, seleccione Abrir para abrir Synapse Studio en una nueva pestaña del explorador. Synapse Studio es una interfaz basada en web que puede usar para trabajar con el área de trabajo de Synapse Analytics.
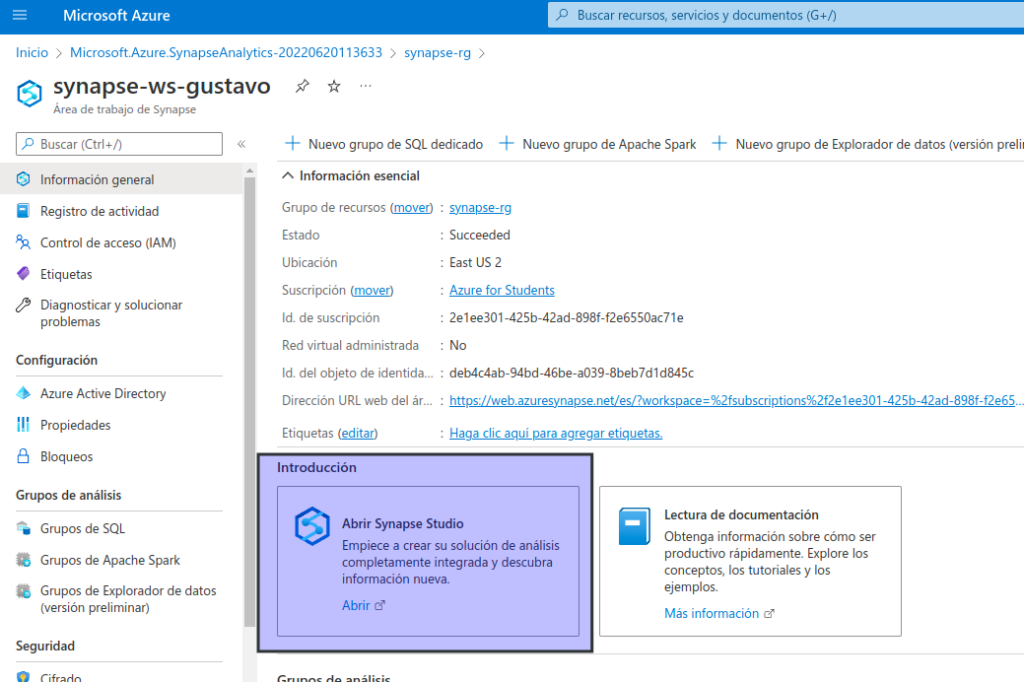
En el lado izquierdo de Synapse Studio, use el icono ›› para expandir el menú; esto muestra las distintas páginas de Synapse Studio que usará para administrar recursos y realizar tareas de análisis de datos, como se muestra aquí:
Crear un grupo de Spark
Para usar Spark para procesar datos de flujos, tiene que agregar un grupo de Spark al área de trabajo de Azure Synapse.
- En Synapse Studio, seleccione la página Administrar.
- Seleccione la pestaña Grupos de Apache Spark y, después, use el icono + Nuevo para crear un grupo de Spark con la configuración siguiente:
- Nombre del grupo de Apache Spark: sparkpool
- Familia de tamaños de nodo: optimizada para memoria
- Tamaño del nodo: pequeño (4 núcleos virtuales/32 GB)
- Escalabilidad automática: habilitada
- Número de nodos: 3—-3
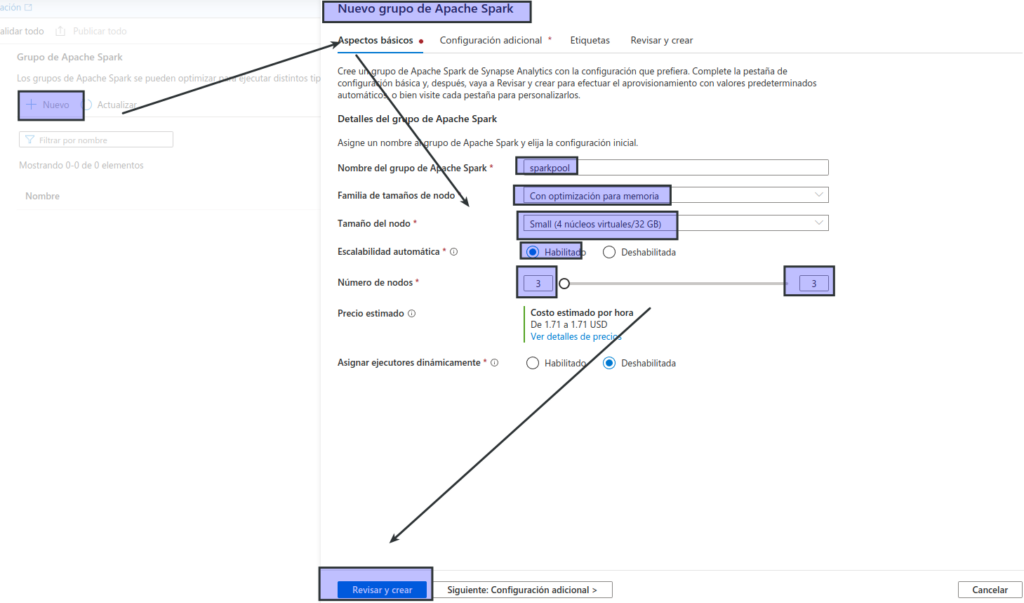

Revise y cree el grupo de Spark y espere a que se implemente (puede tardar unos minutos).
Exploración del procesamiento de flujos
Para explorar el procesamiento de flujos con Spark, usará un cuaderno que contiene código y notas de Python para ayudarlo a llevar a cabo algún procesamiento de flujos básico con Spark Structured Streaming y tablas delta.
- Descargue el cuaderno Structured Streaming and Delta Tables.ipynb en su equipo local (si el cuaderno se abre como archivo de texto en el explorador, guárdelo en una carpeta local; tenga en cuenta que debe guardarlo como Structured Streaming and Delta Tables.ipynb, no como archivo .txt)
- En Synapse Studio, seleccione la página Desarrollar.
- En el menú +, seleccione ↤ Importar y después el archivo Structured Streaming and Delta Tables.ipynb en el equipo local.
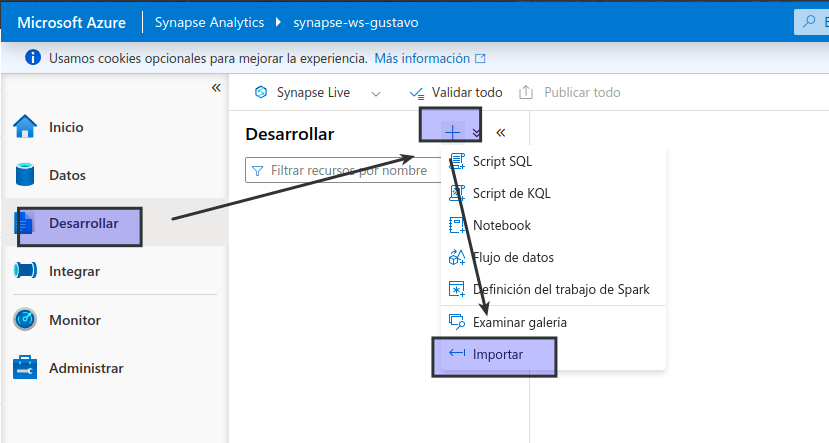
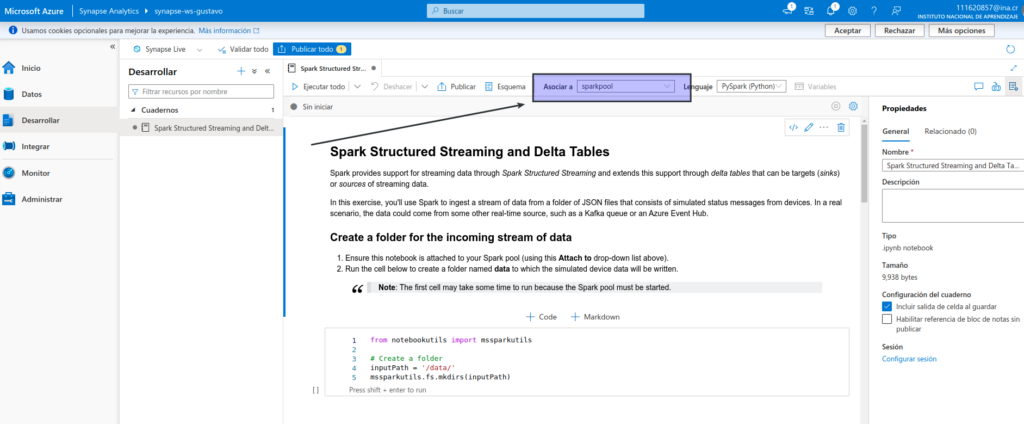
Siga las instrucciones del cuaderno para adjuntarlo al grupo de Spark y ejecutar las celdas de código que contiene para explorar varias maneras de usar Spark para el procesamiento de flujos.
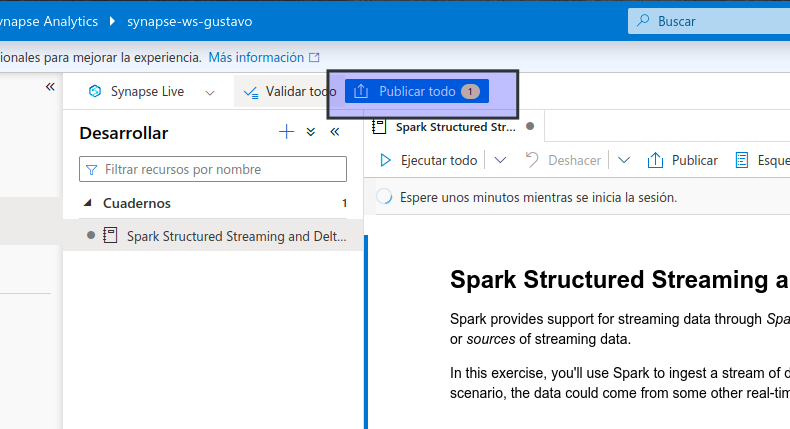
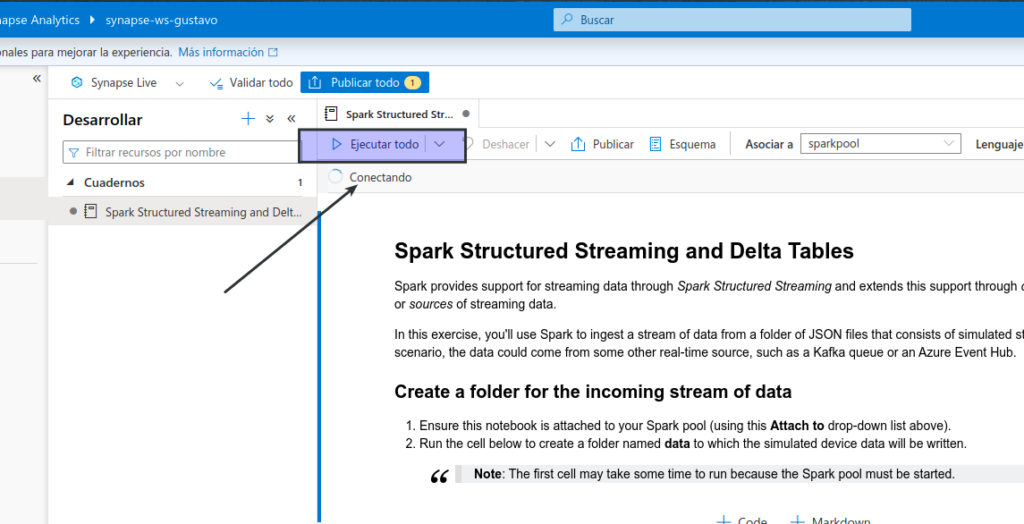

- Tarda un rato